Revolutionizing AI Training With Synthetic Data Pipelines
AI development requires high-quality, diverse datasets, but obtaining them is often costly and time-consuming.

Revolutionizing AI Training With Synthetic Data Pipelines
-
Traditional data collection for AI is time-consuming, costly, and often limited—especially in specialized domains.
-
Synthetic data pipelines offer a scalable alternative by generating high-quality, diverse datasets using advanced language models.
-
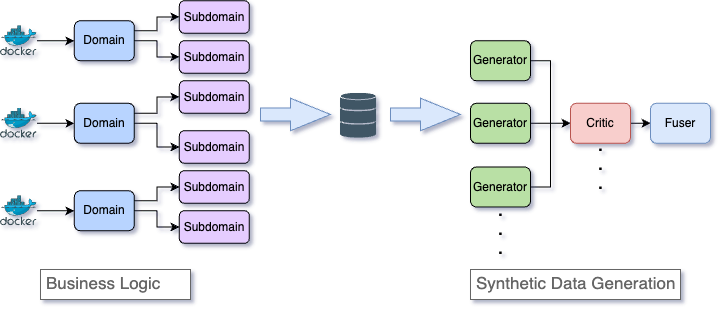
These pipelines combine generators, critics, and fusers to create, evaluate, and refine synthetic data for robust AI training.
-
This blog explores the architecture, engine configurations, and results of our synthetic data pipeline, highlighting its impact across industries like healthcare, finance, and autonomous systems.
Breaking Down Synthetic Data Pipelines: Architecture, Models, And Performance Insights
Pipeline Overview
The synthetic data generation pipeline comprises three main components:
-
Generator Models: These models synthesize data by leveraging predefined parameters to produce outputs that emulate real-world data distributions. They are designed to generate diverse, contextually relevant samples that align with the target data characteristics.
-
Critic Models: These models function as evaluative mechanisms, assessing the quality of the generated data across dimensions such as coherence, diversity, and relevance. Their feedback drives iterative refinement, ensuring the synthetic data meets the requisite standards for downstream AI applications.
-
Fuser Models: These models integrate outputs from multiple generator models, performing optimization and alignment to produce a cohesive and high-quality synthetic dataset. Their role is to ensure the final dataset is both consistent and maximally effective for training and evaluation tasks in AI systems.
-
Parallel Execution for Evaluation Questions: To handle large-scale evaluation datasets efficiently, our pipeline uses parallel execution. This ensures faster response times and better resource utilization—especially important when testing on thousands of synthetic data samples.
Here’s how it works:
# Run on evaluation questions in parallel with concurrent.futures.ThreadPoolExecutor(max_workers=args.parallel) as executor: results = list( tqdm( executor.map( partial( benchmark.get_answer, model=model_config, config=config, samples=args.samples, ), eval_set, ), total=len(eval_set), ) )What this does:
-
Parallel Processing: Distributes evaluation tasks across multiple threads, defined by max_workers (set using args.parallel)
-
Smart Mapping: Uses executor.map() to assign work evenly across the dataset.
-
Progress Visibility: Integrates tqdm to show live progress bars—useful for tracking batch evaluations.
-
Flexible Execution: Uses functools.partial to customize how each evaluation function runs, making the setup more modular and reusable.
-
This methodology ensures scalable and efficient processing of large evaluation datasets while maintaining modularity and transparency.
Together, these components form a cohesive system as shown in Figure 1 that delivers high-quality synthetic datasets, which are essential for training AI models across various domains.
Model Configurations
We use two state-of-the-art language models within different stages of the synthetic data pipeline. Each model has been selected for its strengths in generation, evaluation, or fusion tasks.
Meta-Llama-3.3-70B-Instruct:
-
Role: Generator
-
Key Features: High token capacity (32,768 tokens), optimized for long-form text generation.
-
Performance: Produces diverse, coherent outputs ideal for synthetic text generation.
Qwen2.5-72B-Instruct:
-
Roles: Generator, Critic, and Fuser
-
Key Features: Supports extended token lengths (up to 65,536 tokens), advanced parallel processing capabilities.
-
Performance: Excellent for evaluating generated data and refining results through fusion techniques.
Key Engine Arguments
We use vLLM that is a fast and easy-to-use library for LLM inference and serving. To optimize model performance and resource utilization, several engine arguments are defined, each tailored to enhance specific aspects of the model’s execution:
Model Selection:
-
--model: Defines the base model to be used. For example, meta-llama/Llama-3.3-70B-Instruct for generator tasks and Qwen/Qwen2.5-72B-Instruct for critic tasks.
Token Capacity:
-
--max-model-len: Specifies the maximum sequence length (context length) the model can handle, encompassing both input and output tokens.For example:
-
Generators: Up to 32,768 tokens.
-
Critics: Up to 65,536 tokens for extended context requirements.
-
Performance Optimization:
-
--dtype: Sets the data type used for inference, such as bfloat16, which offers a balance between speed and precision. -
--tensor-parallel-size: Determines the number of GPUs allocated for tensor parallelism, enabling efficient utilization of multiple GPUs (e.g., 2 GPUs for balanced workloads). -
--gpu-memory-utilization: Specifies the percentage of GPU memory reserved for the model (e.g., 0.95 for near-full utilization, ensuring optimal throughput while leaving minimal overhead for other tasks).
Dynamic Batching and Request Handling:
-
--max-num-batched-tokens: Controls the maximum number of tokens processed in a single batch during a model run. For instance, a value of 2,048 ensures a manageable batch size while maintaining efficiency. -
--max-num-seqs: Defines the maximum number of individual requests that can be batched into a single inference task. For example, setting it to 32 allows up to 32 concurrent sequences to be processed together.
Advanced Prefill and Caching Options:
-
--enable-chunked-prefill: Enables chunked preloading of input data, allowing the model to handle large inputs incrementally, reducing latency and improving token generation speed. -
--enable-prefix-caching: Facilitates the reuse of cached prefixes, particularly beneficial for critic models where repetitive context evaluations occur frequently. This reduces redundant computations and improves response times.
Scaling and Customization:
-
--rope-scaling: Modifies the positional encoding mechanism for models requiring extended sequence lengths, using parameters such as the scaling factor and original embedding limit (e.g., {"rope_type":"yarn", "factor":4.0}). -
--kv-cache-dtype: Defines the data type for the key-value cache (e.g., fp8), optimizing memory usage for large context windows. -
--swap-space: Allocates additional disk-based memory for intermediate computations when GPU memory is fully utilized, enhancing robustness in resource-constrained environments.
Task Scheduling:
-
--scheduling-policy: Determines the strategy for batching and prioritizing requests in multi-model and multi-user scenarios.-
Priority-Based Scheduling: Assigns higher priority to critical tasks, ensuring time-sensitive requests are processed promptly.
-
Experimental Results
We assessed the performance of our synthetic data pipeline across several key metrics:
Generation Quality:
-
Metric: Perplexity
-
Result: The Meta-Llama generator achieved a perplexity score of 7.3, indicating fluent and contextually rich outputs.
Critic Feedback Efficiency:
-
Metric: Latency
-
Result: The Qwen critic model processed sequences up to 65,536 tokens with a latency of just 250ms per sequence.
Fusion Coherence:
-
Metric: Consistency across fused datasets
-
Result: The Qwen fuser maintained less than 2
Resource Utilization:
-
GPU Memory: Models consistently utilized 95-96% of GPU memory.
-
Inference Speed: Achieved a 2.8x speedup through chunked prefill and parallel processing.
Our Take
Synthetic data generation pipelines powered by advanced LLMs like Meta-Llama and Qwen are transforming AI model training by addressing data scarcity and enhancing efficiency. These pipelines are particularly impactful in data-constrained industries such as healthcare, finance, and autonomous systems, reducing dependence on manual datasets and accelerating AI development. Expanding their application to new domains promises further advancements across industries.
Key Takeaways
-
Synthetic data generation pipelines are essential for AI systems that require diverse, high-quality datasets.
-
The pipeline consists of generator, critic, and fuser models, each specializing in different tasks to create and optimize synthetic data.
-
Meta-Llama and Qwen models play pivotal roles as generators, critics, and fusers in the pipeline.
-
Engine arguments like token capacity, data type, and parallel processing are crucial for optimizing model performance.
-
Advanced prefill options and task scheduling help improve the efficiency of the synthetic data generation process.
-
Our pipeline achieved impressive results in terms of perplexity, feedback efficiency, and fusion coherence.
-
Resource utilization was efficient, with GPU memory consistently used at 95-96%, and inference speed improved by 1.39x.
-
These synthetic data pipelines can enhance model generalization and accelerate AI development by reducing the need for real-world data collection.
-
Businesses in healthcare, finance, and other domains can leverage these pipelines to create datasets for rare or difficult-to-collect scenarios.
References
-
Daniil Baldouski, Aleksandar Tošić. Grafana plugin for visualising vote-based consensus mechanisms, and network P2P overlay networks, 2 December 2021.
-
Woosuk Kwon, et al., Efficient Memory Management for Large Language Model Serving with PagedAttention, 12 September 2023.
-
Saad-Falcon, J., Lafuente, A. G., Natarajan, S., Maru, N., Todorov, H., Guha, E., ... & Mirhoseini, A.. Archon: An architecture search framework for inference-time techniques, 4 October 2024