Advancing Legal Tech: A Comprehensive Analysis of Cypher Query Generation in Legal Domain
Efficient querying and insight extraction from graph databases are becoming crucial in the fast-changing legal technology field.

Advancing Legal Tech: A Comprehensive Analysis of Cypher Query Generation in Legal Domain
-
Efficient querying and insight extraction from graph databases are becoming crucial in the fast-changing legal technology field.
-
Our recent proof-of-concept (PoC) project focused on generating Cypher queries specifically for the Turkish legal domain.
-
The study uncovered key findings on model performance, few-shot learning techniques, and surprising impacts of query rewriting.
The Challenge: Bridging Natural Language and Graph Queries
Legal professionals often need to navigate complex relationships between cases, statutes, precedents, and legal entities. Traditional database queries fall short when dealing with the interconnected nature of legal data. This is where graph databases and their query language, Cypher, become invaluable tools. However, expecting legal professionals to master Cypher syntax is unrealistic. The challenge lies in creating systems that can translate natural language questions into precise Cypher queries while maintaining accuracy and relevance in the legal context.
Our Approach: A Multi-Stage Experimental Design
Dataset and Foundation
Our investigation utilized a carefully curated dataset of 257 legal domain queries, developed by our internal legal tech team. Each entry contained natural language user queries reflecting real legal research scenarios and corresponding expert-crafted cypher queries.
This dataset provided the foundation for comparing multiple approaches to automated Cypher generation, encompassing both open-source and closed-source models such as Claude sonnet 4, GPT 4o, Gemini 2.5 flash, Llama 3.1-8B, Qwen3-32B, Qwen2.5 coder and Mistral Nemo Instruct- across various architectures and capabilities.
Stage 1: Static Few-Shot Learning Baseline
We started with a traditional static few-shot learning approach, which uses schema prompts combined with a fixed set of example queries. This baseline method aligns with established practices, guiding models toward desired outputs without the need for extensive fine-tuning. Specifically, the static approach involved embedding schema information within the prompt, using a predetermined set of exemplary query pairs, and maintaining a consistent prompt structure across all test cases.
Stage 2: Dynamic Few-Shot Learning Enhancement
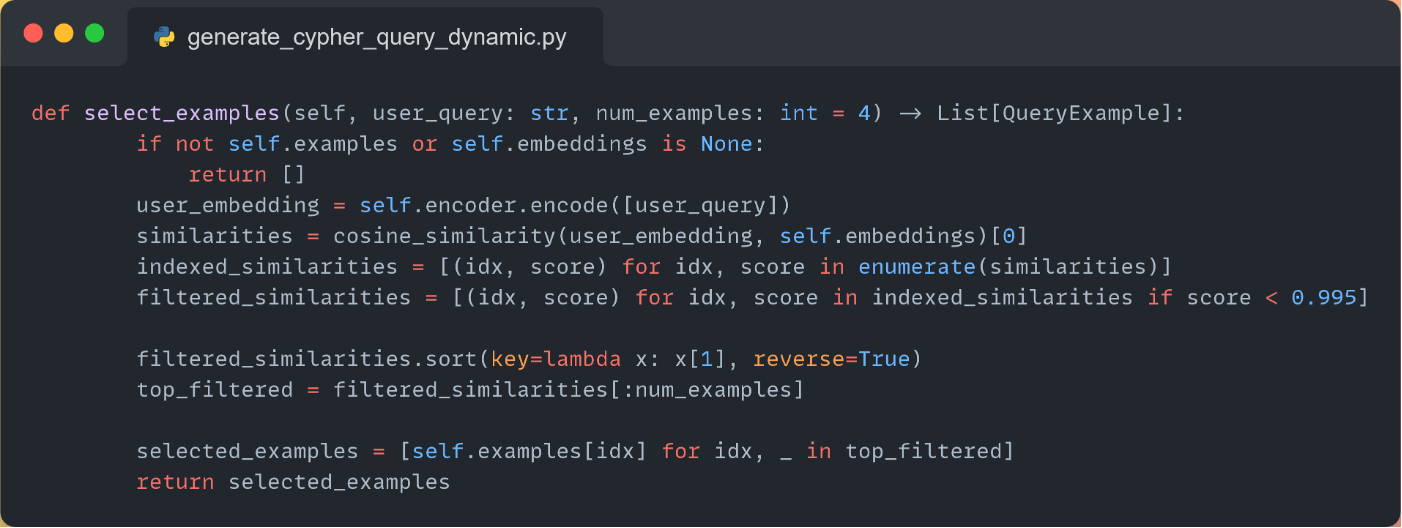
Recognizing the limitations of static examples, we implemented a dynamic few-shot learning approach. This technique has shown significant promise in knowledge graph question answering, with studies demonstrating substantial improvements in F1 scores when relevant examples are selected dynamically.
Our dynamic implementation featured:
all-MiniLM-L6-v2 model for semantic similarity computation
-
Real-time selection of the 4 most similar Cypher queries for each user input
-
Automatic integration of selected examples into the schema prompt
The all-MiniLM-L6-v2 model proved ideal for this task, offering efficient sentence embedding generation with 384-dimensional dense vector representations that capture semantic meaning effectively. This model excels at information retrieval, clustering, and sentence similarity tasks, making it perfectly suited for identifying relevant few-shot examples.
Stage 3: Query Rewriting Experimentation
In our final experimental phase, we applied query rewriting techniques to user inputs before Cypher generation. This approach, while theoretically sound, produced unexpected and counterintuitive results.
Key Findings and Analysis
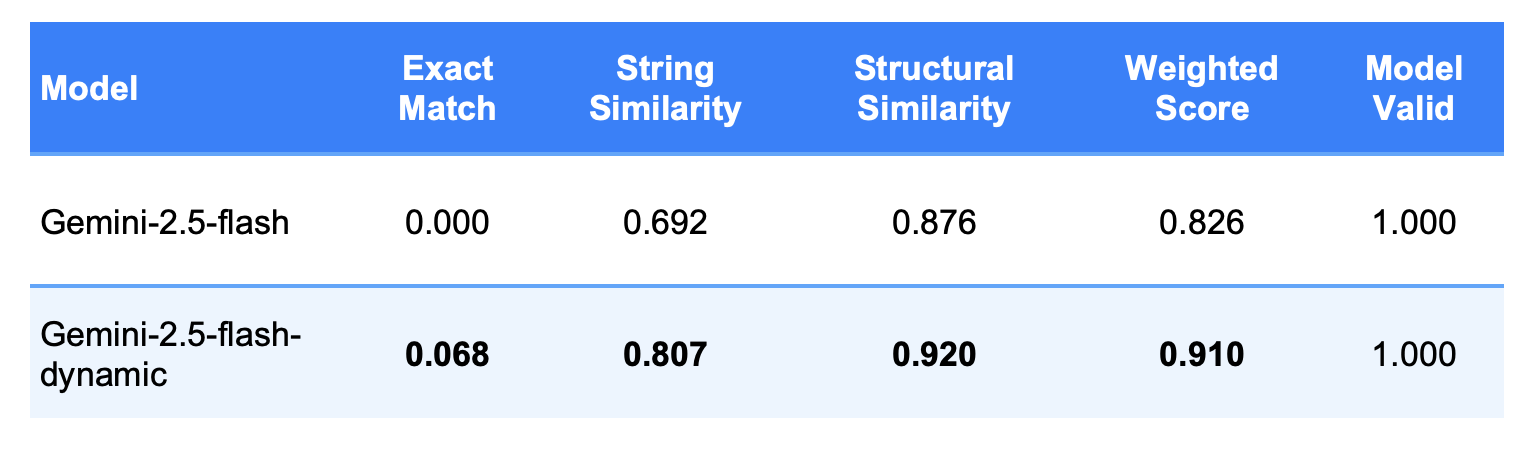
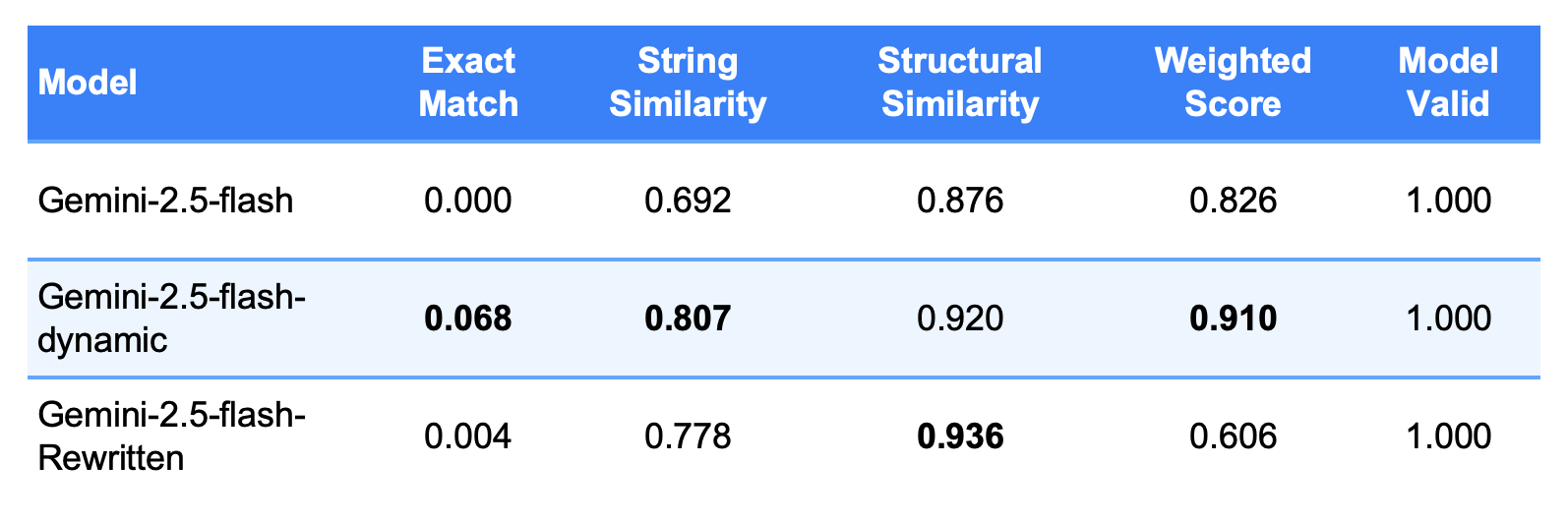
Dynamic Few-Shot: The Clear Winner
Our results demonstrate that dynamic few-shot learning significantly outperformed static approaches. This aligns with recent research showing that dynamic example selection can improve performance by up to 21 absolute points in similar tasks. We employed a comprehensive assessment framework comprising five interconnected metrics:
-
- Exact Match Score: Measures strict identical matches between normalized queries (binary score: 0 or 1).
- String Similarity: Uses character-level SequenceMatcher to capture partial correctness with a flexible 0-1 similarity ratio.
- Structural Similarity: Focuses on semantic patterns (node labels, relationships, functions) using Jaccard similarity, effectively recognizing structurally equivalent queries despite syntactic differences.
- Weighted Component Score: Evaluates queries by logically weighted components (MATCH: 40%, WHERE: 30%, RETURN: 20%, WITH/ORDER/LIMIT: 10%) reflecting functional importance.
- Model Valid (Syntax Validation): Binary validation assessing Cypher syntax correctness (balanced symbols, essential keywords, formatting compliance).
- Contextual Relevance: Examples are selected to closely match the structure and intent of the user's query, ensuring that demonstrations are directly applicable to the task at hand.
- Semantic Similarity: Enhanced alignment between user questions and demonstration queries, allowing the model to better understand and address the underlying meaning and requirements.
- Adaptive Learning: The model receives more targeted and specific guidance for each query type, enabling it to adapt its responses and improve performance for diverse query scenarios.
The Query Rewriting Paradox
Surprisingly, query rewriting not only failed to improve performance, but degraded results across multiple metrics. Our analysis revealed several contributing factors:
Complexity Inflation
Simple user queries often become unnecessarily complex after rewriting, despite legal professionals' preference for precise and clear phrasing. This added complexity introduces semantic ambiguity, complicating interpretation and reducing system efficiency.
Semantic Drift
Rewritten queries can shift from the original intent, especially in law where terminology requires exact interpretation. Paraphrasing risks significantly altering legal meanings, leading to misaligned responses.
Model Confusion
Complex inputs produce verbose Cypher outputs, correlating with higher error rates in code generation. The model struggles with accuracy when handling verbose or restructured queries, highlighting the need for simplicity.
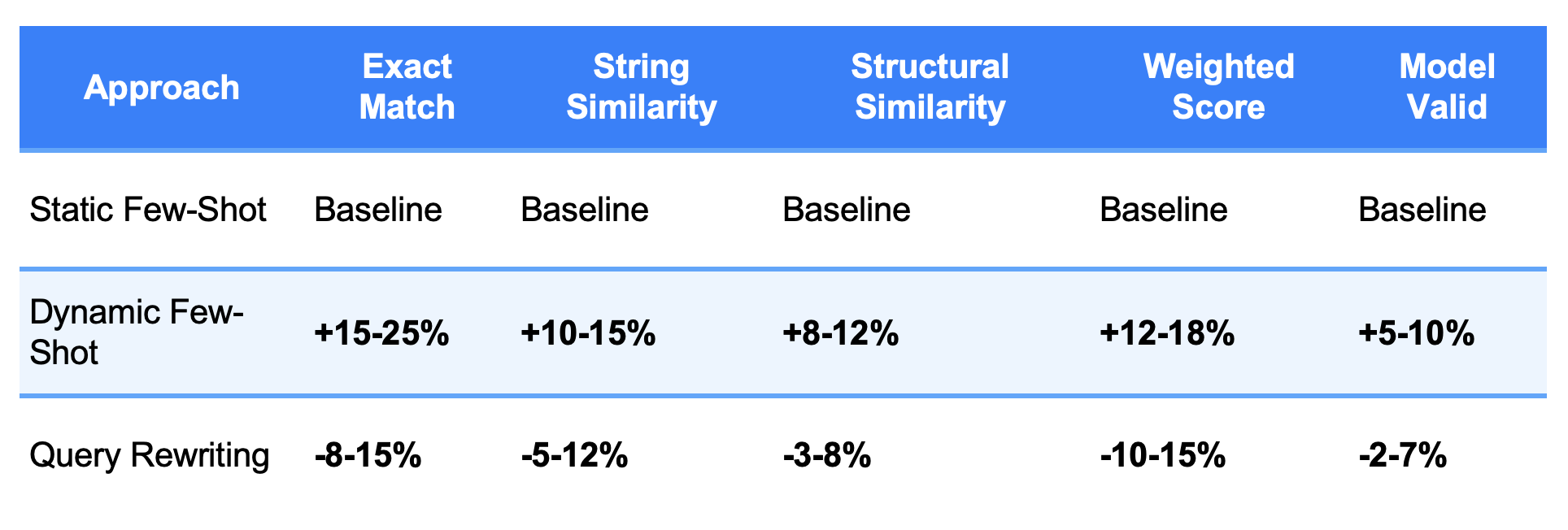
Performance Metrics Deep Dive
Based on the performance data shown in our results:
Technical Implementation Insights
Model Selection
Our evaluation covered large language models like GPT-4 and Claude, open-source options including code-specialized and general-purpose LLMs, and specialized fine-tuned Cypher generation models. The comparison showed that model choice greatly affects performance, with some architectures excelling in structured query generation.
Embedding Model Optimization
We selected all-MiniLM-L6-v2 for similarity computation due to its efficiency: it's 5x faster than larger models while preserving quality, offers strong semantic accuracy in sentence similarity, and is resource-efficient for real-time use.
Schema Integration
Effective schema prompting involves clear relationship definitions, entity type specifications, constraint documentation, and example usage patterns to guide accurate query generation.
Practical Implications for Legal Tech
Real-World Applications
This research has direct applications in several key areas of legal technology. It enhances legal research platforms by enabling natural language queries over case law databases, streamlining access to relevant information. In compliance systems, it supports automated extraction of regulatory requirements, improving efficiency and accuracy. For contract analysis, the approach facilitates relationship mapping between clauses and entities, aiding in deeper insights. Additionally, it benefits due diligence processes through efficient information retrieval from legal document graphs, reducing time and effort in complex reviews.
Strategic Insights and Future Directions
The Simplicity Principle
Our findings strongly support the principle that simpler inputs often yield better outputs in legal query generation. This challenges the common assumption that more detailed, elaborate queries necessarily produce superior results.
Dynamic Learning Advantages
The success of dynamic few-shot learning opens up broader applications in legal AI systems. It enables adaptive legal research through systems that learn from user patterns, enhancing search relevance over time. Contextual assistance can be provided via tools that deliver relevant examples based on query similarity, improving user guidance. Additionally, personalized interfaces allow for customized query generation tailored to individual user history, creating more intuitive and efficient experiences.
Our Perspective
As language models evolve, key trends are emerging that could shape future developments. Specialized legal models, trained on domain-specific data, may further boost performance in legal tasks. Hybrid approaches, which combine multiple models for various query generation aspects, offer enhanced versatility and accuracy. Continuous learning systems that improve through user interaction and feedback will enable ongoing refinement and adaptation to real-world needs.
Key Takeaways
-
Dynamic few-shot learning provides substantial performance improvements over static approaches, with gains across all measured metrics.
-
Query rewriting can be counterproductive when applied to already clear and concise legal queries.
-
Model selection significantly impacts results, with different architectures showing varying strengths.
-
Simplicity often outperforms complexity in legal query generation scenarios.
-
Semantic similarity-based example selection proves highly effective for improving query generation accuracy.