Understanding Sentence Transformers: Loss Functions and the Fine-Tuning Pipeline
Sentence Transformers (SBERT) are widely used for semantic similarity tasks like reranking, clustering, and semantic search.

Understanding Sentence Transformers: Loss Functions and the Fine-Tuning Pipeline
-
Sentence Transformers (SBERT) are widely used for semantic similarity tasks like reranking, clustering, and semantic search.
-
Fine-tuning is essential to unlock their full potential, with the loss function playing a key role.
-
This article covers the complete training pipeline: preprocessing, training, and evaluation.
-
It also reviews model evaluation with the Massive Text Embedding Benchmark (MTEB) and guides on choosing the right loss function for your needs.
The Sentence Transformer Training Pipeline
Common Preprocessing Techniques
When training embedding models with Sentence Transformers, preprocessing plays a crucial role in ensuring input consistency, model compatibility, and performance. This is due to the fact that preprocessing directly modifies the data to conform to specific requirements of different loss functions, which may require the data in different formats.
-
Deduplication (using SemHash)
This step analyzed the dataset to remove duplicate or near-identical sentences to make input data remain diverse and free of redundant information.
-
Decontamination
Removes any overlaps between an evaluation (or test) dataset and a training dataset.
-
Lemmatization (using spaCy)
Reduces words to their most basic form for a more efficient semantic representation.
-
Stemming (using NLTK)
Chops off prefixes and suffixes to reduce words to their basic or root form. (Very primitive compared to lemmatization since it uses heuristic approaches instead of a model)
-
Normalization
Standardizes the text by cleaning it up with regex-based methods.
-
Language Filtering (using langdetect)
Keeps only target language in the dataset by filtering.
-
Length Filtering
Removes sentences that are too short or too long from the dataset.
-
Column Cleanup and Ordering
Matches column order to the chosen loss function.
-
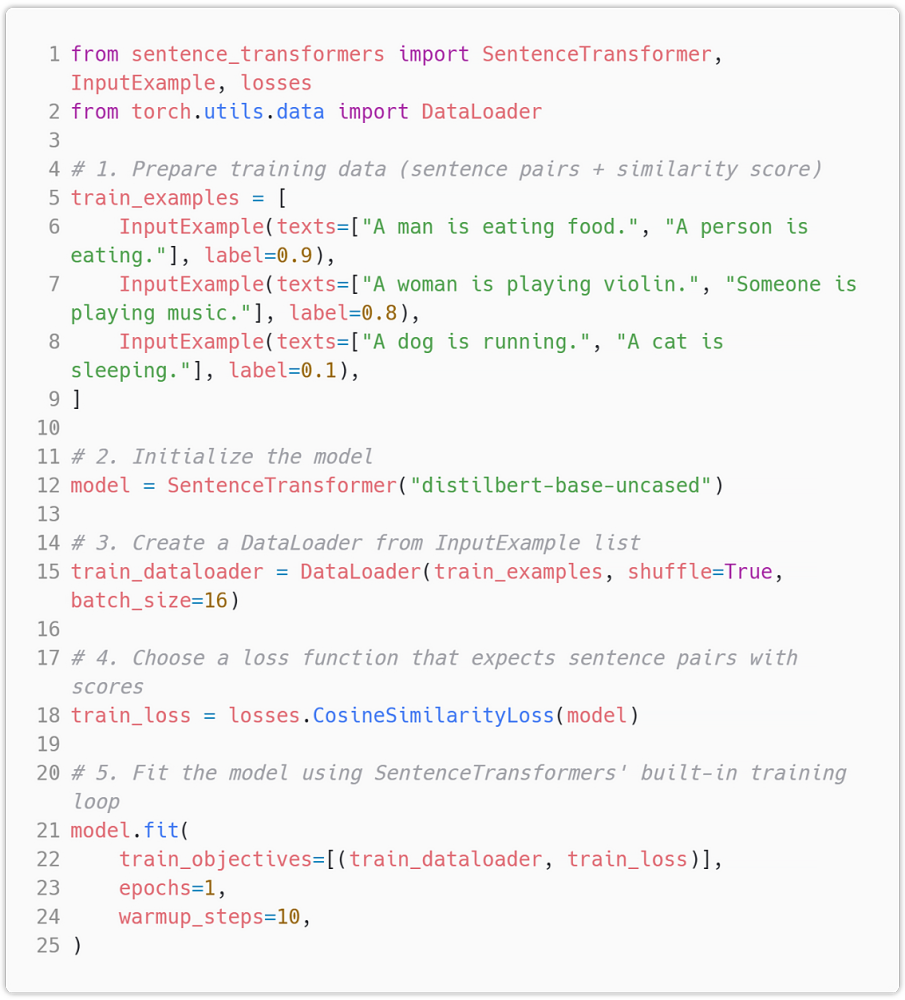
Sentence Pairs (for similarity/regression)
Used with loss functions like CosineSimilarityLoss, MSELoss, ContrastiveLoss, etc.
-
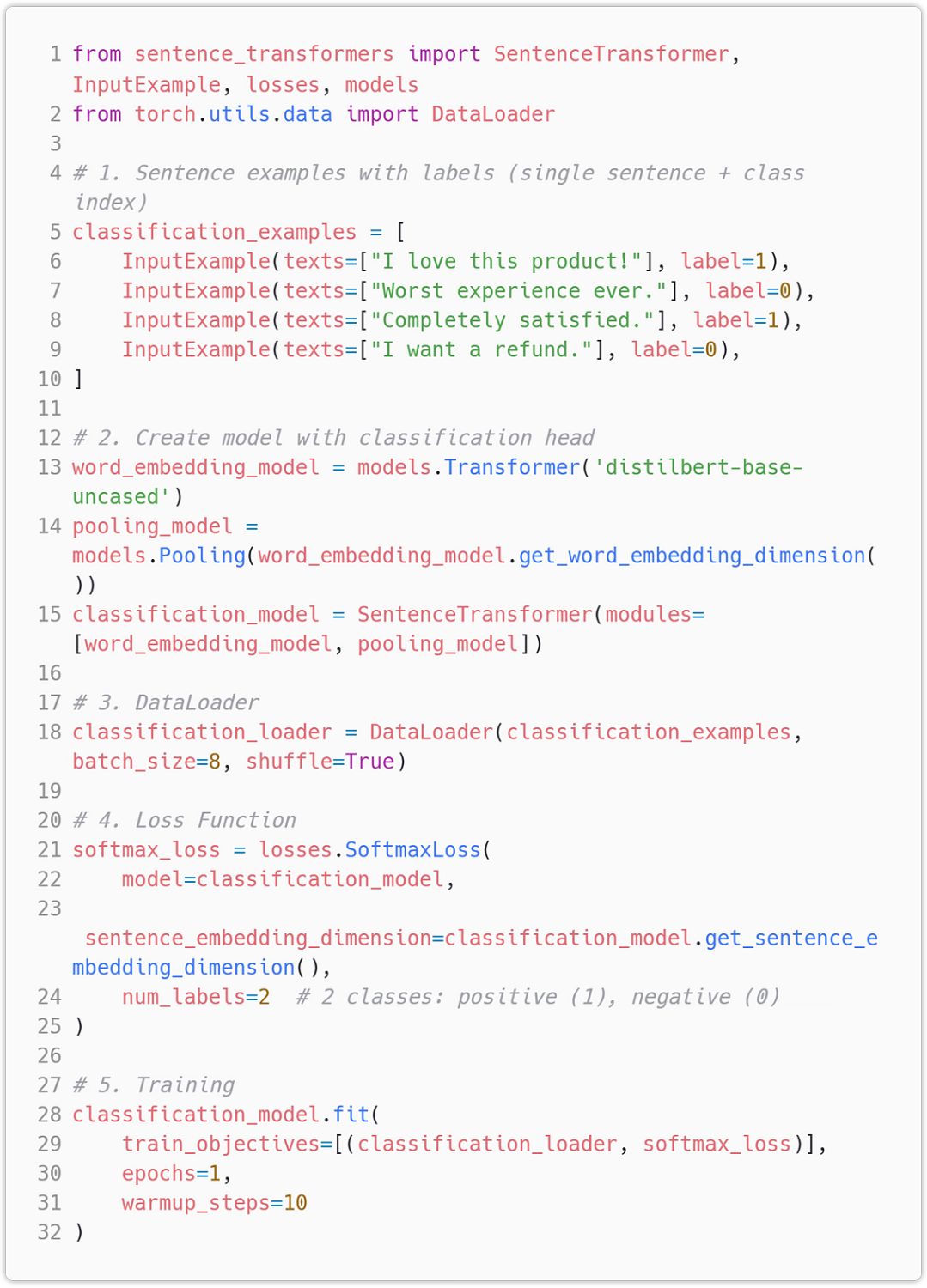
Labeled Pairs (for classification)
Used with SoftmaxLoss or when labels represent class IDs.
-
Triplets (anchor, positive, negative)
Used with TripletLoss, BatchHardTripletLoss, etc.








The data needs to be structured into one of the following forms prior to training:



Training
In order to help the model improve its predictions or classifications by discovering patterns in the data, training involves providing it with training data, calculating the loss, and repeating the procedure multiple times.

Model Evaluation: MTEB + Custom Metrics
To measure performance, you can use MTEB for extensive evaluation on tasks like Classification, Clustering, Reranking, Retrieval, and STS.
-
Classification: This evaluates a model's ability to group texts into pre-defined groups.
-
Clustering: It measures how well a model can group similar texts together.
-
Reranking: This task evaluates a model's ability to reorder a list of candidate texts according to their relevance.
-
Retrieval: It measures the model’s proficiency in identifying and retrieving relevant documents.
-
Semantic Textual Similarity (STS): This measures how well the model captures the semantic similarity between pairs of sentences.

What is a Loss Function?
A loss function is a mathematical function that quantifies how well or poorly a model is performing by measuring the difference between its predicted output and the actual target value. Since measuring performance depends on the method used for different tasks, there are different loss functions for addressing unique needs.
Common Loss Functions
Loss functions can accept data in different structured forms. Below is a list of all available loss functions in Sentence Transformers library, each to handle various input data formats and task requirements.
Loss Functions Using Sentence Pairs + Labels (Similarity Scores)
-
CosineSimilarityLoss: Measures sentence similarity by directly minimizing the difference between predicted and actual cosine similarity scores.
-
ContrastiveLoss: Pushes different sentences away while allowing comparable sentences to have closer embeddings.
-
CoSENTLoss: Optimizes sentence similarity using cosine similarity and ranking constraints.
-
MSELoss: The average squared difference between expected and actual values is measured by mean squared error loss for sentence embeddings.
-
MarginMSELoss: MSE loss with a margin constraint to guarantee that positive and negative pairs differ as little as possible.
-
OnlineContrastiveLoss: Dynamically selects hard positive and negative pairs.
-
AnglELoss: A modification of CoSENTLoss that improves semantic alignment by optimizing angle differences between sentence embeddings.
Loss Functions Using Triplets: (Anchor, Positive, Negative)
-
TripletLoss: Standard triplet loss for sentence embeddings.
-
BatchAllTripletLoss: Computes loss for all valid triplets in a batch.
-
BatchHardTripletLoss: Emphasizes the most difficult examples by focusing on the hardest positive and negative samples in a batch.
-
BatchSemiHardTripletLoss: Uses semi-hard triplets for optimization.
-
BatchHardSoftMarginTripletLoss: Gives the optimization process greater flexibility by using a soft margin rather than a set one.

Loss Functions Using Multiple Negatives
-
MultipleNegativesRankingLoss: Optimizes ranking by contrasting a positive example against multiple negatives.
-
CachedMultipleNegativesRankingLoss: A cached version for efficiency.
-
MultipleNegativesSymmetricRankingLoss: A symmetric variant of MultipleNegativesRankingLoss that considers both directions.
-
CachedMultipleNegativesSymmetricRankingLoss: Cached version for efficiency.

Classification-Style Losses
-
SoftmaxLoss:Uses softmax classification to optimize sentence embeddings.
Denoising Losses
-
DenoisingAutoEncoderLoss: Trains a model to reconstruct original sentences from noisy inputs.

Specialized Losses
-
ContrastiveTensionLoss: Maximizes the similarity between positive pairs and minimizes the similarity between negative pairs by using contrastive tension.
-
ContrastiveTensionLossInBatchNegatives: Applies contrastive tension with in-batch negatives.
-
GISTEmbedLoss: Uses guided embedding selection for sentence similarity.
-
CachedGISTEmbedLoss: A cached version of GISTEmbedLoss for efficiency.
-
MatryoshkaLoss: A hierarchical loss function for embeddings.
-
Matryoshka2dLoss: A 2D variant of MatryoshkaLoss that optimizes embeddings in a two-dimensional space.
-
AdaptiveLayerLoss: Adjusts the loss dynamically according to the outputs from the model's different layers.
-
MegaBatchMarginLoss: Uses large batches for margin-based optimization to generalize better.





Selecting the Most Suitable Loss Function
Choosing the right loss function is crucial as it guides learning and shapes how embeddings are optimized for your specific use case. Consider these key factors:
-
Task Type: For sentence similarity tasks, use similarity-based losses like CosineSimilarityLoss or MSELoss. For classification problems, SoftmaxLoss is more appropriate.
-
Data Structure: Match your data format to the loss function. Pairwise losses work best with sentence pairs and similarity scores, while triplet losses require anchor, positive, and negative sentences.
-
Evaluation Metrics: Align your loss function with your performance metrics. Use SoftmaxLoss if your metrics are accuracy or F1 score. For retrieval tasks evaluated by MRR, Recall@K, or NDCG, ranking losses like MultipleNegativesRankingLoss are ideal.
-
Model Robustness: Some losses, such as BatchHardTripletLoss, enhance robustness by focusing training on the hardest examples, improving performance on noisy or ambiguous data.
-
Experimentation: Empirically test multiple compatible loss functions to determine which best suits your data and task.
Our Perspective
In creating this guide, our mission was to simplify the fine-tuning process for Sentence Transformers by delivering a hands-on, comprehensive resource focused on practical steps—not just theory. We’ve carefully broken down the entire workflow, from data preprocessing to choosing the right loss function, to create a straightforward manual that practitioners can easily follow. We believe that understanding why a particular loss function is chosen is just as crucial as knowing how to implement it. Our goal is to empower you to confidently experiment, build more effective models, and fully unlock the power of sentence embeddings tailored to your unique projects.
Key Takeaways
-
Lemmatization over Stemming: For morphologically rich languages, prefer lemmatization over stemming to achieve more accurate and meaningful semantic representations.
-
MultipleNegativesRankingLoss for Retrieval: This loss function is particularly effective and efficient for retrieval tasks, making it a strong choice when optimizing for ranking-based objectives.
-
Monitor Data Leakage and Mode Collapse: Proactively monitor these issues during training to maintain model robustness and ensure reliable evaluation results.
-
Empirical Experimentation: Testing different loss functions and configurations is essential to identify the optimal setup tailored to your specific task and dataset.
-
Align Loss Function with Evaluation Metrics: Choose a loss function aligned with your evaluation metrics and task nature: use similarity-based losses for semantic similarity tasks, classification losses like SoftmaxLoss for classification, and ranking losses for retrieval.
-
Structure Data Appropriately: Structure your data appropriately for the chosen loss function, whether it's sentence pairs, triplets, or labeled pairs, to maximize training effectiveness.
-
Consider Robustness-Enhancing Losses: Consider robustness-enhancing loss functions such as BatchHardTripletLoss, which focus training on challenging examples and improve model generalization.