Turk-LettuceDetect: Advancing Hallucination Detection in Turkish RAG Systems
Hallucination—confident but incorrect outputs—remains a major challenge for Turkish language AI due to its complex morphology and limited NLP resources. Turk-LettuceDetect is the first hallucination detection model specifically adapted for Turkish Retrieval-Augmented Generation (RAG) systems, achieving strong performance on a translated benchmark dataset.

Turk-LettuceDetect: Advancing Hallucination Detection in Turkish RAG Systems
📌 Hallucination—confident but incorrect outputs—remains a major challenge for Turkish language AI due to its complex morphology and limited NLP resources.
📌 Turk-LettuceDetect is the first hallucination detection model specifically adapted for Turkish Retrieval-Augmented Generation (RAG) systems, achieving strong performance on a translated benchmark dataset.
📌 By leveraging token-level classification and advanced encoder architectures, this solution provides precise and efficient hallucination detection tailored to Turkish AI applications.
Why Hallucination Detection Matters for Turkish AI
Large language models (LLMs) have revolutionized AI, but their tendency to "hallucinate"—generating confident yet factually incorrect outputs—remains a critical barrier to real-world trust. For Turkish, a morphologically rich but low-resource language, this problem is amplified. Turkish's agglutinative structure (e.g., stacking suffixes to build complex words) and limited NLP resources make aligning model outputs with source material far more challenging than in English.
Enter Turk-LettuceDetect, the first hallucination detection models tailored for Turkish Retrieval-Augmented Generation (RAG) systems. Built on the LettuceDetect paradigm, our solution fine-tunes state-of-the-art encoder models to identify unsupported claims in Turkish text, achieving 72.66% F1-score on a machine-translated Turkish version of the RAGTruth benchmark.
LettuceDetect's Adaptation to Turkish Language
RAG systems aim to ground LLM responses in external knowledge, but hallucinations persist due to:
- Retrieval gaps: Missing critical context.
- Context misinterpretation: Misaligned query-document relationships.
- Aggregation errors: Flawed synthesis of information.
LettuceDetect addresses these hallucination challenges through its innovative token-level classification approach that we have successfully adapted for Turkish language applications. Unlike traditional hallucination detection methods that struggle with context window limitations and computational inefficiency, our Turkish adaptation builds on ModernBERT's extended context capabilities (up to 8,192 tokens) and rotary positional embeddings (RoPE) to effectively process Turkish text.
The framework's key contribution lies in its ability to analyze each token within its full contextual relationship to source documents, providing precise hallucination detection at the token level. This contextual awareness, combined with the model's efficiency (processing 30-60 examples per second), makes it highly suitable for Turkish RAG systems where accurate grounding of generated content is crucial.
By fine-tuning encoder models specifically on Turkish data while maintaining computational efficiency, our adaptation of LettuceDetect provides a practical solution for hallucination detection in Turkish RAG applications, filling a critical gap in multilingual AI safety tools.
Turk-LettuceDetect: A Three-Pronged Solution
We adapted three encoder architectures to tackle Turkish hallucinations:
- ModernBERT: A Turkish-specific BERT variant with rotary positional embeddings (RoPE) for handling long contexts (up to 8,192 tokens).
- TurkEmbed4STS: Optimized for semantic similarity in Turkish.
- EuroBERT: A multilingual BERT pretrained in 15 languages on 5 trillion-token dataset.
Dataset: RAGTruth-TR
We translated the English RAGTruth benchmark (17,790 training, 2,700 test instances) into Turkish using Gemma3-27b-it, preserving hallucination annotations. This dataset spans:
- Question Answering: MS MARCO-derived with 3 retrieved passages per query.
- Data-to-Text Generation: Yelp for business reviews.
- Summarization: CNN/Daily Mail news.
Each answer is labeled at the token level (e.g., <HAL>Evident Conflict</HAL>) to identify unsupported claims. To ensure accurate preservation of hallucination annotations during translation, we used a carefully designed prompt shown in Figure 1 that maintains the exact positioning and count of tags. The complete translation of the entire dataset took 12 hours to complete using Gemma3-27b-it.

Figure 1: Core Translation Prompt used for translation of RAGTruth Dataset
How It Works: Token-Level Hallucination Detection
This approach transforms hallucination detection into a sophisticated binary token classification task that operates at the granular level of individual tokens. The architecture employs a systematic pipeline designed to identify unsupported claims with high precision:
- Input Processing & Concatenation: The system processes context-question-answer triplets by concatenating them into a single sequence using special separator tokens ([CLS] for context, [SEP] for separation). This unified representation allows the encoder to capture complex relationships between the source material and generated responses, with sequences tokenized to a maximum length of 4,096 tokens.
- Encoder Analysis & Contextual Understanding: Our three encoder architectures (ModernBERT, TurkEmbed4STS, EuroBERT) analyze the concatenated sequence through their transformer layers, building rich contextual representations that capture semantic relationships between context documents, questions, and answer tokens. The encoders leverage their pretrained knowledge of Turkish language patterns to understand nuanced textual relationships.
- Strategic Token Masking: A critical aspect of our approach involves masking context and question tokens (label=-100) during training, ensuring the model focuses exclusively on classifying answer tokens. This targeted approach prevents the model from learning to classify irrelevant portions of the input while maintaining access to full contextual information for decision-making.
- Binary Classification & Probability Output: Each answer token passes through a classification head that outputs probabilities for two classes: supported (0) or hallucinated (1). The model predicts hallucination probabilities for each token based on its relationship to the provided context and question, enabling fine-grained detection of unsupported claims.
- Span-Level Aggregation: For practical applications, consecutive tokens exceeding a 0.5 confidence threshold are aggregated into hallucinated spans, providing users with coherent segments of problematic text rather than isolated token-level predictions. This aggregation maintains the granular detection capability while presenting results in an interpretable format.
Training Configuration
Training was conducted for 6 epochs with a learning rate of 1e-5 and batch size of 4 on NVIDIA A100 GPUs.

Figure 2: Installation of LettuceDetect Framework
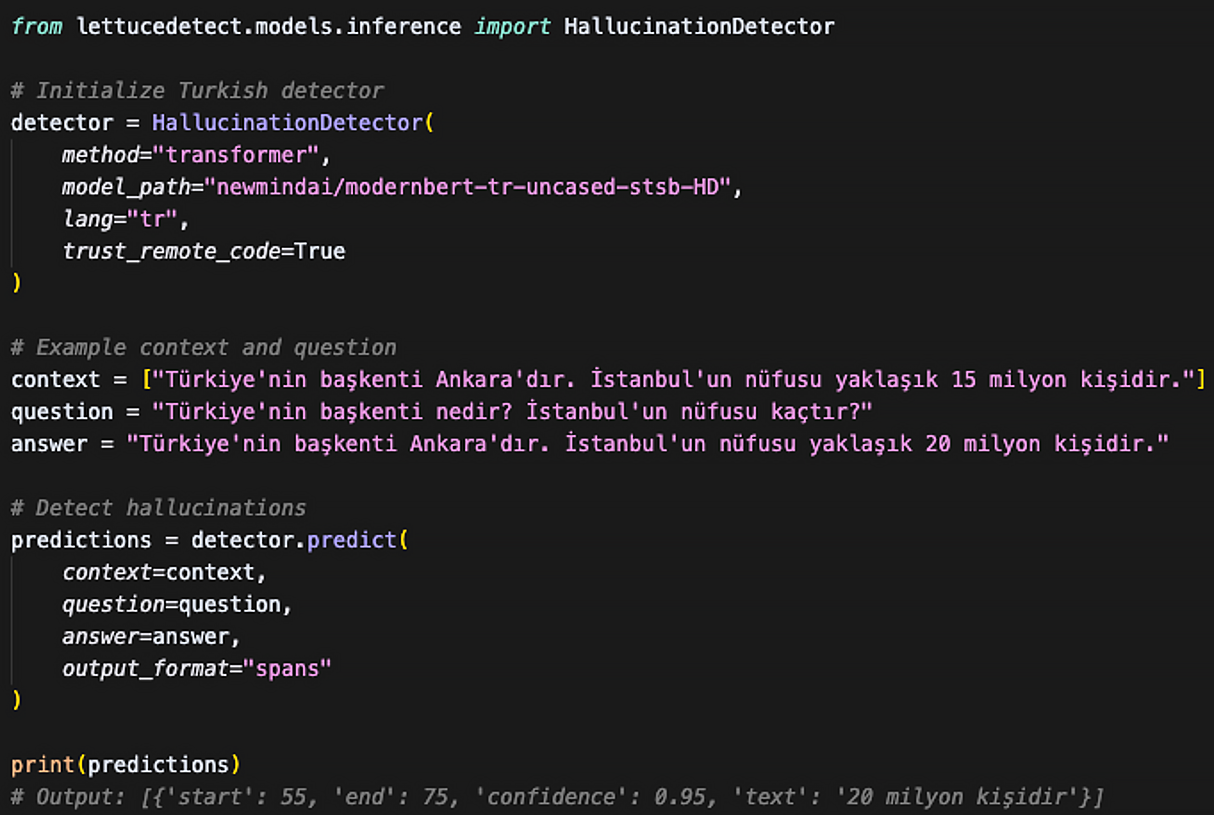
Figure 3: Basic Usage Example of Turkish Hallucination Detection Model
Results: Outperforming LLMs
Our models set a new bar for Turkish hallucination detection:
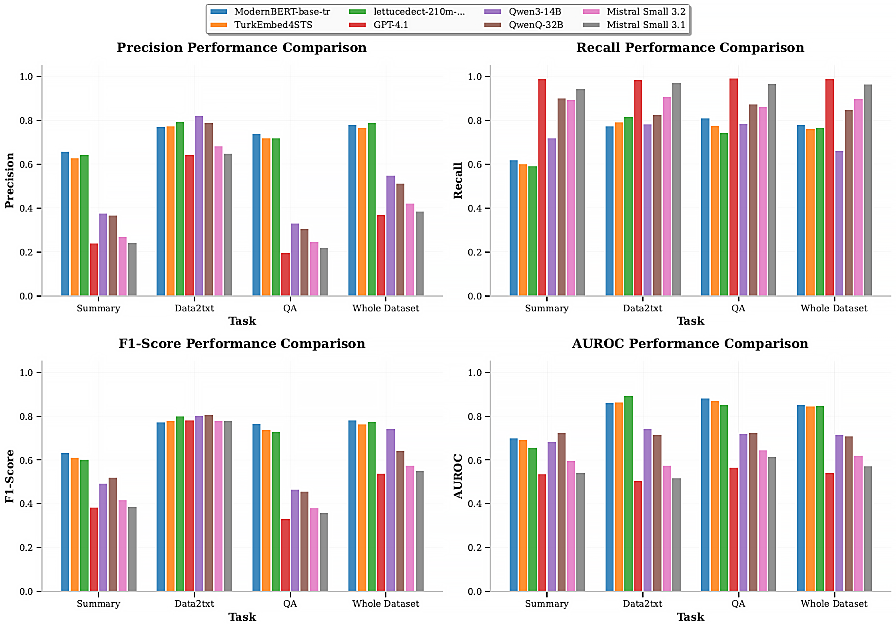
Figure 4: Performance of example-level hallucination detection across models
Our experimental results shown in Figure 4 demonstrate the superior efficacy of specialized encoder models for Turkish hallucination detection over general-purpose LLMs. The core issue with LLM baselines like GPT-4.1 and Mistral is their extreme precision-recall imbalance. While achieving nearly perfect recall (over 0.95), their precision is exceptionally low (often below 0.25), meaning they incorrectly flag vast amounts of valid content. This tendency, confirmed by poor AUROC scores hovering around 0.5-0.6, renders them unreliable for practical deployment.
In stark contrast, our fine-tuned models offer a far more balanced and effective solution. ModernBERT-base-tr emerges as the top performer, delivering the highest overall F1-score (0.7821) and AUROC (0.8546), underscoring the value of domain-specific pretraining. Our other adapted encoders also significantly outperform the LLMs across all balanced metrics. While some LLMs like Qwen show isolated strengths, they cannot resolve the fundamental trade-off issue. These findings confirm that lightweight, task-specific models provide a more reliable and deployable solution for hallucination detection than large, general-purpose LLMs.
Our Mind
Hallucination detection is a crucial step toward building trustworthy AI systems, especially for morphologically rich and low-resource languages like Turkish. Our work with Turk-LettuceDetect demonstrates that targeted, language-specific adaptations significantly outperform general-purpose models in balancing precision and recall. By focusing on token-level analysis and leveraging advanced encoder architectures like ModernBERT, we provide a practical and efficient solution tailored to the unique challenges of Turkish.
We believe that this approach not only fills a critical gap in multilingual AI safety but also sets a foundation for future research in other low-resource languages facing similar obstacles. The combination of rich contextual understanding and computational efficiency makes Turk-LettuceDetect well-suited for real-time deployment in Retrieval-Augmented Generation pipelines, which are becoming increasingly central to AI applications.
Looking ahead, continuous refinement through expanding datasets, incorporating user feedback, and integrating hybrid model strategies can further enhance hallucination detection capabilities. Our commitment is to foster open research and development in this space, empowering communities and organizations to build AI systems that are both powerful and reliable across diverse languages and domains.
Key Takeaways
- ModernBERT Dominance: Best F1 in QA (0.7588) and summarization (0.6007), leveraging Turkish-specific fine-tuning.
- TurkEmbed4STS Consistency: Maintains balanced precision/recall across tasks.
- LLM Weaknesses: GPT-4.1/Mistral show high recall (up to 0.9938) but low precision, underscoring the need for dedicated detectors.
- Specialized Encoders are Superior: Fine-tuned encoder models consistently outperform general-purpose LLMs by providing a balanced and reliable solution, proving that a targeted, specialized approach is essential for effective hallucination detection.
- Deployment-Ready Performance: Our models are not just accurate but also efficient. With support for long contexts (8,192 tokens) and fast inference, they are practical for real-time RAG pipelines where both speed and reliability are critical.
Ready to try Turk-LettuceDetect Models? Explore our models and RAGTruth-TR dataset on Hugging Face.
Turkish Hallucination Detection ModelsReferences
- Kovács, Á., & Recski, G. (2025). Lettucedetect: A hallucination detection framework for rag applications. arXiv preprint arXiv:2502.17125.
- Warner, B., Chaffin, A., Clavié, B., Weller, O., Hallström, O., Taghadouini, S., ... & Poli, I. (2024). Smarter, better, faster, longer: A modern bidirectional encoder for fast, memory efficient, and long context finetuning and inference. arXiv preprint arXiv:2412.13663.
- artiwise-ai/modernbert-base-tr-uncased · Hugging Face. (2024, December 16). //huggingface.co/artiwise-ai/modernbert-base-tr-uncased
- Boizard, N., Gisserot-Boukhlef, H., Alves, D. M., Martins, A., Hammal, A., Corro, C., ... & Colombo, P. (2025). EuroBERT: scaling multilingual encoders for European languages. arXiv preprint arXiv:2503.05500.
- Zhang, X., Zhang, Y., Long, D., Xie, W., Dai, Z., Tang, J., ... & Zhang, M. (2024). mgte: Generalized long-context text representation and reranking models for multilingual text retrieval. arXiv preprint arXiv:2407.19669.