Qdrant 1.13.x: Unlocking GPU-Accelerated Vector Search for AI Systems
As AI technologies like LLMs, semantic search, and anomaly detection grow, scalable and high-performance vector databases are becoming essential infrastructure components.

Qdrant 1.13.x: Unlocking GPU-Accelerated Vector Search for AI Systems
-
As AI technologies like LLMs, semantic search, and anomaly detection grow, scalable and high-performance vector databases are becoming essential infrastructure components.
-
Qdrant, a Rust-based open-source vector search engine, is favored for its speed, scalability, and developer-friendly API-first architecture.
-
The latest version introduces GPU-accelerated indexing and search, delivering performance gains of up to 10x compared to CPU-based setups.
-
Qdrant 1.13.x brings architectural enhancements, optimized GPU usage, and practical improvements for real-world deployment scenarios.
Deconstructing Qdrant 1.13.x: Architecture, Acceleration, and Use Case Insights
System Overview
Version 1.13.x introduces several architectural improvements. It now features GPU-accelerated indexing and search, with support for IVF-PQ and Flat indexes on NVIDIA GPUs. This update makes Flat indexing—once computationally expensive—feasible via GPU parallelism, achieving millisecond-level latency in high-dimensional vector searches.
A custom storage engine has been developed to replace RocksDB, which helps eliminate latency spikes caused by background compactions. This new backend uses a block-based architecture with bitmask and region-layered structures to enhance data throughput.
The update also includes a hybrid resource allocation strategy, allowing GPU resources to be assigned per collection. This facilitates prioritization of critical data and enables cost-effective deployment in mixed CPU-GPU environments.
Finally, containerized deployment is now streamlined with Docker images that offer native GPU support, ensuring full compatibility with the NVIDIA Container Toolkit and CI/CD pipelines for seamless integration.
Technical Highlights and Engine Configuration
GPU support in Qdrant is currently limited to IVF-PQ and Flat indexing. While HNSW indexing can use the GPU, search operations for HNSW remain CPU-bound.
To take advantage of GPU acceleration, a CUDA-compatible GPU (such as an NVIDIA RTX 30xx series or newer) with at least 8GB of VRAM is required. It's important to note that GPU acceleration is only available through Docker deployments—native binaries do not yet support this feature.
In terms of performance, small queries may still perform better with CPU-only indexing due to the overhead of transferring data to the GPU. However, GPU acceleration provides significant benefits in large-scale, high-throughput workloads.
Configuration Options Overview:
Table 1: Qdrant GPU Configuration Options
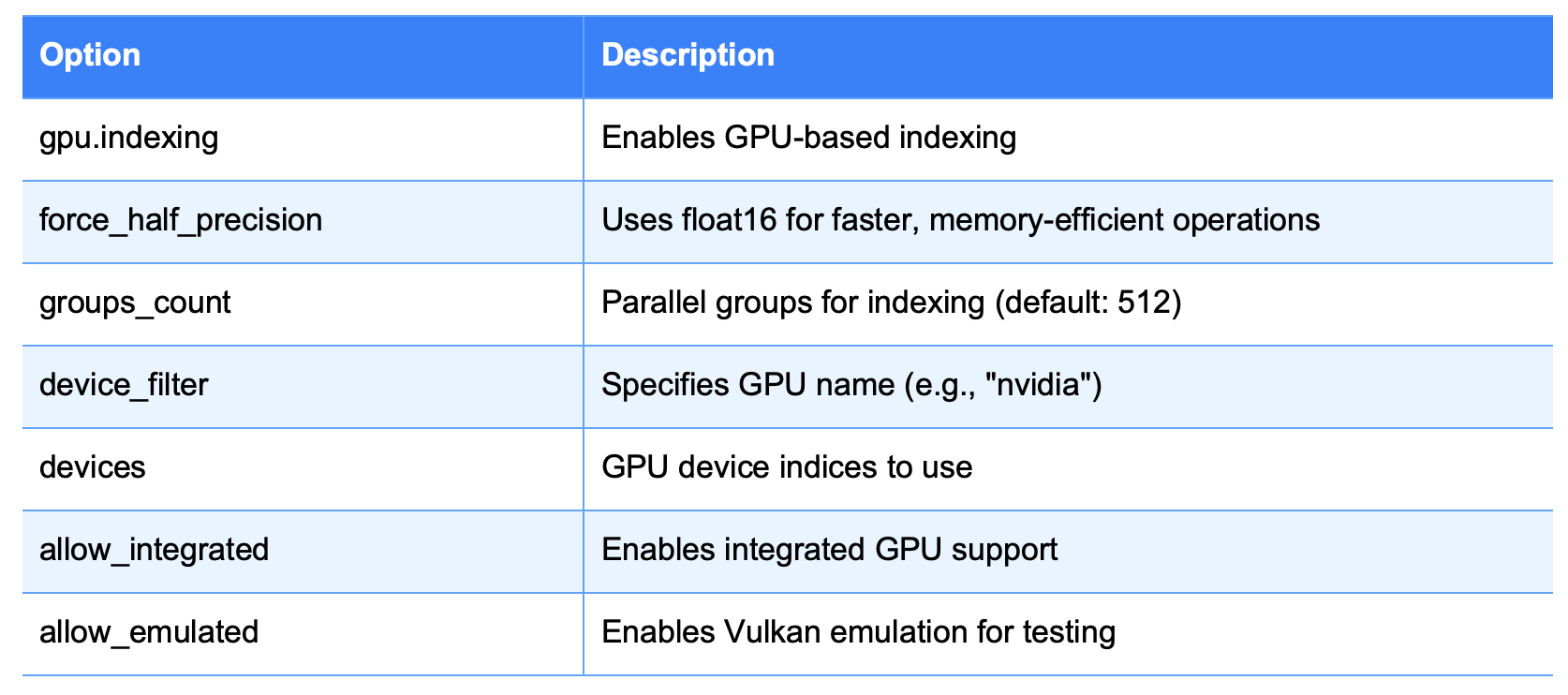
Deployment Example:

Experimental Results
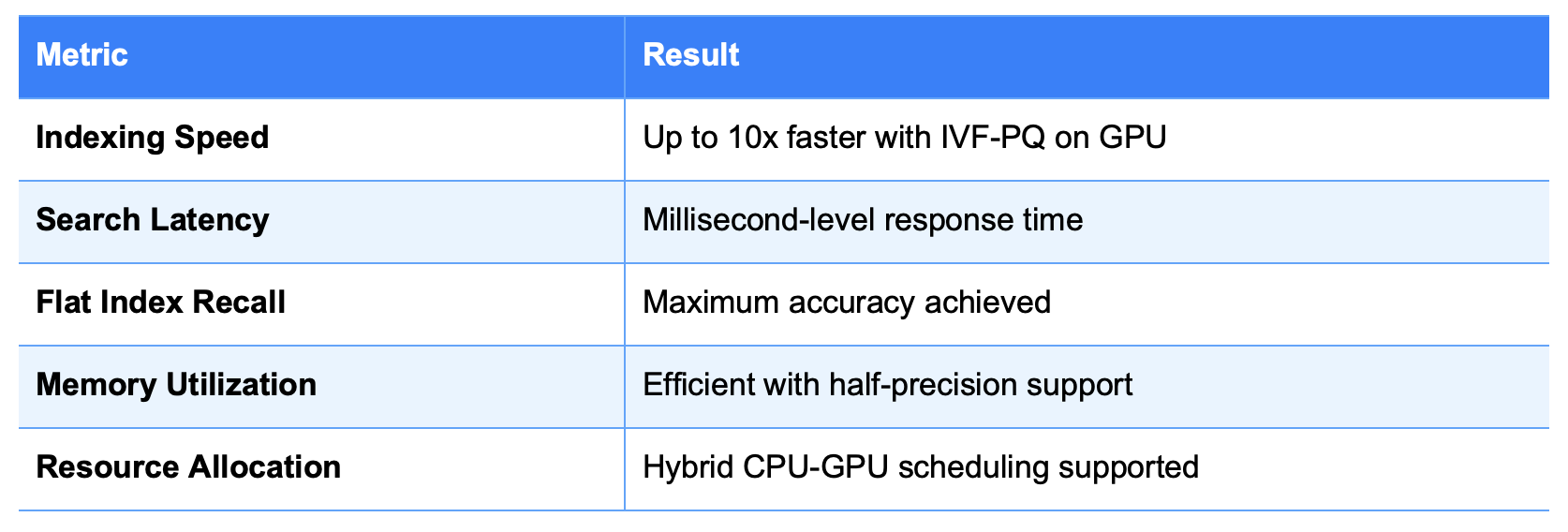
Qdrant’s GPU enhancements yield strong gains across key performance dimensions:
Table 2: Experimental Performance Metrics
Real-World Applications
Table 3: Real-World Use Cases for Qdrant GPU Acceleration
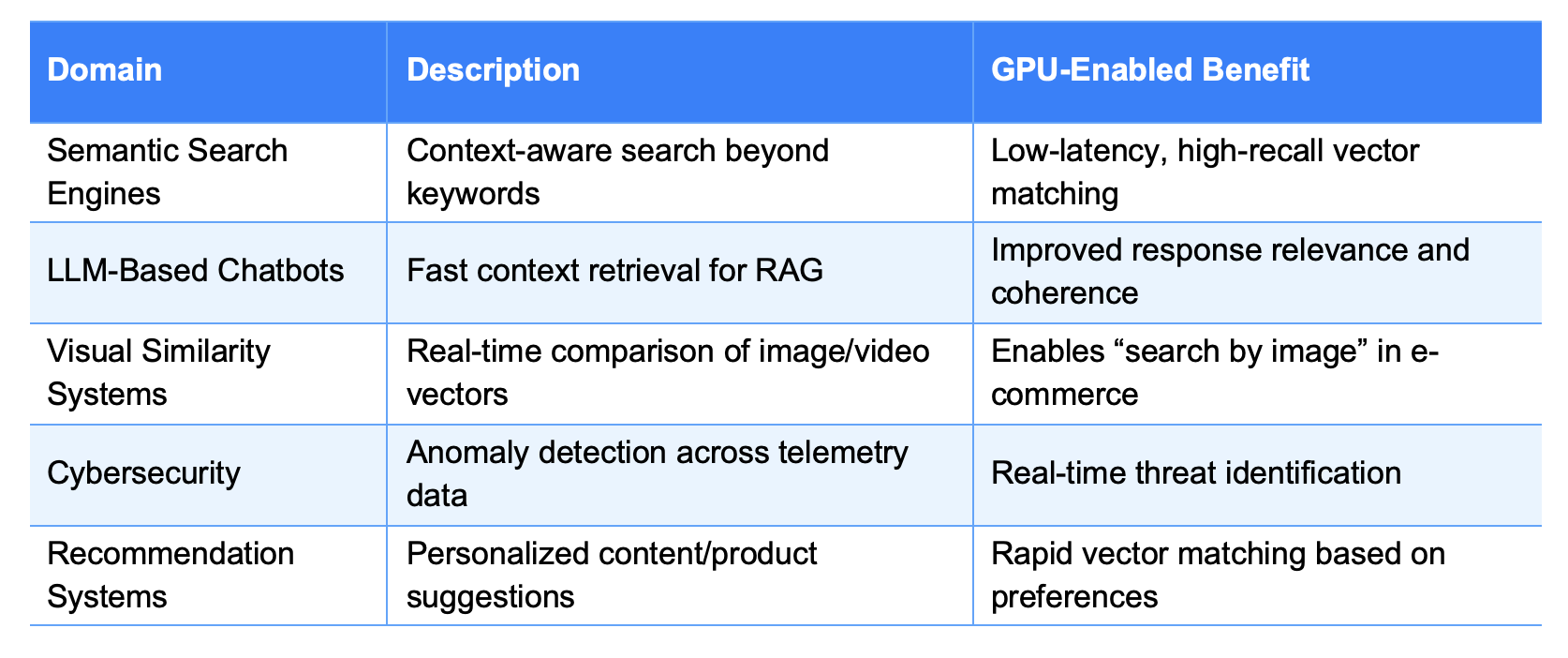
Our Insight
Qdrant 1.13.x marks a significant milestone in the evolution of vector search technologies. Its GPU-accelerated architecture addresses longstanding performance bottlenecks in AI pipelines, particularly in LLM retrieval-augmented generation and visual data processing.
While the current GPU features are still maturing—limited algorithm compatibility and evolving documentation—Qdrant’s modular design and flexible deployment model position it as a strategic choice for cutting-edge AI systems. Its ability to intelligently allocate GPU resources at the collection level introduces a new paradigm of cost-aware performance scaling.
As the ecosystem matures, further support for additional algorithms (like full HNSW acceleration), improved observability, and broader hardware compatibility are expected to follow.
Key Takeaways
-
GPU acceleration in Qdrant 1.13.x delivers up to 10x indexing performance gains.
-
IVF-PQ and Flat indexes are fully GPU-supported; HNSW is partially accelerated.
-
Qdrant's new custom storage engine replaces RocksDB, resolving compaction-related latency.
-
Per-collection GPU assignment allows optimized resource distribution.
-
Ideal for semantic search, RAG pipelines, anomaly detection, and visual similarity use cases.
-
Docker-native deployment simplifies CI/CD integration for AI pipelines.
-
CUDA-enabled GPUs with ≥ 8GB VRAM are required; native binaries with GPU support are pending.
-
GPU feature set is still developing—expect enhancements in logging, API design, and docs in upcoming releases.
References
-
Qdrant 1.13 - GPU Indexing, Strict Mode & New Storage Engine - Qdrant
-
Qdrant promises 10x faster indexing with GPU-powered vector database - Blocks and Files
-
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding - ACL Anthology
-
qdrant/qdrant: Qdrant - High-performance, massive-scale Vector Database and Vector Search Engine for the next generation of AI. Also available in the cloud https://cloud.qdrant.io/