Avoiding Specific Languages in Language Models Using Logit Processors
Our latest research explores Unicode-aware filtering in Qwen-32B and Qwen2.5-72B, enabling precise suppression of languages like Chinese, Arabic, or Cyrillic—without degrading performance.

Avoiding Specific Languages in Language Models Using Logit Processors
As multilingual LLMs expand, controlling their output across scripts and languages becomes critical for domain-specific applications.
Our latest work explores language filtering in Qwen-32B using logits_processor, enabling suppression of undesired character sets like Chinese, Arabic, or Cyrillic during text generation.
The study includes detailed analyses of tokenization behaviors, Unicode-level representations, and how BPE tokenizers handle languages like Turkish.
We compare filtering approaches—logits_processor vs allowed_token_ids—highlighting trade-offs in flexibility, performance, and use cases.
Benchmark results show that language-specific token suppression yields clean, controllable outputs without compromising performance, even at scale with models like Qwen2.5-72B.
Token Representation and Conversion
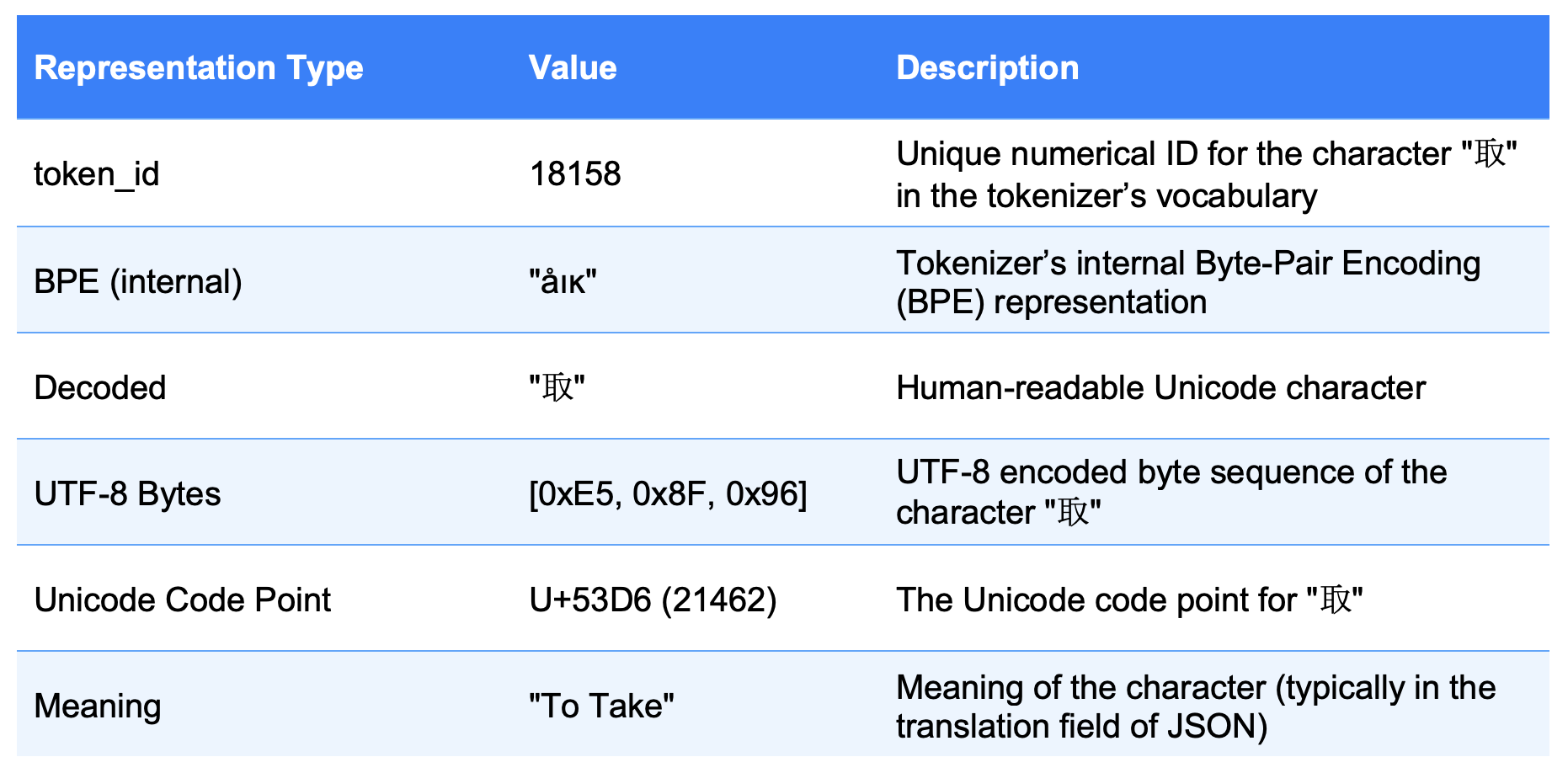
Language models don't interpret characters visually (e.g., Chinese "取"). Instead, they convert text through internal layers: embeddings and token IDs. Understanding these representations is crucial for tasks like Unicode filtering, depending on how models tokenize and encode text internally.
Let’s examine how the character "取" is represented within the model:
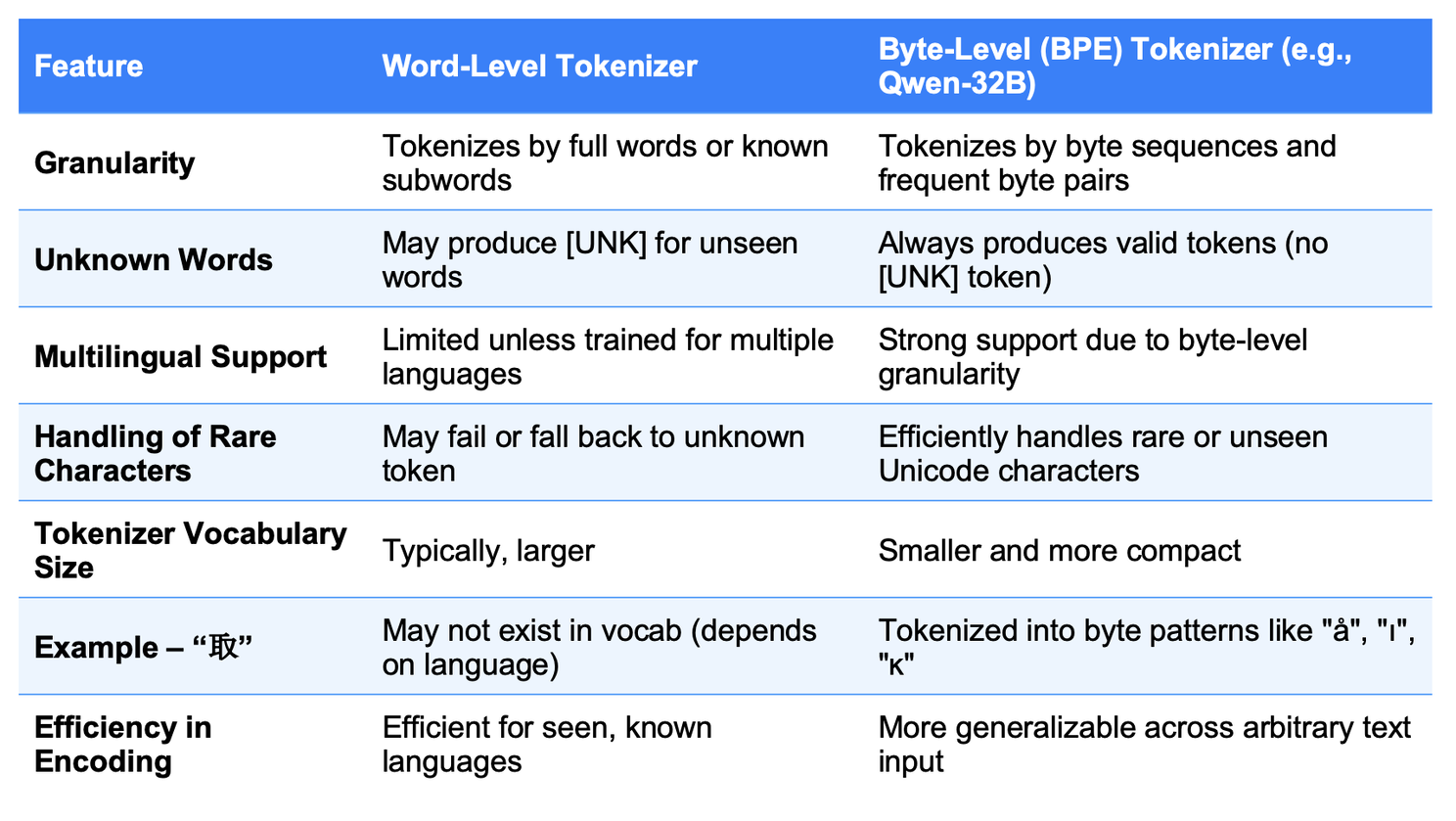
Word-Level vs. Byte-Level Tokenizer Comparison
The table compares traditional word-level tokenizers with byte-level methods (like Qwen-32B's BPE), showing how the latter allows for more flexible and effective Unicode-based language filtering.
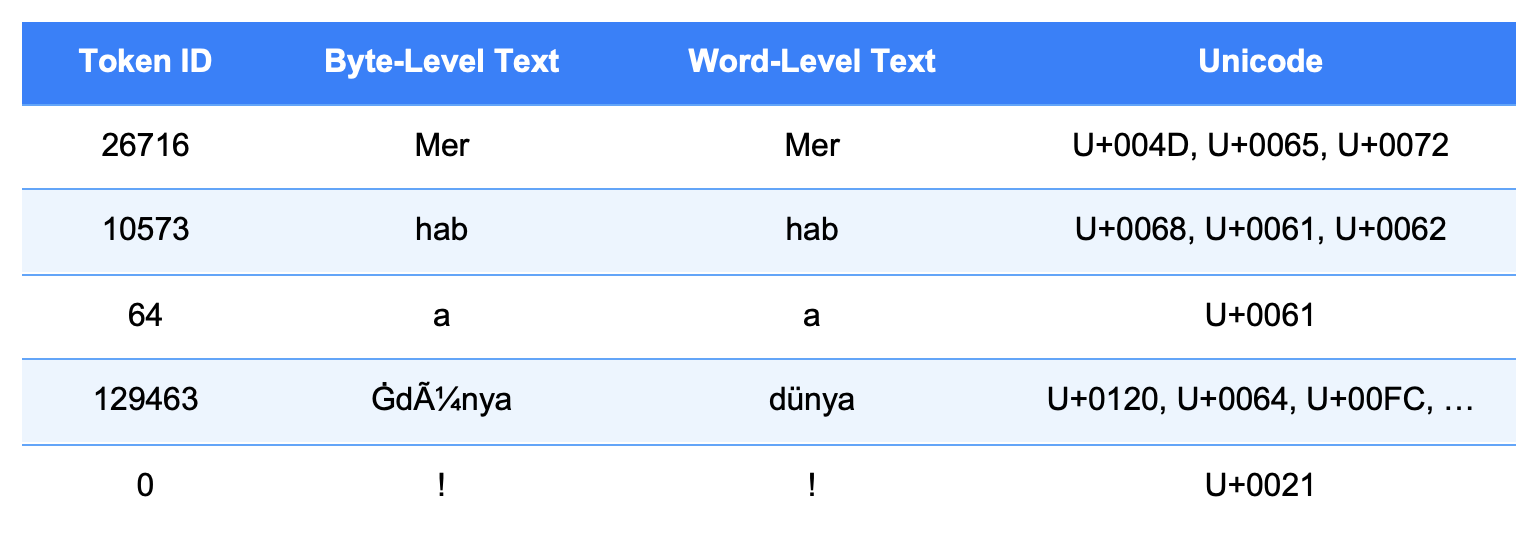
Example Sentence and Token Correspondences in Model Tokenization
This table displays token IDs, raw/normalized forms, byte representations, and Unicode points for a sample sentence, showing how the model processes text internally.
Example Sentence: Merhaba Dünya!
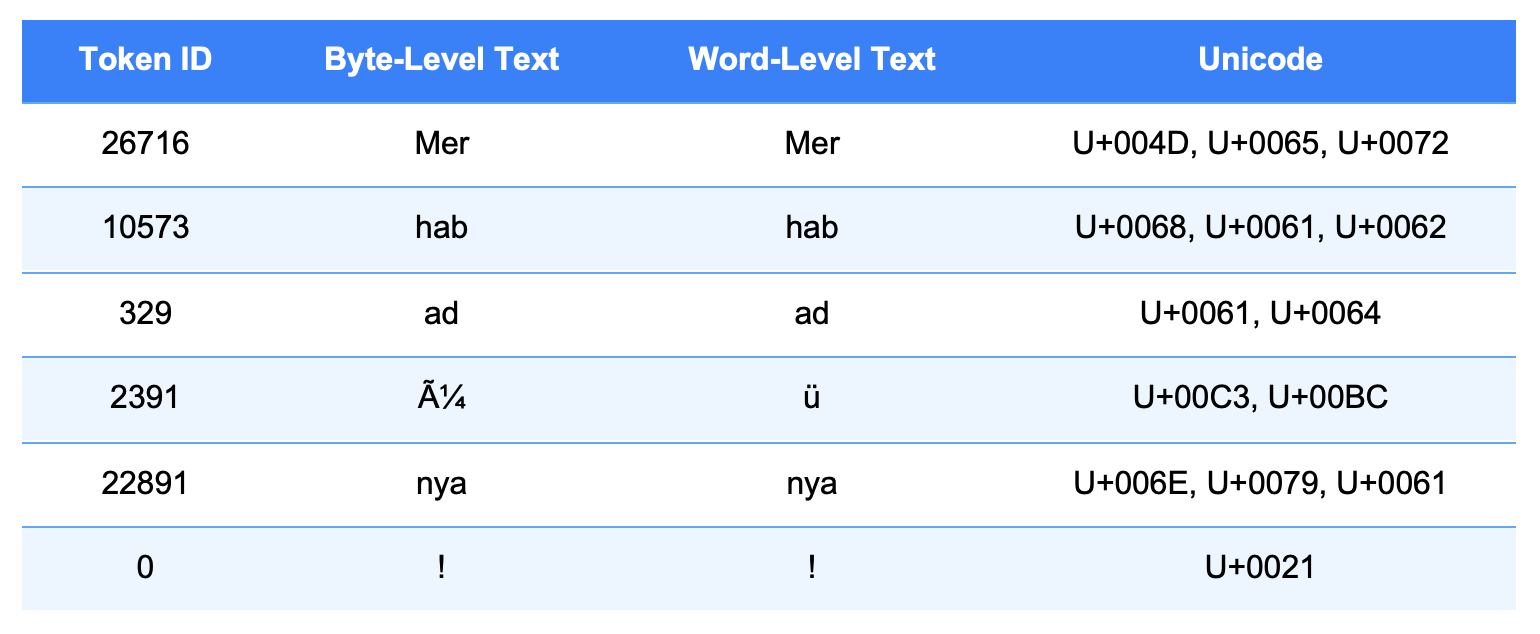
The table shows how a sentence is tokenized by the model. For example, the character "Ġ" in "Ġdünya" indicates a space before the word. Therefore, " dünya" (with a leading space) and "dünya" (without a space) are treated as different tokens. The table includes each token’s original form (Byte-Level Text), its decoded form (Word-Level Text), byte sequence, and Unicode code points. Even small changes—like adding a space or merging words—can affect the resulting tokens, as each detail influences tokenization.
What Does logits_processor Do?
The logits_processor modifies the model's logits during generation, allowing suppression of tokens from specific character sets to prevent their selection. In Qwen-32B on vLLM, multiple processors can be combined in a list and passed to the SamplingParams object to control decoding behavior.
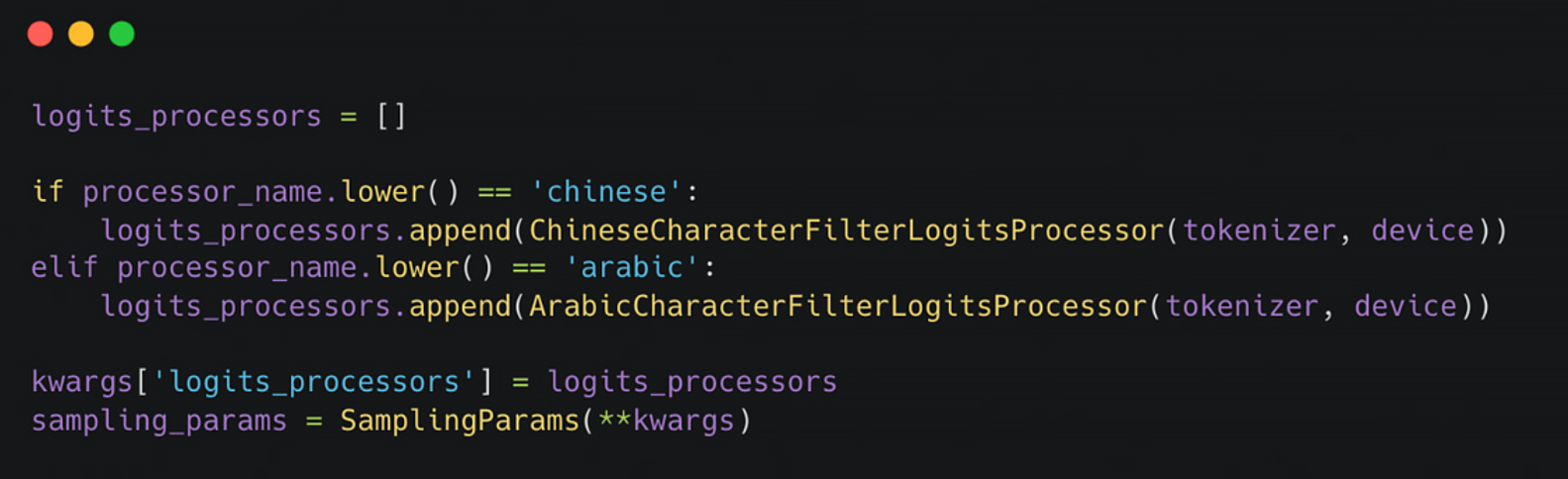
Example Usage in VLLM:
In vLLM, you can apply multiple logits_processor filters simultaneously. For example, to block tokens from Chinese and Arabic scripts, you can define separate processors for each and add them to a list, which is then passed to the SamplingParams object. Each processor sets the logits of unwanted tokens to -inf, effectively eliminating them from the sampling distribution and preventing their selection during text generation.
Filtering Tokens Made of Only Whitespace Using Unicode
Language models sometimes generate meaningless tokens made up of only whitespace characters. This processor detects and filters such tokens to encourage more meaningful output.
Filtering Criteria:
- A token is filtered if:
- It is non-empty,
- It consists only of whitespace characters (' ', \t, \n, etc.),
- It is not in the predefined list of necessary token IDs.
Necessary Token IDs:
Certain whitespace tokens—such as \t\n or space\r\n—are important for maintaining formatting and structure, so they are excluded from filtering. To apply the filter, the entire vocabulary is first decoded. A mask is then created to identify tokens made up solely of whitespace characters, excluding the necessary ones. Tokens that match the filtering criteria have their logits set to -inf, effectively removing them from the model’s output during generation.
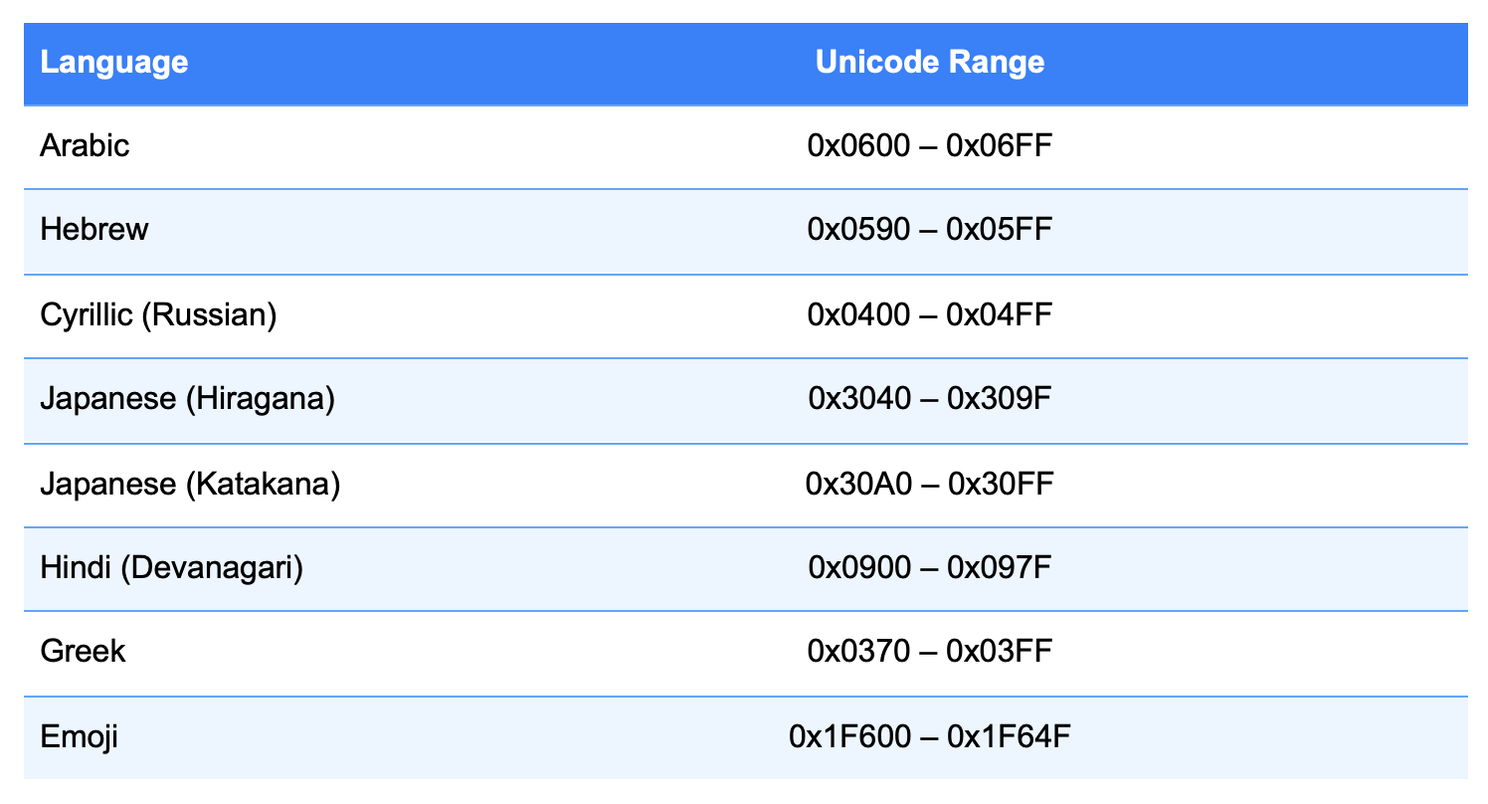
Other Languages and Unicode Ranges
The ranges below can be easily filtered using logits_processor:
These results show the effectiveness of using logits_processor in filtering out unwanted characters
CJK Character Filtering Benchmark Results
The Qwen2.5-72B-Instruct model uses a logits_processor to filter out Chinese, Japanese, and Korean (CJK) characters from its output, producing cleaner results without compromising performance.
In fact, our model outperforms the base model in our Mezura benchmarks—achieving an Auto ELO Score of 1310.17 and 87% accuracy on Turkish semantic tasks.
Alternative Token Filtering Method: allowed_token_ids
One of the simplest ways to constrain a language model’s output is by using the allowed_token_ids parameter. This method enforces a strict whitelist of token IDs that the model is permitted to generate. During each generation step, the model computes logits (unnormalized probabilities) for all tokens in the vocabulary. Any token not included in the allowed_token_ids list has its logit set to -inf, effectively reducing its probability to zero. As a result, the model can only produce tokens from the predefined allowed list.
Comparison: allowed_token_ids vs logits_processors
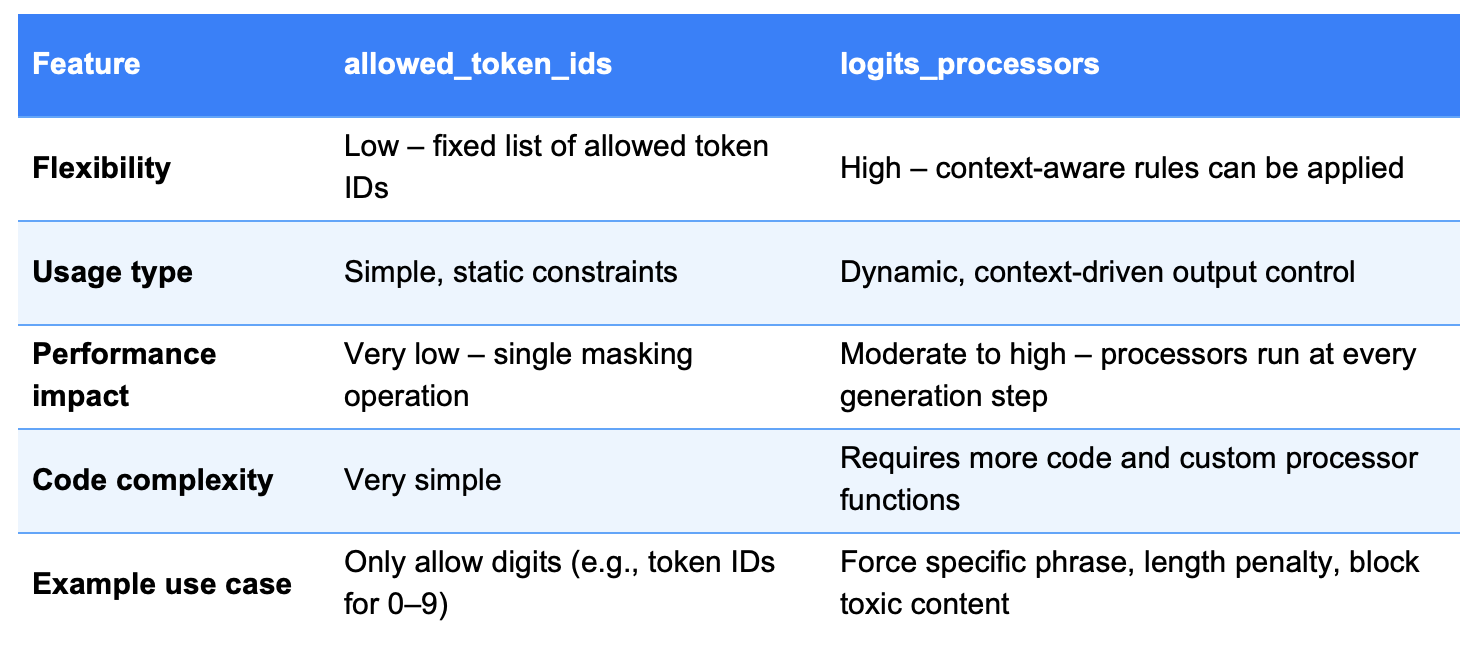
When to Use Which?
Use allowed_token_ids when:
- Fixed token sets (digits, predefined choices)
- Performance-critical lightweight apps
- Static, known valid outputs
Use logits_processors when:
- Dynamic control rules (forced words, minimum length)
- Structured or semantically meaningful output
- Context-based behavior shaping
Example: Generate Output Using Only Numbers and Punctuation
Purpose: Restrict the model to generate only digits and basic punctuation in response to “Generate a sequence of numbers”.
Benefits:
- Controlled output: Blocks irrelevant text.
- Safe generation: Limits output to allowed characters (ideal for codes, IDs, prices).
- Efficient: allowed_token_ids is fast with low overhead.
- Structured: Ensures clean, consistent numeric sequences.

This setup is especially useful in cases like:
- Generating numeric-only reports or values,
- Chatbots that must return codes, scores, or monetary amounts,
- Forcing the model to stay within valid number formats.
Our Mind
Language filtering through logit processors represents a fundamental shift toward more controlled and responsible AI text generation. Our exploration of token-level filtering mechanisms demonstrates that precise control over model outputs is not only possible but essential for creating reliable, culturally sensitive AI systems. By leveraging byte-level tokenization and Unicode-aware filtering, we can prevent unwanted language generation while maintaining model performance and flexibility.
We believe this approach addresses critical challenges in multilingual AI deployment, particularly in scenarios where content must comply with specific linguistic requirements or regulatory constraints. The ability to filter out entire language scripts or character sets while preserving semantic coherence opens new possibilities for region-specific AI applications and content moderation systems.
Looking forward, the combination of logit processors with advanced sampling techniques will enable even more sophisticated control mechanisms. Our commitment is to advance research in controllable text generation, ensuring that language models can be deployed responsibly across diverse global contexts while respecting linguistic boundaries and cultural sensitivities.
Key Takeaways
- Effective Language Filtering: Successfully blocks 20.37% of Chinese tokens, 2.65% Arabic, and 2.73% Cyrillic characters without performance degradation.
- Byte-Level Advantage: BPE tokenization handles unknown characters better than word-level approaches, eliminating [UNK] tokens entirely.
- Multiple Filter Support: vLLM allows simultaneous application of multiple logit processors for comprehensive language control.
- Performance Preservation: Benchmark results show nearly identical performance to original models when using character filtering.
- Flexible Implementation: Choice between simple allowed_token_ids for static constraints and dynamic logits_processors for context-aware filtering based on specific use case requirements.