Beyond Black-Box Rewards: Interpretable and Adaptive Scoring for Aligned LLMs - ArmoRM
Large language models (LLMs) rely on reward models (RMs) to learn human preferences through RLHF.

Beyond Black-Box Rewards: Interpretable and Adaptive Scoring for Aligned LLMs - ArmoRM
-
Large language models (LLMs) rely on reward models (RMs) to learn human preferences through RLHF.
-
Traditional reward models use pairwise preferences and scalar outputs, limiting interpretability and flexibility.
-
The Bradley-Terry model, commonly used, cannot capture fine-grained, multi-dimensional feedback.
-
This leads to reward hacking, where models prioritize superficial traits like verbosity over true quality.
-
ArmoRM introduces multi-objective scoring across interpretable dimensions (e.g., helpfulness, correctness), combined with a Mixture-of-Experts (MoE) gating layer that dynamically weights these scores based on prompt context.
Understanding Reward Modeling and Its Limitations
Reward Modeling Fundamentals
Reward models serve as the supervisory signal in RLHF pipelines. Traditionally, they:
Take two model outputs (responses) to the same prompt.
Use pairwise annotations to train a Bradley-Terry (BT) model.
Output a scalar score indicating which response is better.
While simple and widely adopted, this scalar formulation struggles with nuanced human judgments. Complex preferences like truthfulness, helpfulness, or verbosity are collapsed into a single opaque number, making it difficult to interpret or adjust reward behavior post-hoc.
The Limitations of Scalar Reward Modeling
Despite its popularity, scalar reward modeling faces critical challenges:
-
No insight into why a response is preferred. The model only tells which output is better, not why.
-
Verbosity bias. Scalar RMs tend to reward longer responses—regardless of content quality.
-
No task-specific adaptability. All prompts are treated equally—even if safety is more relevant for some, and reasoning is more important for others.
-
Poor debuggability. It’s impossible to trace poor reward outcomes back to specific preference dimensions.
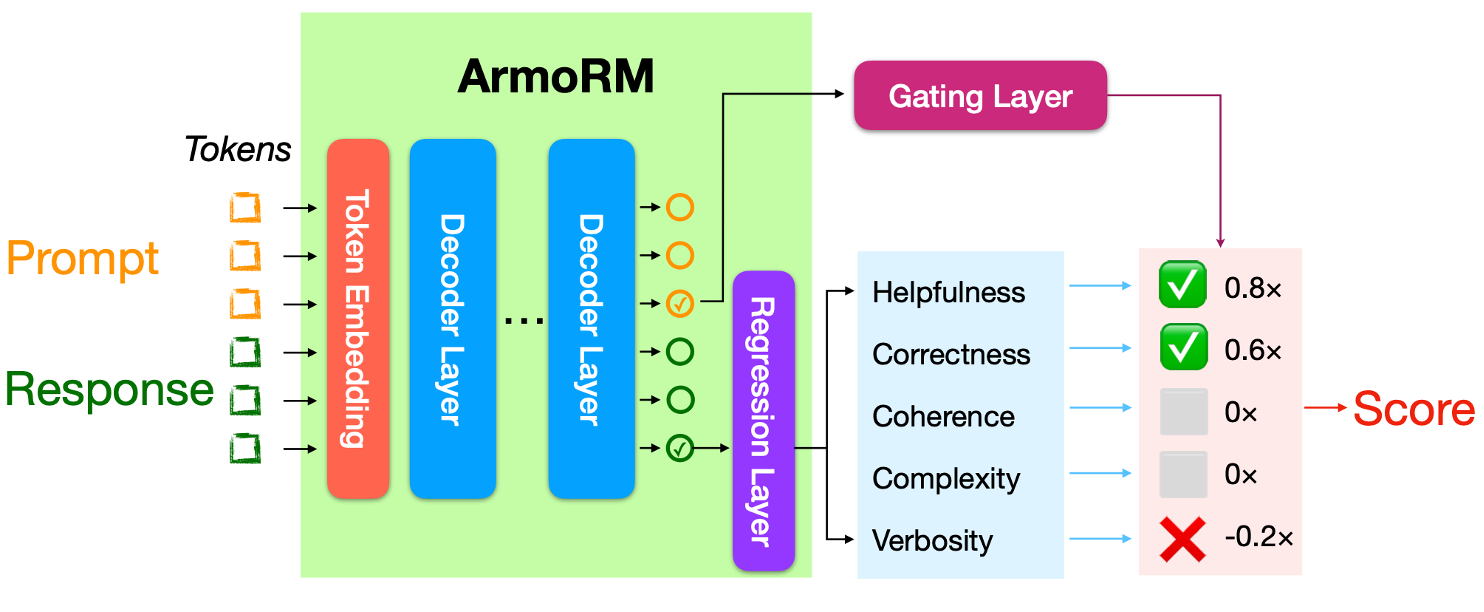
Advanced Reward Modeling with ArmoRM + MoE
To overcome these issues, the authors propose a two-stage reward modeling approach:
ArmoRM: Absolute-Rating Multi-Objective Reward Model
-
Learns to predict multi-dimensional reward vectors, e.g.: [helpfulness: 0.9, correctness: 0.7, safety: 0.6, verbosity: 0.2]
-
Trained via regression on datasets like UltraFeedback, HelpSteer, and BeaverTails that include absolute ratings for each objective.
Mixture-of-Experts (MoE) Gating Layer - How is the Reward Vector Aggregated?
-
Predict Multi-Objective Vector From a prompt-response pair (x, y), the model outputs:

-
Debias Verbosity A known problem in reward modeling is verbosity bias—longer responses often get higher scores. To mitigate this:
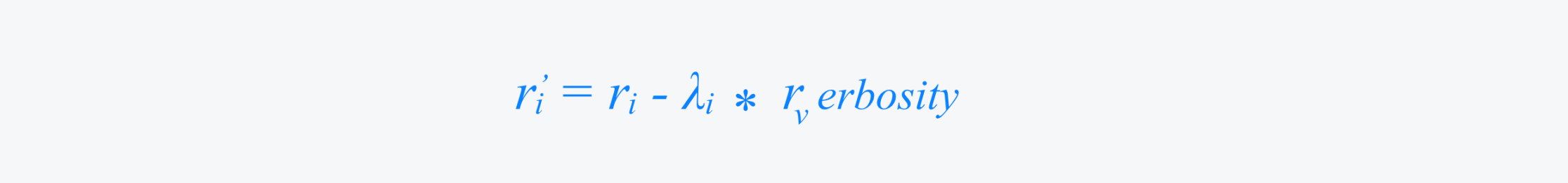
where λᵢ is tuned so that Corr(r^' ᵢ,r_v erbosity)= 0 under Spearman correlation.
-
Prompt-Conditioned Scalarization (via MoE Gating Layer) The model uses the prompt x to compute:
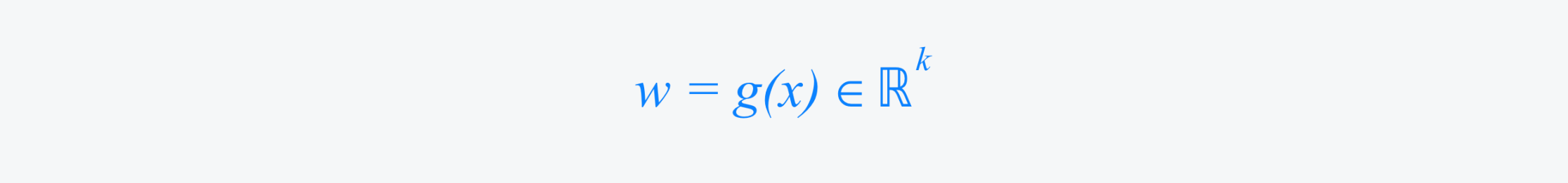
Final Score Calculation The final reward scalar is:
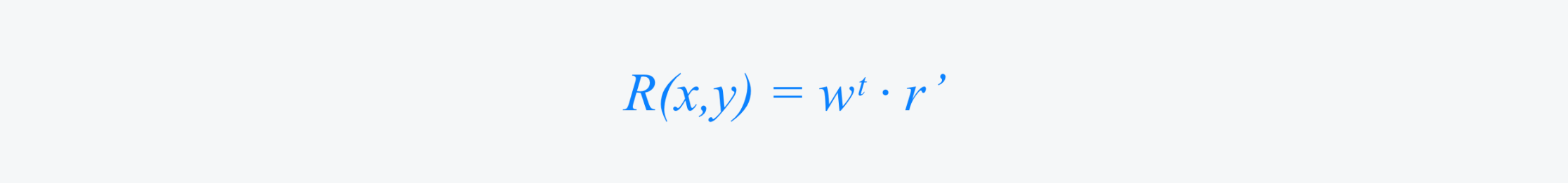
Only the gating layer is trained in this stage (using Bradley-Terry loss), keeping the LLM backbone and regression head frozen. This makes the system efficient and modular.
Reward Model Evaluation: RewardBench Insights
To assess the effectiveness of their approach, the authors evaluate ArmoRM + MoE on RewardBench—the first comprehensive benchmark specifically designed for reward model evaluation in language modeling.
Supported Model Types
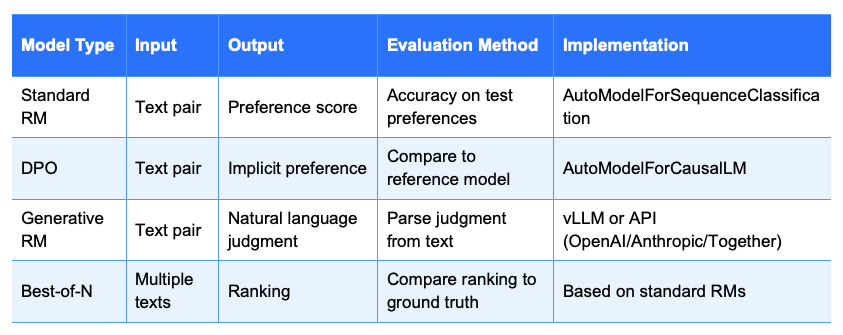
RewardBench evaluates several types of reward models:
-
Standard Reward Models (RMs): Sequence classification models that score preference pairs
-
DPO Models:Language models trained with Direct Preference Optimization
-
Generative Reward Models:LLMs used as judges to evaluate responses
-
Best-of-N Rankings:Models that rank multiple responses
The following table shows the key differences between model types:
RewardBench Categories
RewardBench consists of five evaluation tracks:
-
Chat - Measures general dialogue quality.
-
Chat Hard - Includes more ambiguous or difficult prompts.
-
Safety - Evaluates whether responses adhere to safety and alignment guidelines.
-
Reasoning - Assesses logical correctness and mathematical accuracy.
-
Prior Sets - Legacy evaluation datasets (weighted with a factor of 0.5).
Performance Highlights
The ArmoRM + MoE model, using only a LLaMA-3 8B backbone, achieves:
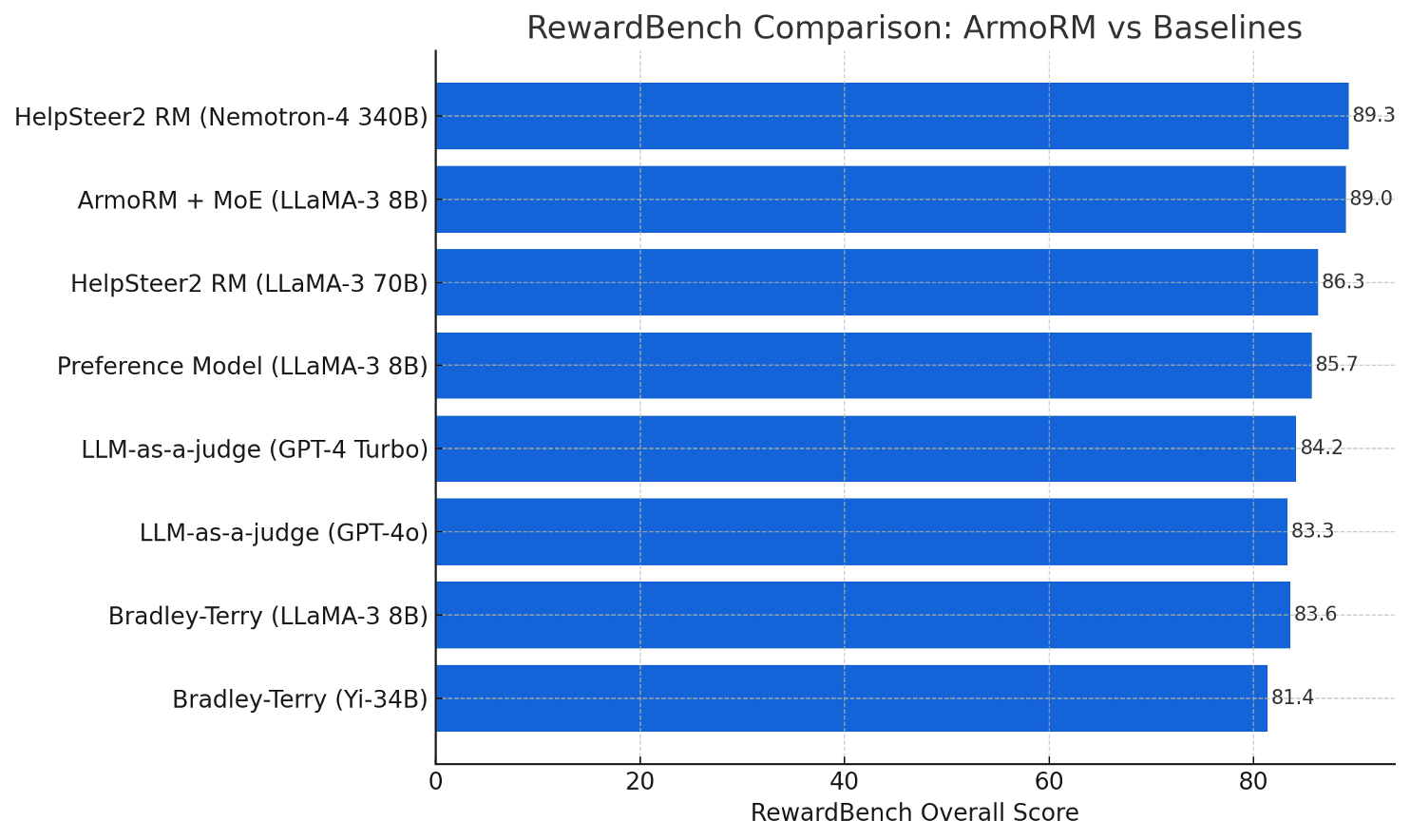
As the chart illustrates, ArmoRM + MoE achieves near state-of-the-art results while using only an 8B parameter backbone—demonstrating the power of interpretable and context-aware reward modeling. This demonstrates that interpretable multi-objective modeling and prompt-adaptive scalarization can close the performance gap with much larger black-box models, while remaining more efficient and transparent.
Our Mind
IInspired by ArmoRM, we developed a learnable scalarizer that dynamically combines a vector of handcrafted reward scores—derived from custom rule-based functions—into a single scalar value. Rather than relying on simple averaging, we introduced a context-aware gating mechanism that adjusts the aggregation weights based on the input.
The gating layer takes as input the concatenated system prompt, user prompt, and model response. The reward vector itself is composed of interpretable, rule-based functions that reflect various quality dimensions.
Our goal is to enable intelligent, context-sensitive aggregation of these reward scores. Averaging would treat all reward dimensions equally, regardless of task-specific relevance—a limitation in complex, real-world applications. By using a learnable scalarizer, the model can shift its emphasis dynamically, resulting in a more robust, interpretable, and task-adaptive reward signal.
Key Takeaways
-
ArmoRM replaces opaque scalar scoring with interpretable, multi-dimensional reward vectors across attributes like helpfulness, correctness, and safety.
-
A Mixture-of-Experts (MoE) gating mechanism enables prompt-aware aggregation of reward dimensions, enhancing adaptability to task context.
-
The model explicitly debiases verbosity by removing correlations between response length and reward scores.
-
Scalarization is made dynamic—adapting reward weightings per instance rather than relying on fixed averages.
-
Training is efficient and modular, with only the gating layer fine-tuned while keeping the LLM backbone and reward predictors frozen.
-
ArmoRM + MoE outperforms larger black-box models on RewardBench, despite using a lightweight LLaMA-3 8B backbone.
-
RewardBench evaluation validates the framework across diverse tasks like safety, reasoning, and ambiguous prompt handling.
-
Inspired by ArmoRM, we extended the scalarization approach to aggregate handcrafted, rule-based reward signals through context-aware weighting.
References
-
Wang, H., Xiong, W., Xie, T., Zhao, H., & Zhang, T. (2024). Interpretable preferences via multi-objective reward modeling and mixture-of experts. https://arxiv.org/abs/2406.12845
-
Wang, H. (2024, May 29). Multi-objective reward modeling and prompt-adaptive scalarization. RLHFLOW. https://rlhflow.github.io/posts/2024-05-29-multi-objective-reward-modeling/
-
Allen Institute for AI. (n.d.). RewardBench: Evaluation benchmark for reward models. Hugging Face Spaces. https://huggingface.co/spaces/allenai/reward-bench
-
Wang, B., Zheng, R., Chen, L., Liu, Y., Dou, S., ... (2024). Secrets of RLHF in large language models Part II: Reward modeling. arXiv. https://arxiv.org/abs/2401.06080
-
Sun, H., Shen, Y., & Ton, J.-F. (2025). Rethinking Bradley-Terry models in preference-based reward modeling: Foundations, theory, and alternatives. arXiv. https://arxiv.org/abs/2411.04991
-
Cui, G., Yuan, L., Ding, N., Yao, G., He, B., Zhu, W., ... & Sun, M. (2023). Ultrafeedback: Boosting language models with scaled ai feedback. arXiv preprint arXiv:2310.01377. https://arxiv.org/abs/2310.01377
-
Wang, Z., Dong, Y., Zeng, J., Adams, V., Sreedhar, M. N., Egert, D., ... & Kuchaiev, O. (2023). Helpsteer: Multi-attribute helpfulness dataset for steerlm. arXiv preprint arXiv:2311.09528. https://arxiv.org/abs/2311.09528
-
Ji, J., Liu, M., Dai, J., Pan, X., Zhang, C., Bian, C., ... & Yang, Y. (2023). Beavertails: Towards improved safety alignment of llm via a human-preference dataset. Advances in Neural Information Processing Systems, 36, 24678-24704.