TurkColBERT: A Benchmark of Dense and Late-Interaction Models for Turkish Information Retrieval
Neural IR systems have excelled in high-resource languages but remain underexplored for morphologically rich, low-resource ones like Turkish.

TurkColBERT: A Benchmark of Dense and Late-Interaction Models for Turkish Information Retrieval
Neural IR systems have excelled in high-resource languages but remain underexplored for morphologically rich, low-resource ones like Turkish. Existing Turkish IR work mainly uses dense bi-encoders, leaving late-interaction models unexplored.
We introduce TurkColBERT, the first benchmark comparing dense and late-interaction retrievers for Turkish IR.
Our two-stage pipeline fine-tunes English-based (e.g., ettin, bert-hash) and multilingual (mmBERT) encoders on Turkish NLI and STS tasks, then converts them into ColBERT-style retrievers using PyLate, trained on MS MARCO-TR.
Across five Turkish BEIR datasets (SciFact-TR, Arguana-TR, Fiqa-TR, Scidocs-TR, and NFCorpus-TR), we evaluate ten models and find notable efficiency: colbert-hash-nano-tr (1.0 M params) is 600× smaller than turkish-e5-large (600 M) yet retains 71% of its mAP.
Smaller late-interaction models (3–5× fewer parameters) consistently outperform dense ones; ColmmBERT-base-TR achieves up to +13.8% mAP on domain-specific tasks.
For deployment, MUVERA + Rerank proves 3.33× faster than PLAID with +1.7% mAP gain, showing efficient Turkish IR is feasible—ColmmBERT-base-TR reaches query times as low as 0.54 ms.
Bridging the Gap in Turkish Information Retrieval
Neural embedding–based IR systems now power state-of-the-art search and QA pipelines. While English-focused architectures such as ColBERT and SPLADE achieve strong retrieval performance, comparable progress for morphologically rich, low-resource languages like Turkish remains limited. Multilingual encoders such as XLM-RoBERTa, GTE, mmBERT, and MiniLM enable cross-lingual transfer but often fail to capture Turkish morphology and fine-grained token semantics which is key for high-precision retrieval.
Late-interaction methods like ColBERT can model token-level alignment efficiently, yet remain underexplored in Turkish IR. Moreover, strong multilingual and English encoders such as Ettin, BERT-Hash, and mmBERT have not been examined within a Turkish late-interaction setup.
To address this, we propose a two-stage adaptation pipeline. In phase one, Ettin, BERT-Hash, and mmBERT are fine-tuned on Turkish NLI (all-nli-tr) and STS (stsb-tr) datasets to enhance sentence-level understanding. In phase two, these models are transformed into ColBERT-style retrievers using PyLate, trained on ms-marco-tr. We evaluate across five Turkish BEIR datasets. (see Table 1.)
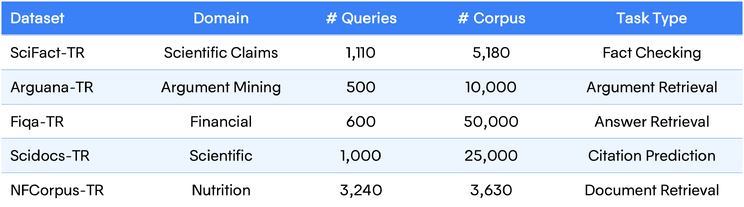
Table 1. Retrieval results across Turkish BEIR benchmark datasets.
Experimental Setup
Environment: All experiments were conducted on Google Colab using NVIDIA L4 GPUs (24 GB memory). This setup ensures reproducibility on a cloud platform that is freely and widely accessible to the research community.
Evaluation Framework: We employed PyLate's evaluation suite to maintain consistent benchmarking across models and to streamline the comparison process.
How We Built TurkColBERT: A Two-Stage Adaptation Pipeline
Stage 1 — Semantic Fine-Tuning
Before transforming encoders into retrieval models, we strengthened their grasp of Turkish semantics through supervised fine-tuning on two complementary tasks: Natural Language Inference (NLI) and Semantic Textual Similarity (STS). Using the Sentence Transformers framework, we trained multilingual (mmBERT), English-based (Ettin), and compact (BERT-Hash) encoders on All-NLI-TR and STSb-TR datasets. This phase improved their sentence-level understanding and produced compact, multi-dimensional embeddings tailored for Turkish. Notably, mmBERT-small achieved strong gains—93% triplet accuracy on NLI and a Spearman correlation of 0.78 on STS—representing significant improvements over pretrained baselines. These semantically enhanced checkpoints then served as the starting point for retrieval-specific adaptation.
Stage 2 — Late-Interaction Adaptation with PyLate
Building on that semantic foundation, we adapted our models into ColBERT-style retrievers using PyLate, training on the MS MARCO-TR dataset. We explored four model families across the efficiency–accuracy spectrum:
- mmBERT (base, small) – robust multilingual encoders
- Ettin (150M, 32M) – encoder–decoder style models with strong cross-lingual transfer
- BERT-Hash (nano, pico, femto) – ultra-lightweight, hash-based variants
- Dense baselines – XLM-RoBERTa and GTE for comparison
PyLate preserves token-level embeddings and applies MaxSim scoring for fine-grained matching. Through triplet-based training on Turkish query–document pairs, we built retrieval models ranging from 2M to 310M parameters, achieving a strong balance between accuracy, size, and inference speed.
Stage 3 — Scalable Deployment with MUVERA
To enable large-scale, low-latency retrieval, we integrated the models with MUVERA (Multi-Vector Retrieval as Sparse Alignment). MUVERA compresses ColBERT's token-level embeddings into compact, fixed-size representations using locality-sensitive hashing and AMS sketches, drastically reducing retrieval latency without major accuracy loss. This allows our Turkish late-interaction models to operate efficiently at different embedding sizes (128D–2048D) and scale to production-ready deployments.
Final Stage — Evaluation on Turkish BEIR Benchmarks
We evaluated (see Table 3.) our models using the BEIR framework across five Turkish datasets: SciFact-TR, Arguana-TR, Fiqa-TR, Scidocs-TR, and NFCorpus-TR (see Table 1.). This allowed a direct comparison between dense and late-interaction architectures ranging from 0.2M to 600M parameters. Late-interaction models consistently achieved higher retrieval accuracy, especially in domain-specific tasks. (see Table 4.)
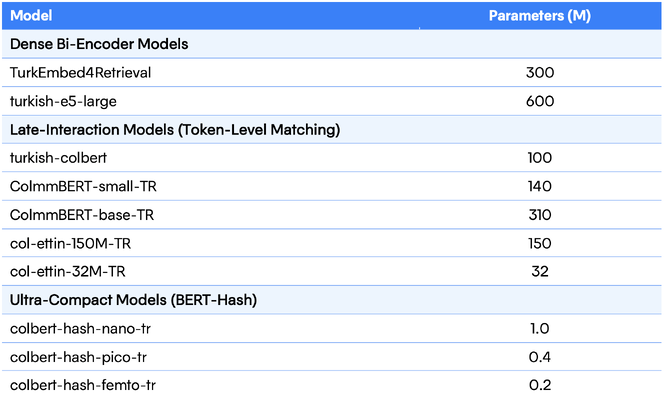
Table 2. Overview of evaluated models categorized by architecture type. Late-interaction variants employ token-level ColBERT representations.
We also tested MUVERA indexing (Fig. 1.) to analyze the balance between speed and quality. Using top models like ColmmBERT-base-TR and col-ettin-encoder-32M-TR, we compared PLAID, MUVERA, and MUVERA + Reranking setups. The MUVERA + Reranking configuration proved 3× faster than PLAID with a slight +1–2% mAP improvement, showing that efficient, low-latency Turkish retrieval is both feasible and scalable.
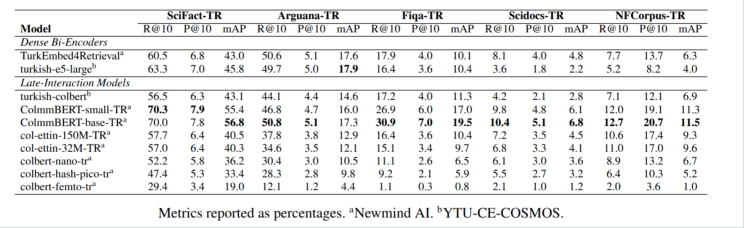
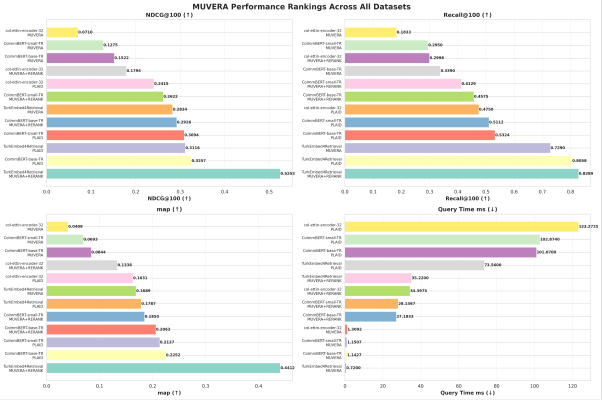
Fig 1. Quality–speed trade-off across MUVERA encoding dimensions (128D to 2048D) on SciFact-TR. Higher dimensions yield faster retrieval but slightly lower NDCG@100. MUVERA+Rerank (128D) recovers near-PLAID quality with 4–5× speedup.
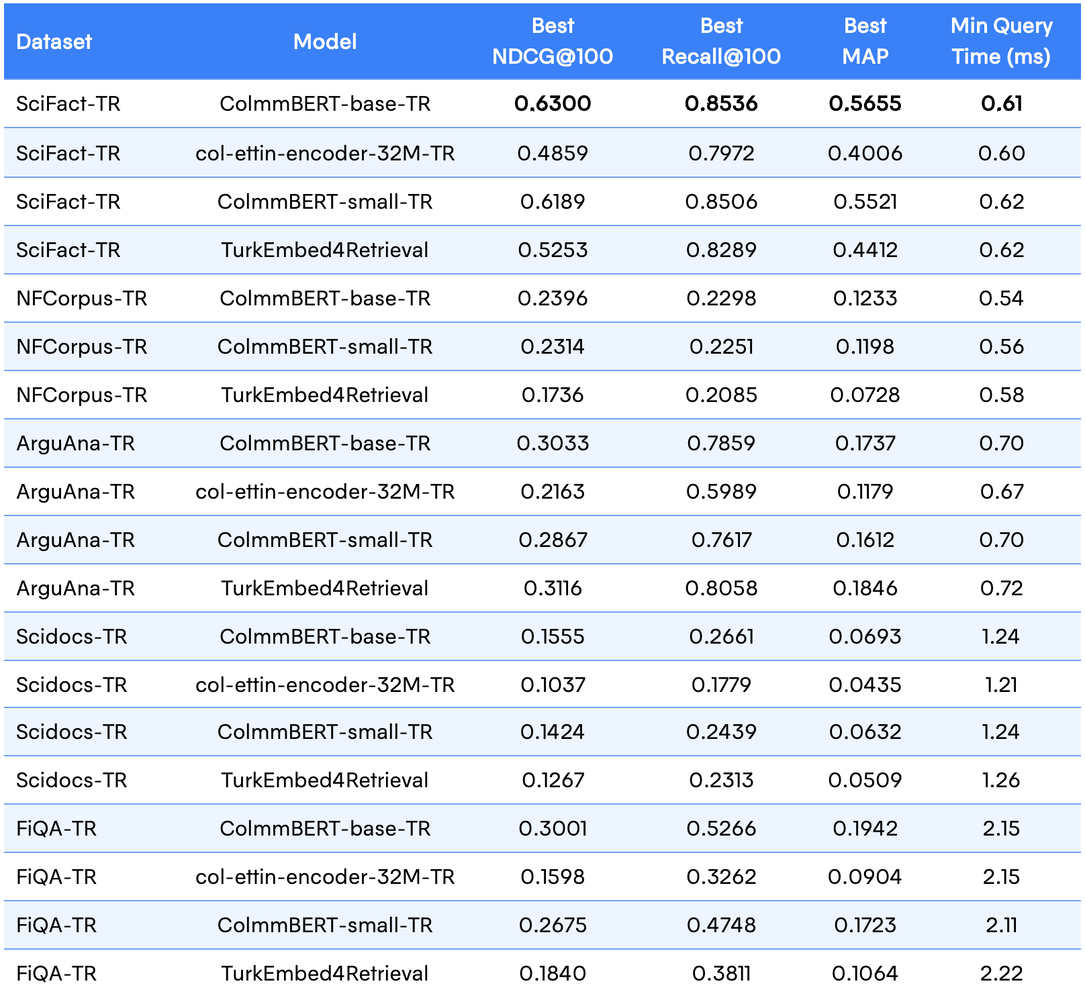
Table 4. Best Performance per Model and Dataset on Turkish BEIR Benchmarks.
Our Mind
With TurkColBERT, we introduced the first benchmark directly comparing dense and late-interaction retrieval models for Turkish information retrieval. Late-interaction models proved more effective overall. Among them, ColmmBERT-base-TR achieved the strongest results—up to +87% mAP improvement on domain-specific tasks like financial QA.
These models also proved remarkably efficient. This demonstrates that scalable, low-latency Turkish retrieval is not only possible but practical for real-time applications.
Looking ahead, we aim to extend TurkColBERT with larger native Turkish corpora, hybrid sparse–dense models, and morphology-aware tokenization. Developing native Turkish IR benchmarks and exploring distillation for ultra-light models remain key next steps toward accessible, high-quality IR for low-resource languages.
Key Takeaways
- First comprehensive Turkish IR benchmark of dense vs. late-interaction across 5 BEIR-style datasets; all checkpoints/configs/scripts publicly released.
- Pipeline: specialize encoders on AllNLI-TR/STSb-TR, convert to ColBERT via PyLate on MS MARCO-TR, and serve efficiently with MUVERA.
- Results: Late-interaction (ColmmBERT) generally best—ColmmBERT-base-TR leads most sets; e5-large wins only on Arguana-TR; small ColmmBERT keeps ~97.5% of base at ~45% compute; hash-nano keeps ≥71% of e5-large at ~600× fewer params.
- Efficiency: MUVERA gives 3–5× faster search than PLAID, with ~0.54–0.72 ms/query (pure) and ~27–35 ms with rerank vs. ~73–124 ms for PLAID, plus slight mAP gains.
- Takeaways/limits: Use late-interaction + MUVERA(+Rerank) for best quality–latency; pick ColmmBERT-small-TR for tight budgets; limits include modest, partly translated corpora and limited model families; future work targets larger native data, morphology-aware tokenization, cross-lingual training, and hybrid systems.
References
- [1] Karpukhin V, Oguz B, Min S, Lewis P, Wu L, Edunov S, et al. Dense passage retrieval for Open-Domain question answering. EMNLP (https://doi.org/10.18653/v1/2020.emnlp-main.550)
- [2] Khattab O, Zaharia M. Colbert: Efficient and effective passage search via contextualized late interaction over bert. InProceedings of the 43rd International ACM SIGIR conference on research and development in Information Retrieval 2020 Jul 25 (pp. 39-48).
- [3] Santhanam K, Khattab O, Shaw P, Chang M-W, Zaharia M. ColBERTv2: Effective and Efficient Retrieval via Lightweight Late Interaction. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (ACL); 2022 May 22–27; Dublin, Ireland (Hybrid). Stroudsburg: Association for Computational Linguistics (ACL); 2022. p. 1604–17.
- [4] Formal T, Piwowarski B, Clinchant S. SPLADE: Sparse lexical and expansion model for first-stage ranking. In: Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval; 2021 Jul 11–15; Virtual Event. New York (NY): Association for Computing Machinery; 2021. p. 2288–92.
- [5] Conneau A, Khandelwal K, Goyal N, Chaudhary V, Wenzek G, Guzmán F, Grave E, Ott M, Zettlemoyer L, Stoyanov V. Unsupervised cross-lingual representation learning at scale. arXiv preprint arXiv:1911.02116. 2019 Nov 5.
- [6] Zhang X, Zhang Y, Long D, Xie W, Dai Z, Tang J, Lin H, Yang B, Xie P, Huang F, Zhang M. mgte: Generalized long-context text representation and reranking models for multilingual text retrieval. arXiv preprint arXiv:2407.19669. 2024 Jul 29.
- [7] Marone M, Weller O, Fleshman W, Yang E, Lawrie D, Van Durme B. mmbert: A modern multilingual encoder with annealed language learning. arXiv preprint arXiv:2509.06888. 2025 Sep 8.
- [8] Wang W, Wei F, Dong L, Bao H, Yang N, Zhou M. MiniLM: Deep Self-Attention Distillation for Task-Agnostic Compression of Pre-Trained Transformers. Adv Neural Inf Process Syst. 2020;33:14934-14948.
- [9] Toprak Kesgin H, Yuce MK, Amasyali MF. Developing and evaluating tiny to medium-sized turkish bert models. arXiv:2307.15278
- [10] Weller O, Ricci K, Marone M, Chaffin A, Lawrie D, Van Durme B. Seq vs seq: An open suite of paired encoders and decoders. arXiv preprint arXiv:2507.11412. 2025 Jul 15.
- [11] Mezzetti D. Training Tiny Language Models with Token Hashing. NeuML (Medium) (https://neuml.hashnode.dev/train-a-language-model-from-scratch). 2025
- [12] Budur E, Özçelik R, Güngör T, Potts C. Data and representation for Turkish natural language inference. arXiv preprint arXiv:2004.14963. 2020 Apr 30.
- [13] Beken Fikri F, Oflazer K, Yanikoglu B. Semantic Similarity Based Evaluation for Abstractive News Summarization. In: Proceedings of the 1st Workshop on Natural Language Generation, Evaluation, and Metrics (GEM 2021); 2021 Nov 10; Punta Cana, Dominican Republic. Stroudsburg: Association for Computational Linguistics (ACL); 2021. p. 24–33.
- [14] Chaffin A, Sourty R. Pylate: Flexible training and retrieval for late interaction models. arXiv preprint arXiv:2508.03555. 2025 Aug 5.
- [15] Parsak A, et al. MS MARCO-TR:A Turkish Adaptation of the MS MARCO Passage Ranking Dataset. Hugging Face Dataset (https://huggingface.co/datasets/parsak/msmarco-tr). 2024
- [16] Saoud A. scifact-tr: Turkish translation of SciFact for fact-checking & retrieval. Hugging Face Datasets Repository (https://huggingface.co/datasets/AbdulkaderSaoud/scifact-tr). 2024
- [17] trmteb. arguana-tr: Turkish version of the ArguAna argument retrieval dataset. Hugging Face dataset (https://huggingface.co/datasets/trmteb/arguana-tr). 2025
- [18] trmteb. fiqa-tr: Turkish financial question answering dataset. Hugging Face dataset (https://huggingface.co/datasets/trmteb/fiqa-tr). 2025
- [19] trmteb. scidocs-tr: Turkish version of the SciDocs dataset as part of the TR-MTEB benchmark. Hugging Face dataset (https://huggingface.co/datasets/trmteb/scidocs-tr). 2025
- [20] trmteb. nfcorpus-tr: Turkish translation of the NF Corpus for nutrition-focused retrieval. Hugging Face dataset (https://huggingface.co/datasets/trmteb/nfcorpus-tr). 2025
- [21] Reimers N, Gurevych I. Sentence-BERT:Sentence Embeddings using Siamese BERT-Networks. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing (EMNLP);2019 Nov 3–7;Hong Kong, China. Stroudsburg:Association for Computational Linguistics (ACL);2019. p. 3982–92.
- [22] Jayaram R, Dhulipala L, Hadian M, Lee JD, Mirrokni V. MUVERA: Multi-Vector Retrieval via Fixed Dimensional Encoding. Advances in Neural Information Processing Systems. 2024 Dec 16;37:101042-73.
- [23] Ezerceli Ö, Gümüşçekiçci G, Erkoç T, Özenç B. TurkEmbed4Retrieval: Turkish Embedding Model for Retrieval Task. In 2025 33rd Signal Processing and Communications Applications Conference (SIU) 2025 Jun 25 (pp. 1-4). IEEE.
- [24] Santhanam K, Khattab O, Potts C, Zaharia M. PLAID: An efficient engine for late interaction retrieval. In: Proceedings of the 31st ACM International Conference on Information & Knowledge Management (CIKM); 2022 Oct 17–21; Atlanta, Georgia, USA. New York: Association for Computing Machinery (ACM); 2022. p. 1747–56.
- [25] Thakur N, Reimers N, Rückle A, Srivastava A, Gurevych I. BEIR:A heterogenous benchmark for zero-shot evaluation of information retrieval models. arXiv:2104.08663