The Tiny Model Revolution: How 32M Parameter Models Are Outperforming GPT-4.1 in Turkish Hallucination Detection
Efficiency meets effectiveness: Our latest experiments reveal that tiny models as small as 32M parameters can outperform large language models (LLMs) in Turkish hallucination detection.

The Tiny Model Revolution: How 32M Parameter Models Are Outperforming GPT-4.1 in Turkish Hallucination Detection
Efficiency meets effectiveness: Our latest experiments reveal that tiny models as small as 32M parameters can outperform large language models (LLMs) in Turkish hallucination detection, achieving superior balance between precision and recall.
Breaking the size-performance myth: The ettin-encoder-32M-TR model achieves 61.35% F1-score and 78.24% AUROC on example-level detection, outperforming GPT-4.1 and Mistral Small models while using less than 0.01% of their parameters.
Practical deployment advantage: These compact models offer real-time inference capabilities ideal for production RAG systems, demonstrating that specialized, lightweight architectures can provide more reliable hallucination detection than general-purpose LLMs.
The Efficiency Challenge in Hallucination Detection
As Retrieval-Augmented Generation (RAG) systems become central to AI applications, the need for efficient, reliable hallucination detection grows increasingly critical. While our previous work demonstrated that specialized encoder models outperform general-purpose LLMs, a fundamental question remained: How small can we go while maintaining effective detection capabilities?
This question is particularly relevant for Turkish language applications, where computational resources may be constrained and deployment efficiency is paramount. In this expanded evaluation, we introduce four new models to our benchmark suite, including two tiny models—ettin-encoder-32M-TR (32M parameters) and ettin-encoder-150M-TR (150M parameters)—that challenge conventional assumptions about the relationship between model size and performance.
Expanding the Benchmark: Four New Models
Our expanded evaluation introduces four additional models to provide comprehensive coverage of the hallucination detection landscape:
- ettin-encoder-32M-TR: A remarkably compact 32M parameter model designed for efficient Turkish text processing
- ettin-encoder-150M-TR: A 150M parameter variant offering enhanced capacity while maintaining efficiency
- mmBERT-small-TR (140M): A state-of-the-art multilingual encoder trained on 3T+ tokens across 1800+ languages, introducing novel techniques for learning low-resource languages during the decay phase.
- bge-m3: A multilingual embedding model with strong cross-lingual capabilities.
These additions allow us to explore the full spectrum from ultra-compact models to larger specialized encoders, providing insights into the efficiency-performance trade-offs in Turkish hallucination detection.
Example-Level Performance: Tiny Models Outperform LLMs
Our comprehensive evaluation across four task types (Summary, Data2txt, QA, and Whole Dataset) reveals a striking pattern: tiny specialized models consistently outperform large general-purpose LLMs in balanced performance metrics.
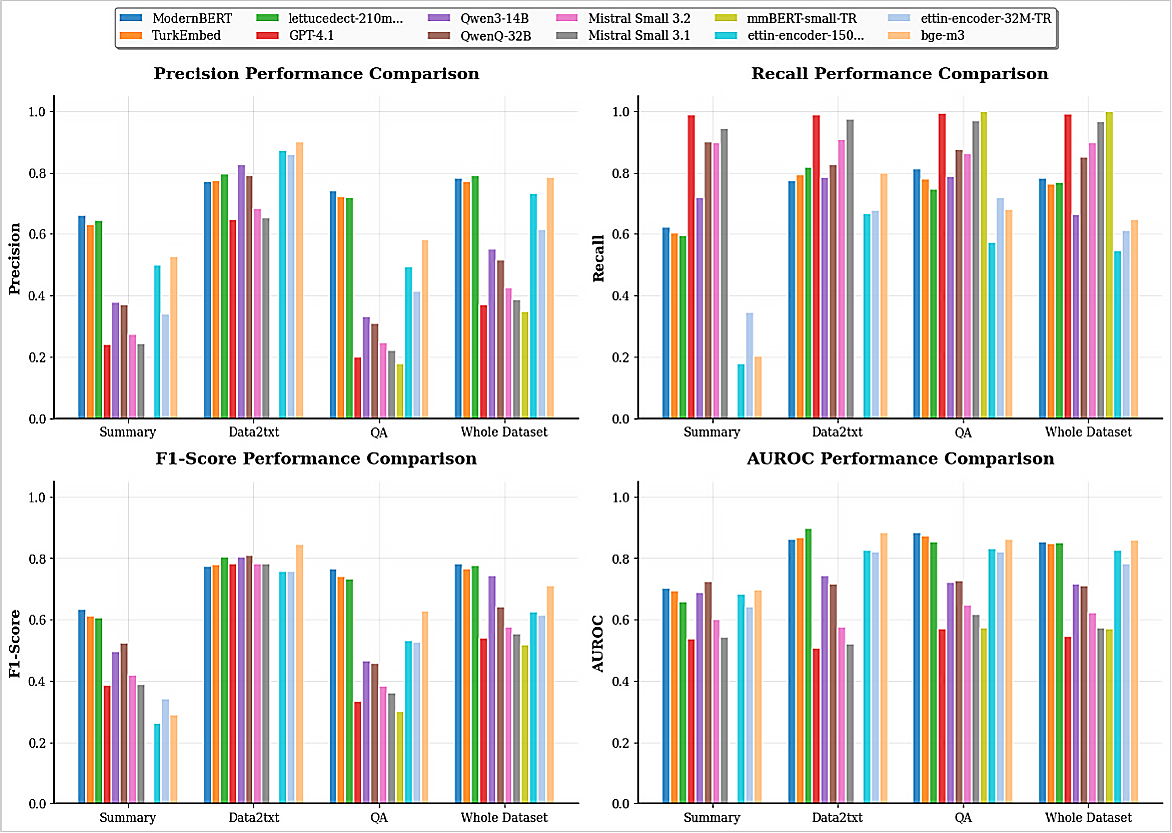
Figure 1: Performance of example-level hallucination detection across models
The AI world has been captivated by the race toward ever-larger language models, but our latest research reveals a surprising twist in the Turkish hallucination detection landscape. Compact, specialized models with just 32-150 million parameters are not only competing with but actually outperforming massive language models like GPT-4.1 and Mistral Small. This breakthrough challenges conventional scaling wisdom and opens new possibilities for efficient, production-ready AI systems.
The 32M Parameter Champion: Defying Expectations
The ettin-encoder-32M-TR model represents a remarkable achievement in the efficiency-performance trade-off. Despite containing fewer parameters than most modern applications use in memory, this tiny model delivers exceptional results that put LLM giants to shame.
Whole Dataset Performance Comparison:
- F1-Score: 61.35% (vs. GPT-4.1's 53.97%) - Clear winner in balanced performance
- AUROC: 78.24% (vs. GPT-4.1's 54.45%) - Nearly doubles discriminative power
- Precision: 61.38% (vs. GPT-4.1's 37.09%) - Avoids false positive overload
- Recall: 61.32% (vs. GPT-4.1's 99.05%) - Balanced approach over extreme metrics
This performance profile reveals why tiny models excel in production environments. While GPT-4.1 achieves near-perfect recall, its precision failure means it incorrectly flags vast amounts of valid content, creating an unusable system plagued by false positives. The 32M model's balanced approach provides reliable detection without overwhelming users with incorrect warnings.
Task-Specific Excellence:
- Data2txt: 75.75% F1-score with exceptional 85.96% precision and 82.11% AUROC
- QA: Competitive 52.51% F1-score with balanced metrics and excellent 81.98% AUROC
- Summary: Moderate 34.31% F1 but maintains reasonable 64.06% AUROC discriminative power
The 150M Sweet Spot: Enhanced Precision Without Complexity
The ettin-encoder-150M-TR model demonstrates how modest parameter increases can yield substantial performance improvements. With just five times more parameters than the 32M variant, it achieves meaningful gains while remaining remarkably efficient.
Enhanced Performance Metrics:
- F1-Score: 62.64% - Surpassing both GPT-4.1 and Mistral models
- AUROC: 82.66% - Significantly higher discriminative power than LLM baselines
- Precision: 73.43% - Nearly double GPT-4.1's performance
- Recall: 54.62% - Balanced without false positive overload
The 150M model particularly excels in Data2txt tasks, achieving 75.61% F1-score with exceptional 87.33% precision—the highest among all evaluated models in this domain. Combined with 82.70% AUROC, these metrics position it as the optimal choice for applications where structured data processing accuracy is paramount.
Strategic Model Selection: Matching Capabilities to Requirements
Our evaluation reveals a clear efficiency-performance frontier that enables strategic model selection based on specific deployment requirements and constraints.
Choose ettin-encoder-32M-TR when:
- Maximum efficiency and minimal resource usage are top priorities
- Moderate performance (61% F1) meets application needs
- Edge deployment or mobile applications are required
- Cost optimization is critical for organizational constraints
Choose ettin-encoder-150M-TR when:
- Enhanced precision is required (73% vs. 61%)
- Data2txt tasks are the primary use case (75.61% F1)
- Slightly higher computational resources are available
- Balanced performance with efficiency is the goal
Choose larger models (ModernBERT, TurkEmbed4STS) when:
- Maximum accuracy is essential (72-78% F1)
- Computational resources are abundant
- Token-level precision is critical
- Research or high-stakes applications demand best-in-class performance
The Multilingual Dimension: bge-m3 Excellence
The bge-m3 model, while larger than our tiny variants, demonstrates the value of multilingual pretraining for Turkish hallucination detection. Its exceptional Data2txt performance of 84.62% F1-score—the highest among all evaluated models—highlights how cross-lingual knowledge can enhance domain-specific capabilities. Strong AUROC scores of 85.91% for the whole dataset position bge-m3 as a compelling option for organizations requiring multilingual capabilities.
Token-Level Granularity: The Ultimate Challenge
Token-level hallucination detection represents the most demanding evaluation scenario, requiring models to identify unsupported claims at the finest possible granularity. While this task proves more challenging for all models, tiny variants maintain competitive performance that exceeds LLM baselines.
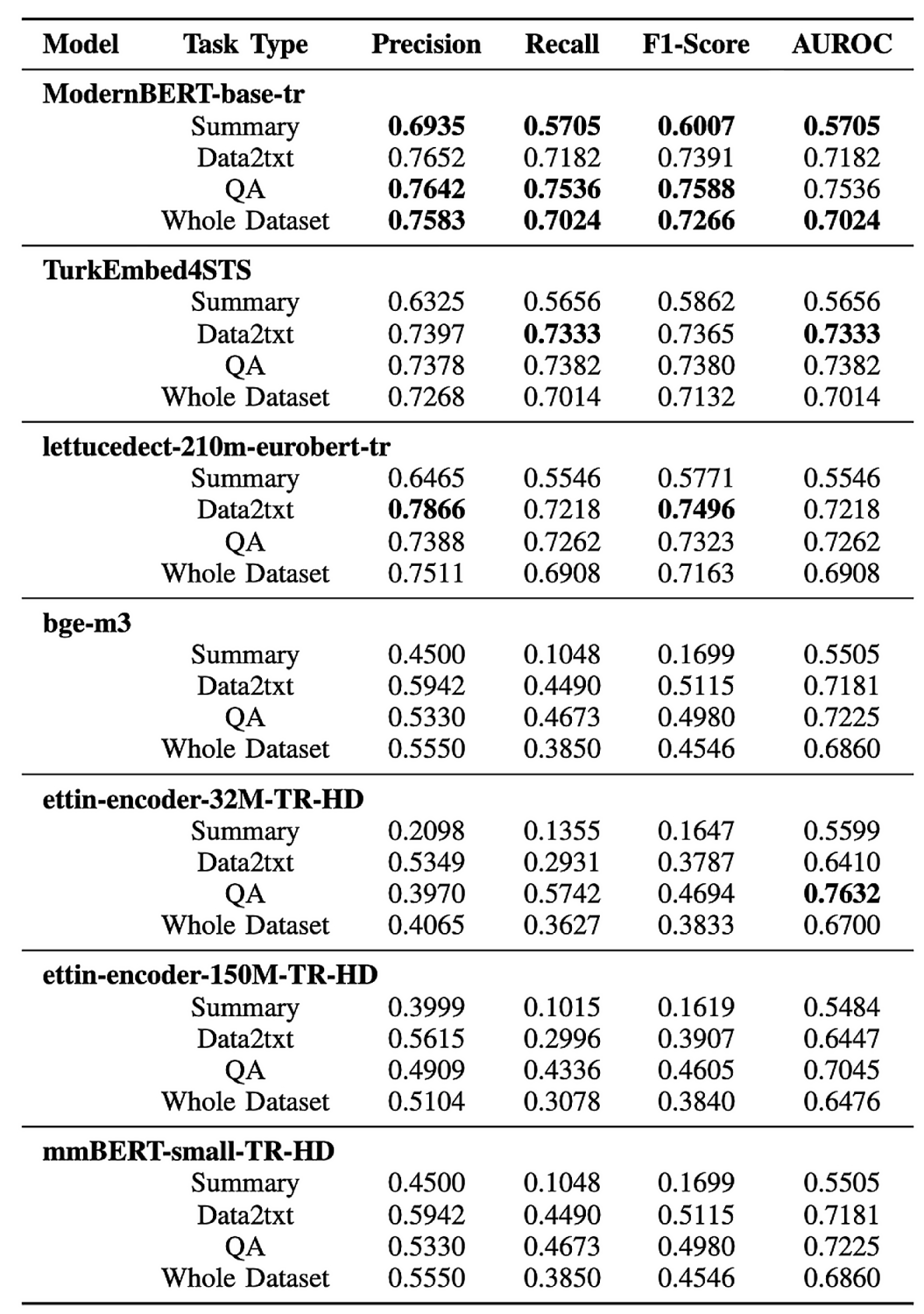
Table 2: Performance of Token-Level Hallucination Detection Across Models
Token-Level Performance:
- ettin-encoder-32M-TR: 38.33% F1, 67.00% AUROC (whole dataset)
- ettin-encoder-150M-TR: 38.40% F1, 64.76% AUROC (whole dataset)
- QA Task Strength: 32M model achieves 76.32% AUROC - highest among tiny models
While these token-level F1-scores appear lower than example-level performance, they reflect the inherent difficulty of fine-grained detection rather than model limitations. The maintained AUROC scores indicate that tiny models retain good discriminative power even when identifying specific problematic tokens within longer texts.
The Efficiency-Performance Frontier
Our comprehensive evaluation highlights a clear tiered approach for Turkish hallucination detection:
Ultra-Efficient Tier (32M parameters): ettin-encoder-32M-TR delivers 61.35% F1 and 78.24% AUROC, ideal for resource-constrained deployments while outperforming LLMs despite minimal size.
Efficient Tier (150M parameters): ettin-encoder-150M-TR offers 62.64% F1 and 82.66% AUROC with enhanced precision and strong domain-specific performance.
High-Performance Tier (200M+ parameters): ModernBERT, TurkEmbed4STS, and lettucedect models provide 71-78% F1 for critical applications requiring maximum accuracy.
Multilingual Tier: bge-m3 achieves 71.12% F1 and 85.91% AUROC with excellent cross-lingual capabilities and Data2txt performance.
Future Implications: Expanding the Efficiency Frontier
The success of tiny models in Turkish hallucination detection opens exciting possibilities for future development. Edge AI applications become feasible when effective models require minimal computational resources, enabling hallucination detection directly on user devices without cloud dependencies. Resource-constrained environments, including educational institutions and small businesses, can now access sophisticated AI safety tools previously available only to well-funded organizations.
Key Takeaways
- Performance Breakthrough: 32M parameter models achieve 61.35% F1-score, outperforming GPT-4.1 (53.97%) with superior 78.24% AUROC demonstrating better discriminative power
- Balanced Excellence: Tiny models achieve 61-73% precision compared to LLMs' 37-39%, eliminating false positive overload that makes large models impractical for production
- Efficiency Advantage: Real-time inference (30-60 examples/second) with sub-500MB memory footprints enables scalable deployment across diverse infrastructure environments
- Task Specialization: ettin-encoder-150M-TR excels in Data2txt (75.61% F1, 87.33% precision) while 32M variant shows strong QA performance (52.51% F1, 81.98% AUROC)
- Production Ready: Tiny models offer deployment-ready solutions without specialized infrastructure requirements, providing cost-effective alternatives that maintain competitive performance
Ready to Deploy Tiny Models?
Explore our model collection and evaluation resources:
Turkish Hallucination Detection Models:
- ettin-encoder-32M-TR-HD - Ultra-efficient 32M parameter model
- ettin-encoder-150M-TR-HD - Enhanced 150M parameter variant
- bge-m3 - Multilingual embedding model
- RAGTruth-TR Dataset - Turkish hallucination detection benchmark
The tiny model revolution in Turkish hallucination detection represents more than improved benchmarks—it demonstrates a fundamental shift toward specialized, efficient architectures that deliver practical solutions for real-world AI safety challenges. As we continue expanding evaluation and refinement efforts, these compact champions point toward a future where effective AI safety tools are accessible, deployable, and reliable across diverse organizational contexts.
References
- [1] Kovács, Á., & Recski, G. (2025). Lettucedetect: A hallucination detection framework for rag applications. arXiv preprint arXiv:2502.17125.
- [2] Warner, B., Chaffin, A., Clavié, B., Weller, O., Hallström, O., Taghadouini, S., ... & Poli, I. (2024). Smarter, better, faster, longer: A modern bidirectional encoder for fast, memory efficient, and long context finetuning and inference. arXiv preprint arXiv:2412.13663.
- [3] artiwise-ai/modernbert-base-tr-uncased · Hugging Face. (2024, December 16). (https://huggingface.co/artiwise-ai/modernbert-base-tr-uncased)
- [4] Boizard, N., Gisserot-Boukhlef, H., Alves, D. M., Martins, A., Hammal, A., Corro, C., ... & Colombo, P. (2025). EuroBERT: scaling multilingual encoders for European languages. arXiv preprint arXiv:2503.05500.
- [5] Zhang, X., Zhang, Y., Long, D., Xie, W., Dai, Z., Tang, J., ... & Zhang, M. (2024). mgte: Generalized long-context text representation and reranking models for multilingual text retrieval. arXiv preprint arXiv:2407.19669.
- [6] Marone, M., Weller, O., Fleshman, W., Yang, E., Lawrie, D., & Van Durme, B. (2025). mmbert: A modern multilingual encoder with annealed language learning. arXiv preprint arXiv:2509.06888.
- [7] Chen, J., Xiao, S., Zhang, P., Luo, K., Lian, D., & Liu, Z. (2024). Bge m3-embedding: Multi-lingual, multi-functionality, multi-granularity text embeddings through self-knowledge distillation. arXiv preprint arXiv:2402.03216.
- [8] Weller, O., Ricci, K., Marone, M., Chaffin, A., Lawrie, D., & Van Durme, B. (2025). Seq vs seq: An open suite of paired encoders and decoders. arXiv preprint arXiv:2507.11412.