Guided Decoding and Its Critical Role in Retrieval-Augmented Generation (RAG)
The demand for Large Language Models (LLMs) has surged across industries in recent years.
.jpg)
Guided Decoding and Its Critical Role in Retrieval-Augmented Generation (RAG)
-
The demand for Large Language Models (LLMs) has surged across industries in recent years.
-
Ensuring structured responses that align with expectations remains a major challenge in utilizing LLMs.
-
Guided encoding backends help shape outputs to precisely match their intended use cases.
-
This blog explores how guided decoding impacts RAG systems in multi-turn prompting setups.
Guided Decoding Impact on RAG Performance
Experiment Setup
The experiment consisted of four main stages. In the first stage, we used Retrieval-Augmented Generation (RAG) to extract context related to each query, enhancing the user prompt with accurate and relevant information. In the second stage, we defined key components such as instructions, prompts, and response formats to ensure the outputs were structured and reliable.
The third stage involved configuring the Guided Encoding Backend, which was critical. At this stage, we adjusted the extra_body argument, switching it sequentially to analyze how different configurations impacted the LLM's response. We compared three guided decoding backends—Outlines, XGrammar, and LM-Format-Enforcer—under identical conditions to evaluate their effectiveness.
Outlines utilized a finite-state machine (FSM) approach, providing a guided decoding method that constrains the output of LLMs during generation rather than relying on post-processing. It ensured that every token aligns with the defined structure by leveraging specialized decoding strategies. The speed of structured generation in Outlines comes from the equivalence between regular expressions and finite-state machines.
XGrammar leveraged a pushdown automaton approach, supporting general context-free grammar to enable a wide range of structured outputs. It integrated seamlessly into various environments and frameworks, co-designed with the LLM inference engine to allow zero-overhead structured generation, making it a powerful solution for enhancing LLM inference performance.
LM-Format-Enforcer strictly enforced output format character-by-character by filtering the tokens the language model can generate at every timestep, ensuring that the output format is respected while minimizing limitations on the language model.
In the fourth stage, we hypothesized that LLMs improve over multiple interactions, so we repeated the experiment in multi-turn settings (one-shot and two-shot scenarios) to observe how the model adapted over consecutive exchanges.
The responses were evaluated using a comprehensive metric designed to measure the model's performance based on the documents provided and how well it addressed the user query.
Results and Analysis
We present result graphs that illustrate the differences among three backends for guided decoding.
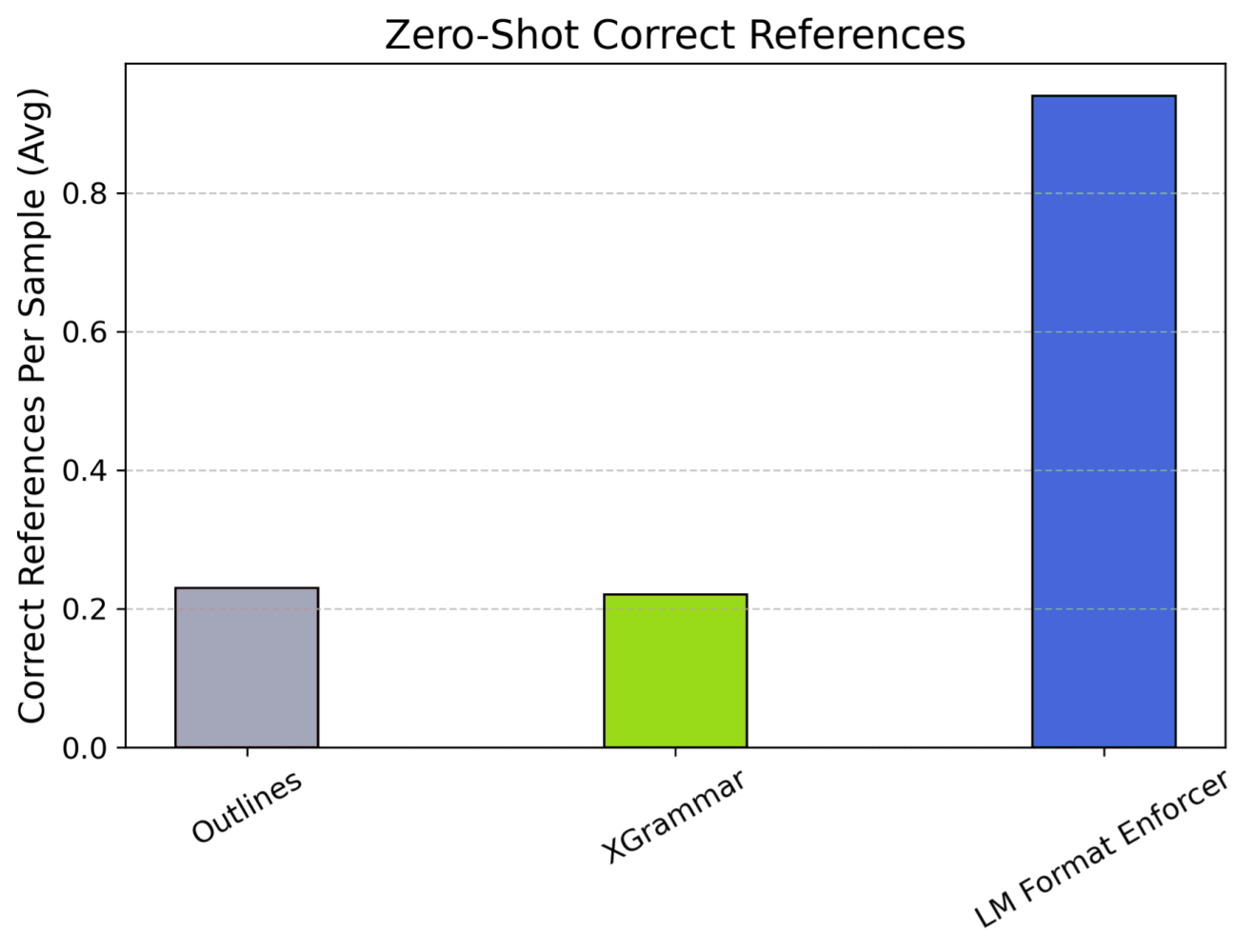
Zero-Shot: Outlines and Xgrammar achieved success rates around 20-25%, highlighting their dependence on clear guidance. LM-Format-Enforcer achieved around 94% success but often compromised content quality.
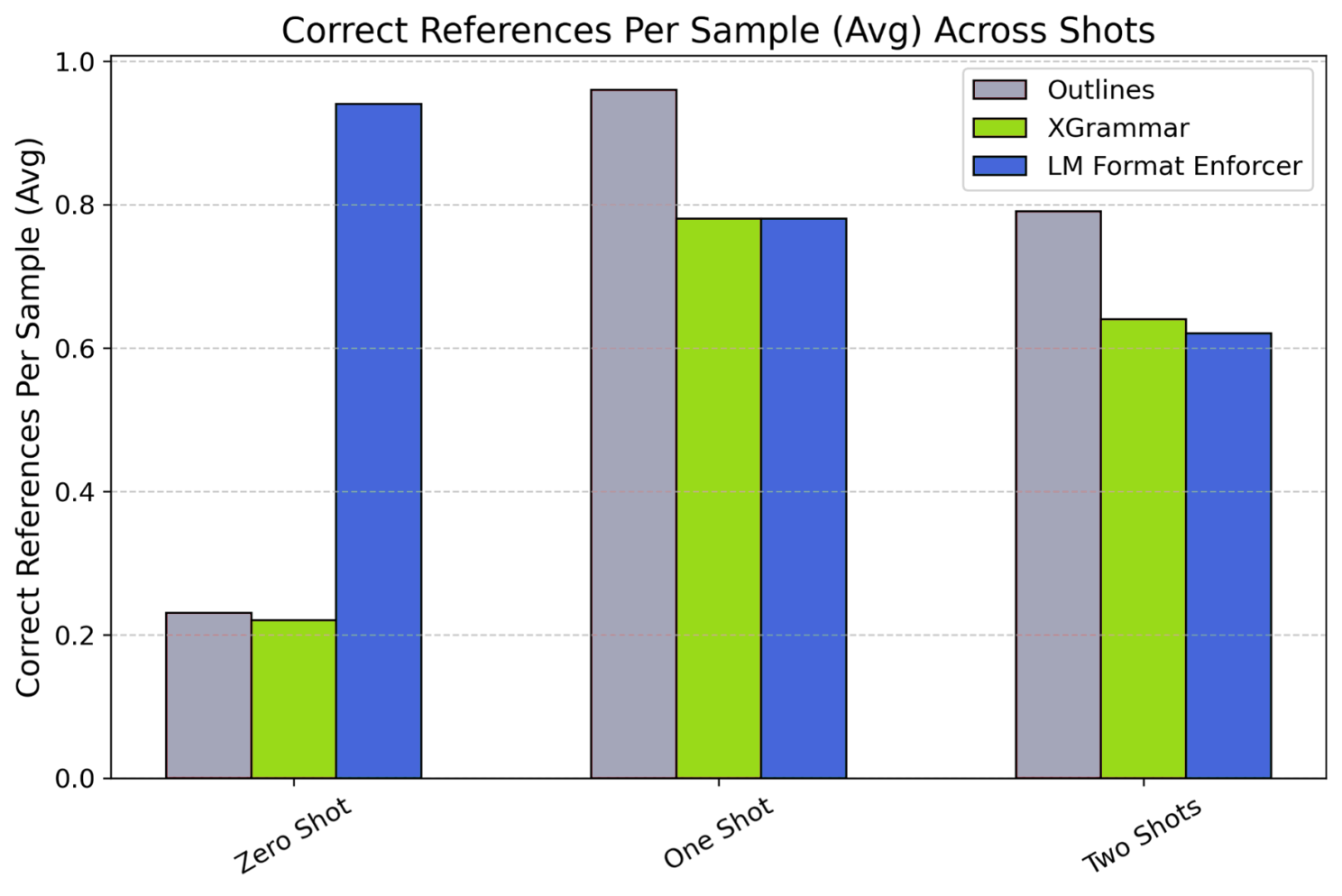
One-Shot and Two-Shot: Outlines significantly improved performance to get (~93%) for one shot setup and (~97%) for Two shot setup on other side XGrammar improved to about 60-78% success and LM-Format-Enforcer’s success 78-93%.
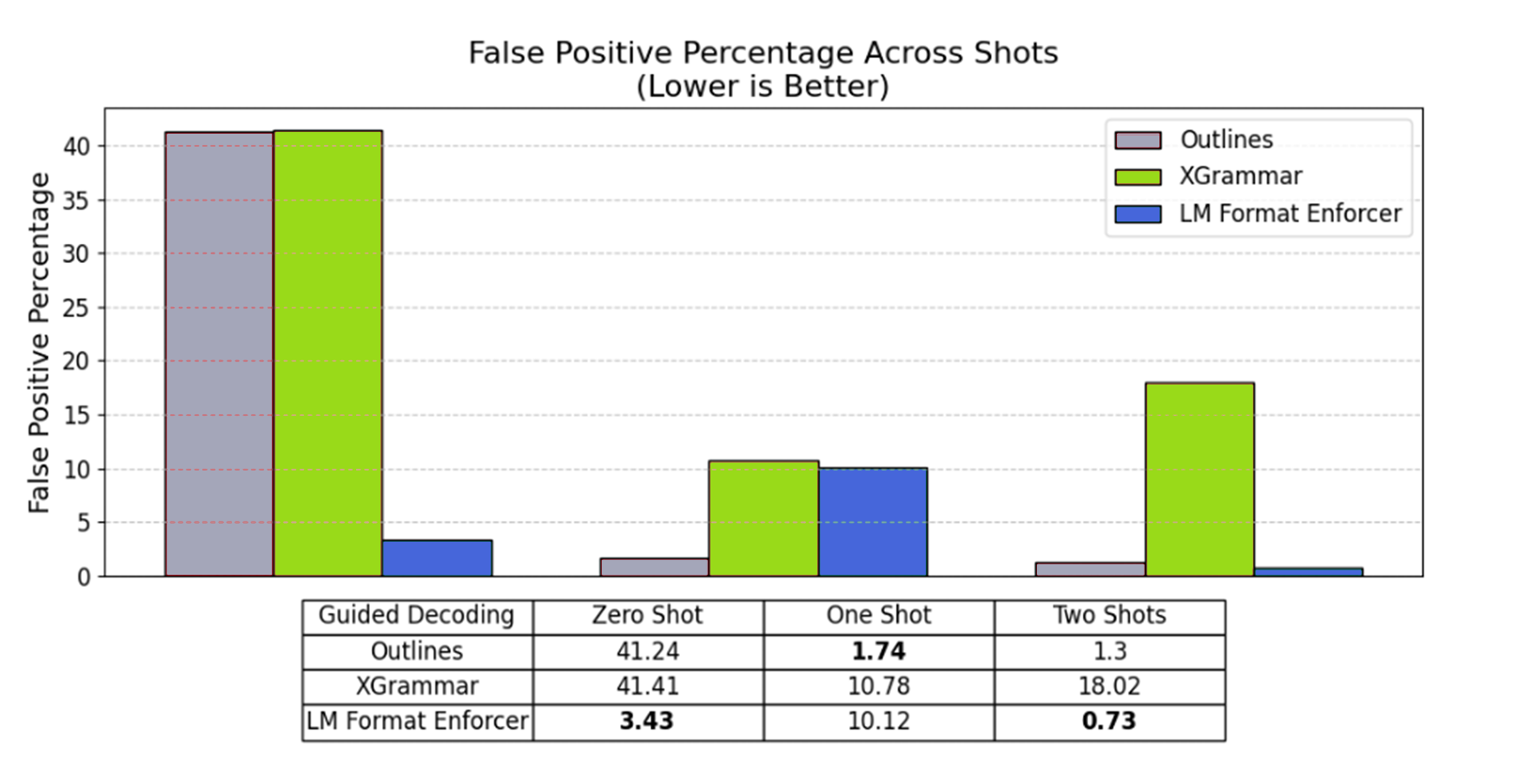
Hallucination Rate Comparison: Both Outlines and XGrammar have high hallucinations (100.0% and 99.3% respectively), indicating these methods frequently produce incorrect results when used in zero-shot. LM Format Enforcer significantly reduces hallucination to just 8.9%, making it highly effective in zero-shot scenarios. In one-shot, hallucination decreases where Outlines has the lowest hallucination rate (1.8%), outperforming the other backends. XGrammar and LM Format Enforcer both have slightly higher hallucination at 10.7%. In two-shots, further improvement is noticeable, where hallucination becoming minimal. Outlines achieves the lowest hallucination rate (0.4%), nearly eliminating errors. LM Format Enforcer also performs exceptionally well (0.7%). XGrammar improves to 7.1%, but remains notably higher than the other backends.
Backend Performance Analysis: Outlines and XGrammar consistently produced higher quality outputs compared to LM-Format-Enforcer.outlines demonstrated significantly better runtime performance compared to the other backends.
Discussion
Few-Shot Prompting Importance: One-shot prompting greatly enhanced reliability by demonstrating desired output structure explicitly. Two-shot prompting had diminishing returns and introduced complexity that LM-Format-Enforcer could not handle.
Guided Decoding Backend Selection: Outlines offered optimal balance of flexibility and structure enforcement. XGrammar provided comparable accuracy and significantly better performance. LM-Format-Enforcer enforced format strictly, compromising usability and robustness in complex scenarios.
Model Capability and Prompting Synergy: Guided decoding complements few-shot prompting, ensuring structured and factual outputs. Optimal RAG performance achieved through the combined use of examples and guided decoding.
Our Mind
At NewMind AI, we recognize guided decoding as an essential strategy for reliable, structured LLM deployments. Our experiences have demonstrated significant improvements in LLM accuracy and usability when guided decoding and structured prompting are combined effectively. The adoption of robust guided decoding practices can generate substantial business value, particularly in sectors such as legal, medical, and technical support, where precise information delivery is critical. NewMind AI continues to optimize decoding strategies to maximize both accuracy and performance.
Key Takeaways
-
Retrieval-Augmented Generation greatly enhances LLM factual accuracy.
-
Structured outputs are essential for practical LLM applications.
-
Guided decoding backends (Outlines, XGrammar, LM-Format-Enforcer) significantly impact RAG performance.
-
Zero-shot setups benefit from strict format enforcers but at the cost of quality.
-
One-shot prompting drastically increases success rates across backends.
-
Two-shot prompting can introduce complexity, reducing performance for rigid decoders.
-
Outlines backend balances flexibility with strict format adherence effectively.
-
XGrammar provides superior performance and throughput under real-world conditions.
-
LM-Format-Enforcer's strictness makes it unreliable in complex prompting scenarios.
-
Combining structured prompting with guided decoding maximizes RAG system success.
References
-
Fast JSON Decoding for Local LLMs with Compressed Finite State Machine | LMSYS Org. (2024, February 5). https://lmsys.org/blog/2024-02-05-compressed-fsm/
-
Reserved, V. T. a. R. (n.d.). VLLM blog. vLLM Blog. https://blog.vllm.ai/
-
Structured Outputs — VLLM. (n.d.). https://docs.vllm.ai/en/latest/features/structured_outputs.html
-
Dong, Y., Ruan, C. F., Cai, Y., Lai, R., Xu, Z., Zhao, Y., & Chen, T. (2024). Xgrammar: Flexible and efficient structured generation engine for large language models. arXiv preprint arXiv:2411.15100.
-
Dottxt-Ai. (n.d.). GitHub - dottxt-ai/outlines: Structured Text Generation. GitHub. https://github.com/dottxt-ai/outlines
-
Mlc-Ai. (n.d.). GitHub - mlc-ai/xgrammar: Fast, Flexible and Portable Structured Generation. GitHub. https://github.com/mlc-ai/xgrammar
-
Noamgat. (n.d.). GitHub - noamgat/lm-format-enforcer: Enforce the output format (JSON Schema, Regex etc) of a language model. GitHub. https://github.com/noamgat/lm-format-enforcer