The Future of Semantic + Lexical Search: BGE-M3 and MiniCOIL in Action
Modern search systems are evolving beyond traditional keyword-based methods by integrating both semantic and lexical signals

The Future of Semantic + Lexical Search: BGE-M3 and MiniCOIL in Action
-
Modern search systems are evolving beyond traditional keyword-based methods by integrating both semantic and lexical signals.
-
Models like BGE-M3 and architectures like MiniCOIL enable dense and sparse retrieval to work together seamlessly.
-
This hybrid approach allows search engines to deliver more accurate and context-aware results across diverse query types.
-
In this article, we explore how BGE-M3 and MiniCOIL redefine vector search through efficient score boosting and intelligent ranking strategies.
The Significance of BGE-M3 and MiniCOIL in Advancing Search Systems
What Is BGE-M3?
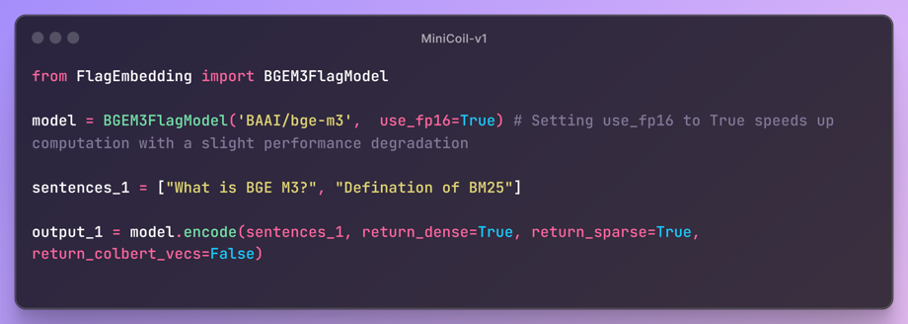
BGE-M3 (Balanced General Embedding for Multi-function, Multi-lingual, Multi-granularity) is a unified embedding model designed to support diverse retrieval tasks. Unlike conventional models that are specialized for dense or sparse retrieval only, BGE-M3 is trained to handle both efficiently. It supports multi-functionality, including dense retrieval, sparse retrieval, and even late interaction (multi-vector representation) — all from a single model checkpoint.
With cross-lingual capabilities across 100+ languages, BGE-M3 can be deployed in globally scaled search systems. The model uses a novel multi-query alignment strategy during training to learn representations that generalize across different retrieval granularities. It is also instruction-tuned, which improves downstream alignment and flexibility.
In practice, this means BGE-M3 can retrieve relevant results in various scenarios — from document-level semantic search to keyword-rich sparse ranking using late interaction — without model switching. As a result, it significantly simplifies engineering pipelines while improving relevance.
How Does BGE-M3 Differ from Other Embedding Models?
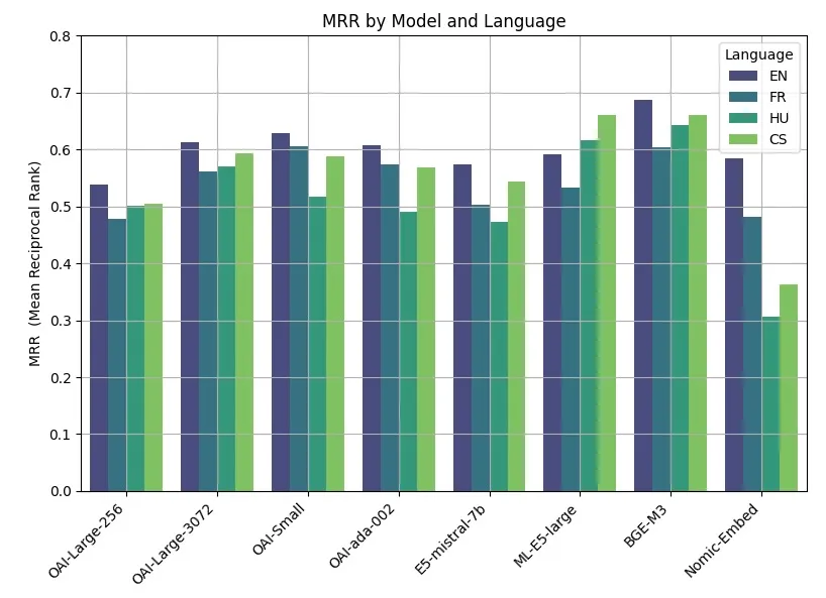
Most traditional embedding models are task-specific and optimized for either dense or sparse search, not both. For instance, models like GTR or GTE perform well in dense retrieval but lack sparse token-level interpretability. On the other hand, sparse-focused models such as SPLADE or uniCOIL excel in lexical relevance but fail to generalize semantically. BGE-M3 breaks this dichotomy by supporting both modalities in a single model. Moreover, it achieves high performance across different benchmarks without sacrificing latency or model size — a rare Pareto improvement in embedding design. Its dual encoder design and training regimen allow BGE-M3 to excel at reranking as well, making it a true multi-task model. Unlike other models that require ensemble methods or post-hoc score fusion, BGE-M3 performs competitively with a single-pass approach. This makes it both easier to use and more efficient in real-world applications.
What Is MiniCOIL?
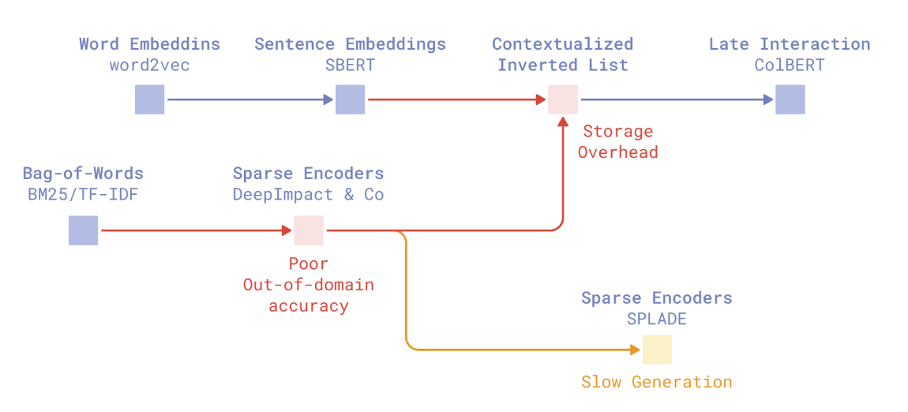
MiniCOIL is a production-friendly approach in the Sparse Neural Retrieval field, inspired by the COIL method. Its goal is to produce sparse vectors that retain the strengths of BM25 while being capable of distinguishing word meanings.
Key Features:
-
Inspired by COIL: COIL represented each token with a 32-dimensional vector, but these vectors were incompatible with standard inverted indexes and worked at the token level, leading to fragmented matches.
-
MiniCOIL's solution: It reduces each word’s representation to a 4-dimensional semantic vector and transforms it into a sparse format. Each semantic dimension is assigned to a separate slot in the sparse vector.
-
BM25 integration: When a word’s meaning cannot be captured semantically, the system falls back to the classic BM25 score, combining semantic awareness with proven ranking performance.
-
Advantages: It requires less data to train, remains compatible with inverted indexes, can distinguish homographs, and is easy to deploy in real-world systems.
In short, MiniCOIL enhances traditional term-based retrieval by introducing semantic depth, all while preserving BM25’s robustness and simplicity.
Token-Level Meaning Disambiguation with Sparse Embeddings
One of MiniCOIL’s most powerful features is its ability to differentiate between meanings of the same word in different contexts—through token-level sparse embeddings.
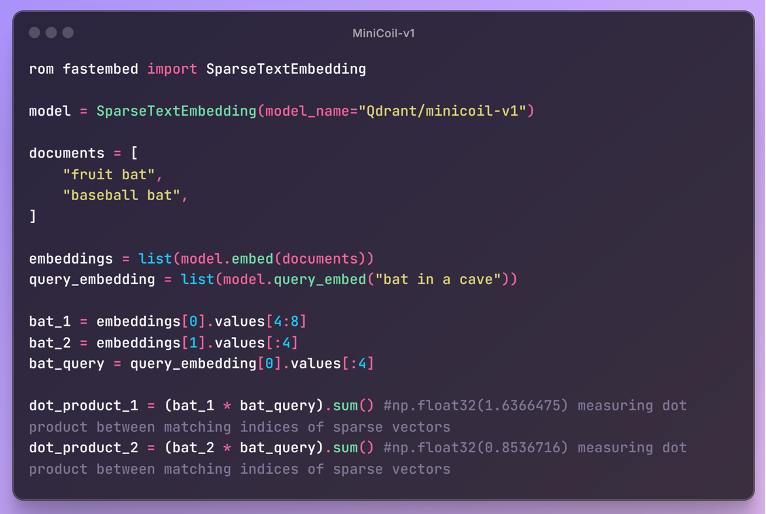
In this example, the word "bat" appears in both "fruit bat" and "baseball bat", yet the MiniCOIL-generated embeddings reflect the correct semantic interpretation when matched with the query "bat in a cave". Each token is represented as a sparse vector over fixed dimensions, and for known vocabulary terms, MiniCOIL assigns multi-dimensional indices (e.g., four dimensions per token). The dot product between the “bat” representation in “fruit bat” and the query yields a higher similarity score than with “baseball bat”, demonstrating that the model associates the query meaning more with the animal than the sports equipment. This token-aware representation allows the model to resolve word sense disambiguation more effectively than traditional dense embeddings or lexical-only methods. Additionally, if a token is not in the MiniCOIL vocabulary, the model gracefully falls back to a 1D BM25-style score, ensuring full coverage. This hybrid structure enables precise and interpretable similarity computations, especially in ambiguous queries.
Key Implementation Considerations
When integrating BGE-M3 and MiniCOIL into production search systems, several important factors must be considered:
Scalability: The ability to scale models like BGE-M3 and MiniCOIL across large datasets is paramount. Both models are designed with efficiency in mind but deploying them at scale will require robust infrastructure and distributed computing strategies.
Model Tuning and Continuous Updates: Both models benefit from continuous fine-tuning to ensure they adapt to changing data distributions and user behavior. Regular updates are essential for maintaining high performance and relevance, especially in dynamic search environments.
Seamless Hybrid Retrieval Integration: Ensuring that dense and sparse retrieval methods work together seamlessly in BGE-M3 and MiniCOIL is crucial. Careful attention must be given to the integration process to ensure that each retrieval approach contributes effectively to the overall search experience.
Handling Ambiguous Queries: MiniCOIL's ability to disambiguate meanings at the token level is one of its standout features. However, this requires monitoring to ensure that the system accurately handles a wide range of ambiguous queries without overfitting to specific contexts.
Fallback Mechanism: MiniCOIL’s fallback to BM25 for unseen terms ensures full coverage. However, the reliance on this fallback mechanism should be carefully managed to avoid undermining the benefits of the semantic enhancements.
Performance vs. Cost: Deploying advanced models like BGE-M3 and MiniCOIL can be resource-intensive. It is important to balance the performance benefits these models bring with the operational costs, especially when considering large-scale deployments or real-time applications.
Our Mind
The integration of both dense and sparse retrieval within a single model has significant implications for the future of search engines. BGE-M3 and MiniCOIL represent a shift towards more intelligent, context-aware search systems that go beyond the limitations of traditional keyword-based methods.
The BGE-M3 model stands out for its multi-functionality, allowing seamless handling of various retrieval tasks in a single framework. This simplifies deployment and reduces the need for separate models, which can be a major advantage in real-world applications where speed and scalability are key. Furthermore, its cross-lingual capabilities make it particularly suitable for globalized systems, addressing the need for efficient, multilingual search.
MiniCOIL, on the other hand, provides significant improvements in lexical-semantic retrieval. By introducing token-level meaning disambiguation, it ensures that words are interpreted based on their context, which is a critical feature for accurate search results in ambiguous queries. This makes MiniCOIL particularly useful in applications where fine-grained understanding of word meanings is essential.
Both models are designed to be efficient and production-friendly, which is crucial for large-scale deployments. However, integrating such sophisticated models into existing systems will require careful planning, including considerations of scalability, maintenance, and tuning to ensure they perform optimally in dynamic real-world environments.
Key Takeaways
-
BGE-M3's Versatility: BGE-M3 (Balanced General Embedding for Multi-function, Multi-lingual, Multi-granularity) is a unified embedding model that efficiently handles both dense and sparse retrieval tasks. Its ability to support multiple retrieval functionalities—from semantic search to keyword-based ranking—simplifies engineering pipelines and significantly improves relevance in search systems.
-
Hybrid Retrieval Model: Unlike traditional models that specialize in either dense or sparse retrieval, BGE-M3 offers a hybrid approach, handling both efficiently within a single model. This eliminates the need for model switching and ensemble methods, enhancing both performance and ease of use.
-
MiniCOIL's Token-Level Semantic Understanding: MiniCOIL leverages sparse vectors to enhance traditional term-based retrieval while introducing semantic depth. By incorporating BM25's robustness and distinguishing word meanings in different contexts (e.g., "bat" in "fruit bat" vs. "baseball bat"), MiniCOIL improves accuracy for ambiguous queries.
-
Global Search with Cross-lingual Support: BGE-M3 supports over 100 languages, making it a powerful tool for large-scale, globally deployed search systems. Its ability to generalize across diverse linguistic and retrieval scenarios makes it a truly versatile solution.
-
Efficient Model Performance: Both models are optimized for low-latency and compact model sizes, making them suitable for real-time applications where speed and resource efficiency are critical.