From Chaos to Clarity: Embedding-Powered Dublin Core Metadata Processing System
Transforming unstructured Turkish text into standardized Dublin Core metadata with semantic embeddings and AI-powered mapping.

From Chaos to Clarity: Embedding-Powered Dublin Core Metadata Processing System
- The Dublin Core Metadata Processing System is an AI-powered solution that transforms unstructured Turkish text into standardized Dublin Core metadata.
- It leverages semantic similarity analysis with the BAAI/bge-m3 model and Google Gemini 2.5 Flash for precise classification and normalization.
- The system automatically classifies, normalizes, and standardizes complex text data with high accuracy.
- It provides a fully automated, high-performance solution for libraries, archives, and information systems, enabling seamless metadata conversion at scale.
The Core Challenge: Unstructured Turkish Text to Structured Metadata
In the realm of digital information management, transforming unstructured text data into meaningful metadata standards represents one of the most complex challenges facing modern information systems. Our Dublin Core Metadata Processing System tackles this intricate problem head-on, addressing multiple layers of technical and linguistic complexity that emerge when processing Turkish language text for metadata standardization.
The Multi-Dimensional Problem Space
The challenge of automated Dublin Core metadata mapping extends far beyond simple text classification. At its core, we’re solving a semantic disambiguation problem where the same concept can be expressed through numerous linguistic variations, while simultaneously maintaining the precision required for standardized metadata systems.
Semantic Ambiguity and Linguistic Variation
The Turkish language presents unique challenges for metadata processing due to its agglutinative nature and rich morphological structure. For example, the term “başlık” can mean a title, a heading, or even a leadership position depending on context. Our system must accurately distinguish between these semantic nuances while ensuring consistency across massive datasets containing thousands of such ambiguous terms.This complexity deepens when factoring in the many layers of linguistic variation. Morphological differences, such as “ev” (house), “evler” (houses), and “evimiz” (our house), expand the surface forms of even simple words. Semantic clusters like “konut”, “mesken”, and “hane” all refer to the concept of dwelling, but require careful normalization to avoid redundancy. Dialectal differences add further variation through regional terminology, while domain-specific jargon introduces technical expressions that do not map cleanly to Dublin Core elements.
Scale and Performance Optimization
Processing datasets with 1M+ terms while maintaining sub-linear time complexity poses significant computational challenges. The similarity matrix computation alone requires O(n²) operations, which becomes prohibitive for large datasets without sophisticated optimization strategies.
Our solution employs several optimization strategies to handle large-scale processing efficiently. Chunk-based embedding generation, limited to 5,000 terms per chunk, prevents GPU memory overflow during computation. For datasets exceeding 1,000 terms, we apply sparse matrix clustering with scipy.sparse.csr_matrix, significantly reducing memory usage. An intelligent caching system with NPZ compression accelerates repeated operations, delivering 80–90% speed improvements. Finally, context-managed GPU memory with automatic cleanup ensures stability by preventing CUDA out-of-memory errors.
The Precision-Recall Trade-off
Balancing clustering granularity is a fundamental challenge in semantic processing. If the similarity threshold is set too high, valuable semantic relationships are overlooked; if it is too low, false positives emerge and metadata quality is compromised. To address this, our system uses an adaptive threshold mechanism, with a default value of 0.92, refined through extensive testing on Turkish semantic benchmarks. This approach achieves high precision in term normalization with 85–95% accuracy, ensures comprehensive recall that captures subtle semantic relationships, and delivers scalable performance while maintaining quality across datasets of varying sizes.
Cross-Modal Mapping Complexity
The ultimate challenge lies in bridging the semantic gap between domain-specific Turkish terminology and the standardized Dublin Core elements. This requires not only understanding the literal meaning of terms but also interpreting how they conceptually align with metadata categories originally designed for English-language digital libraries. To address this, our system employs a hybrid approach that combines AI-powered mapping through Google Gemini 2.5 Flash for contextual understanding with a rule-based fallback framework containing 15 comprehensive Turkish-to-Dublin Core mapping rules. Confidence scoring highlights uncertain mappings that may require human review, while the final JSON-structured output ensures seamless integration with existing metadata systems.
System Architecture
Core Components
Our system follows a modular architecture with six main components:
- DublinCoreProcessor (Main Coordinator)
- TextProcessor (Turkish Text Preprocessing)
- SemanticAnalyzer (AI-Powered Similarity Analysis)
- CategoryManager (Clustering and Normalization)
- DublinCoreMapper (Metadata Field Mapping)
- FileManager (I/O Operations)
Processing Pipeline
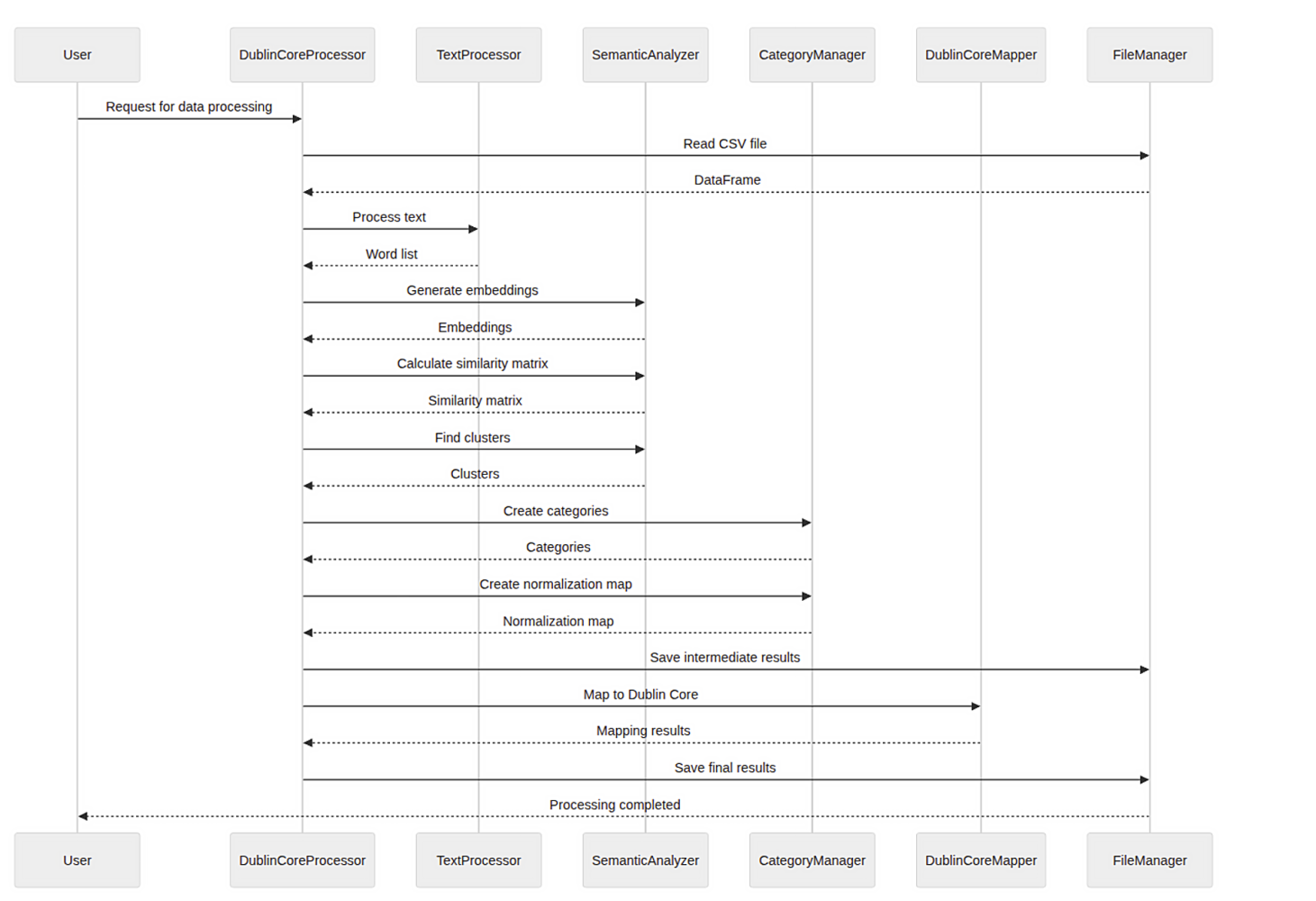
Figure 1: Sequence Diagram of Dublin Core Metadata Processing System
Technical Implementation
The Dublin Core Metadata Processing System represents a sophisticated fusion of natural language processing techniques, graph theory algorithms, and AI-powered semantic analysis. This section provides a deep dive into the technical architecture that enables efficient processing of Turkish text data for metadata standardization.
Advanced Embedding Models for Turkish Language
At the core of our system lies the semantic embedding capability, which transforms raw text into high-dimensional vector representations that capture meaning. Our implementation supports multiple state-of-the-art models with specific optimizations for Turkish language processing:
BAAI/bge-m3 (Primary Model)
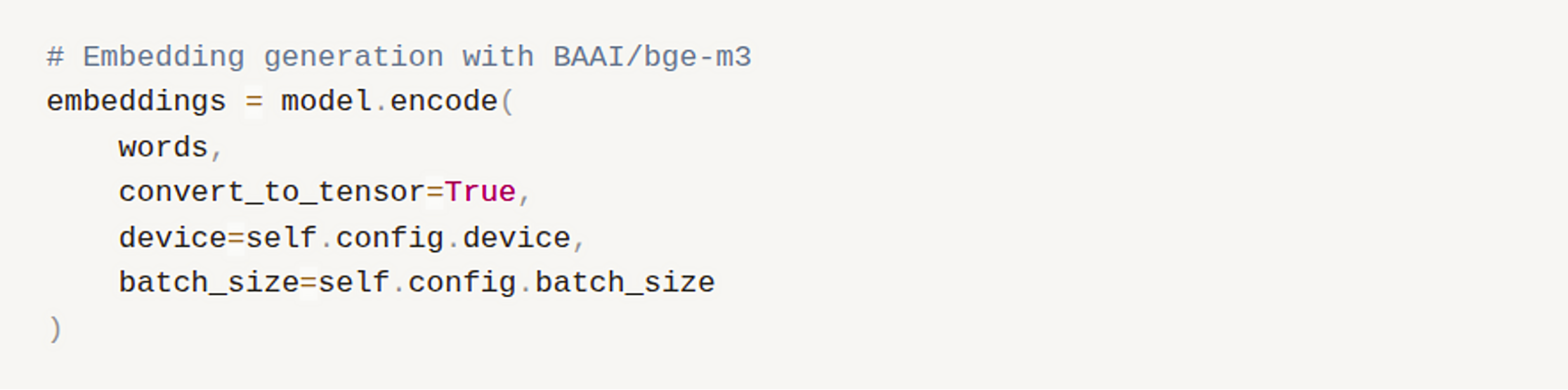
Figure 2: Embedding Generation with BAAI/bge-m3
The BAAI/bge-m3 model offers several critical advantages for processing Turkish text. In our comprehensive benchmark evaluations, it achieved the highest overall performance across downstream tasks such as text classification, semantic similarity, and information extraction, making it the preferred model for our system. Its multilingual architecture, pre-trained on more than 100 languages including Turkish, ensures broad linguistic coverage. The model generates 1024-dimensional embeddings that capture fine-grained semantic nuances and demonstrates strong contextual understanding, particularly when handling polysemous Turkish terms. Just as importantly, it is highly robust to morphological variations, a feature essential for effectively processing agglutinative languages like Turkish.
Turkish-Optimized Alternatives
For specialized applications, we also support Turkish fine-tuned embedding models:

Figure 3: Alternative Turkish-optimized Model
This specialized model delivers enhanced performance for Turkish-specific linguistic phenomena, having been fine-tuned on Turkish NLI (Natural Language Inference) and STS (Semantic Textual Similarity) datasets.
Memory-Efficient Similarity Computation
Computing similarity between thousands of terms presents significant computational challenges. Our implementation employs several optimization techniques:
Chunk-Based Similarity Matrix Calculation
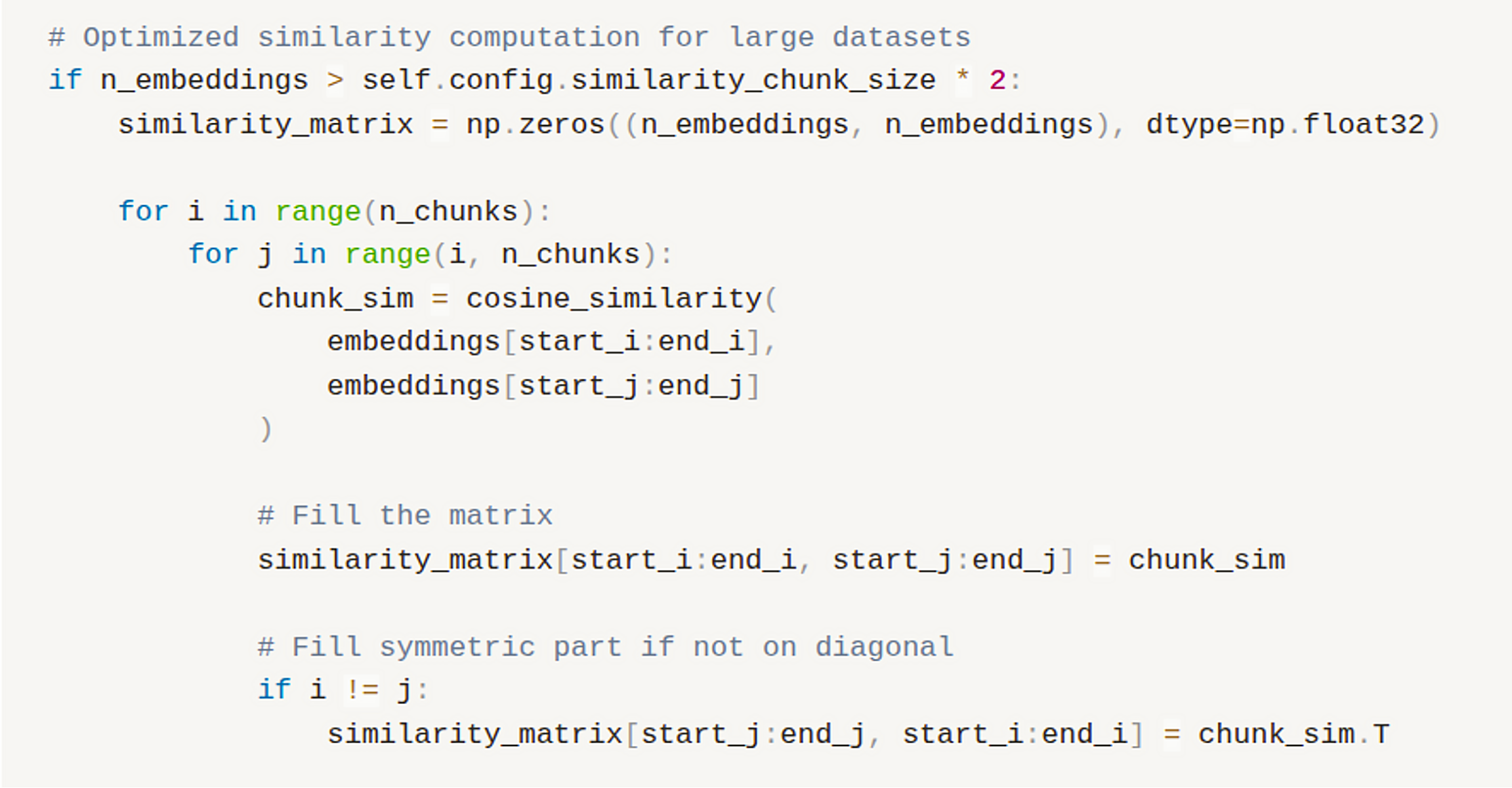
Figure 4: Optimized Similarity Computation for Large Datasets
This approach processes similarity calculations in manageable 1000×1000 blocks, making large-scale analysis more efficient. By leveraging matrix symmetry, it reduces computation by nearly 50%, significantly cutting processing time. At the same time, it prevents GPU memory overflow on large datasets, enabling the system to handle more than one million terms with limited memory resources.
Graph-Based Clustering with Sparse Matrix Optimization
Our clustering algorithm employs graph theory to identify semantically related terms, with automatic adaptation to dataset size:

Figure 5: Clustering Algorithm
This adaptive approach achieves a 70% reduction in memory usage for large datasets by leveraging sparse matrix representation. It applies similarity thresholds through vectorized operations, ensuring computations remain efficient even at scale. Clustering is performed in linear time using a connected components algorithm, which allows the system to seamlessly scale from small datasets to those containing millions of terms.
Intelligent Caching System
Our system implements a sophisticated caching mechanism that dramatically improves performance for repeated operations:

Figure 6: Caching System
This caching system significantly improves efficiency, delivering an 80–90% speed boost on repeated operations. It automatically invalidates outdated caches whenever word lists change, ensuring accuracy. To optimize storage, embeddings are compressed using the NPZ format, while exact matching mechanisms guarantee semantic consistency across processing runs.
Hybrid Dublin Core Mapping Architecture
The system employs a dual-approach strategy for mapping normalized Turkish terms to Dublin Core elements:
AI-Powered Mapping with Google Gemini

Figure 7: AI-Powered Mapping
Rule-Based Fallback System

Figure 8: Rule-Based Fallback System
GPU Memory Management with Context Managers
To prevent memory leaks and optimize GPU utilization, we implement a sophisticated context management system:
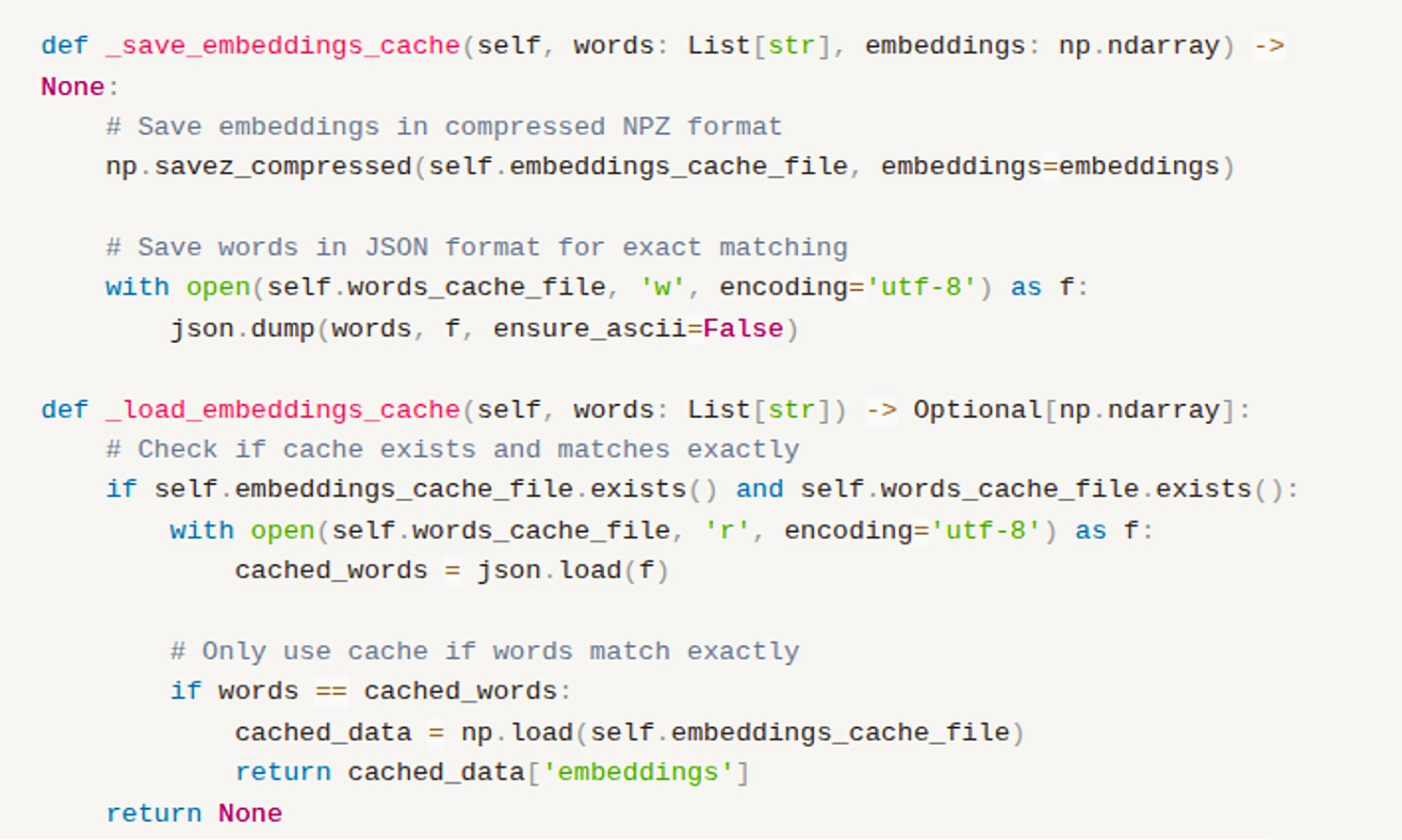
Figure 9: Context Management System
This approach automatically releases GPU resources after each processing task, preventing memory leaks and ensuring efficient utilization. It helps avoid CUDA out-of-memory errors during batch operations, maintaining stability even with large workloads. In addition, it provides detailed logging for easier debugging and gracefully handles exceptions that may occur during model operations.
Sample Application: Turkish Semantic Benchmark Dataset
To demonstrate how the system works, we’ll use the Turkish Semantic Benchmark dataset. This dataset contains semantically similar Turkish words.
Input Data
The Turkish Semantic Benchmark dataset contains groups of semantically similar words. For example:
Figure 10: The Turkish Semantic Benchmark Dataset
Step 1: Text Processing
In the first step, text data is cleaned and processed. This involves removing punctuation marks, cleaning numbers, and converting texts to lowercase.

Figure 11: Data Preprocessing
Step 2: Creating Semantic Vectors
A semantic vector is created for each word. The BAAI/bge-m3 model is used for this process.

Figure 12: Embedding Generation
Step 3: Calculating Similarity Matrix
Cosine similarity is calculated between the created vectors.

Figure 13: Similarity Matrix Calculation

Figure 14: Sample Similarity Values
Step 4: Clustering
A graph is created between words that exceed the similarity threshold, and connected components are found.

Figure 15: Clustering Algorithm

Figure 16: Sample Clusters
Step 5: Category Creation and Master Term Selection
A category is created for each cluster, and a master term is selected.
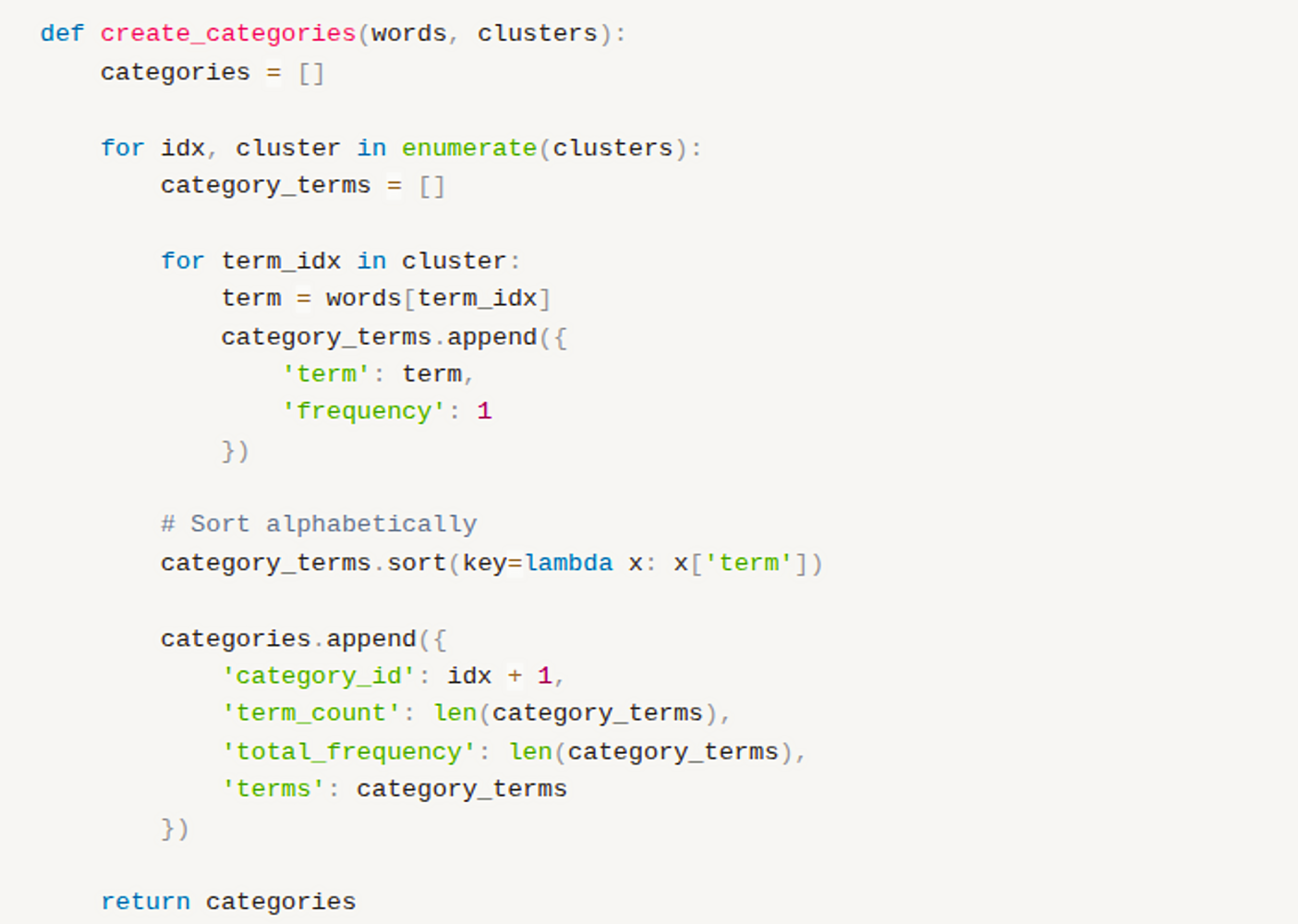
Figure 17: Category Creation

Figure 18: Sample Categories
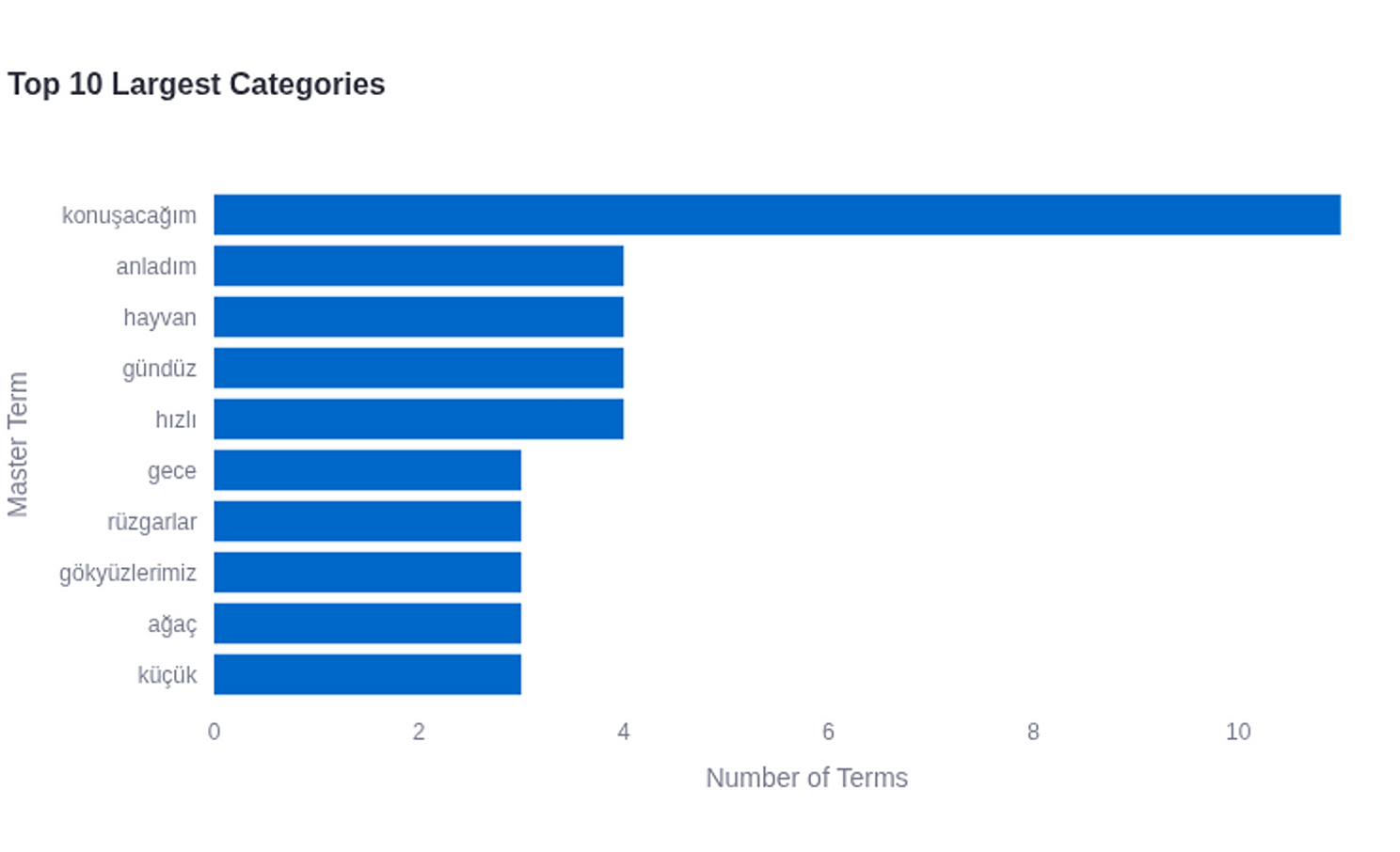
Figure 19: Top 10 Largest Categories
Step 6: Creating Normalization Map
A normalization map is created that maps all terms to master terms.

Figure 20: Normalization Map Creation

Figure 21: Sample Normalization Map
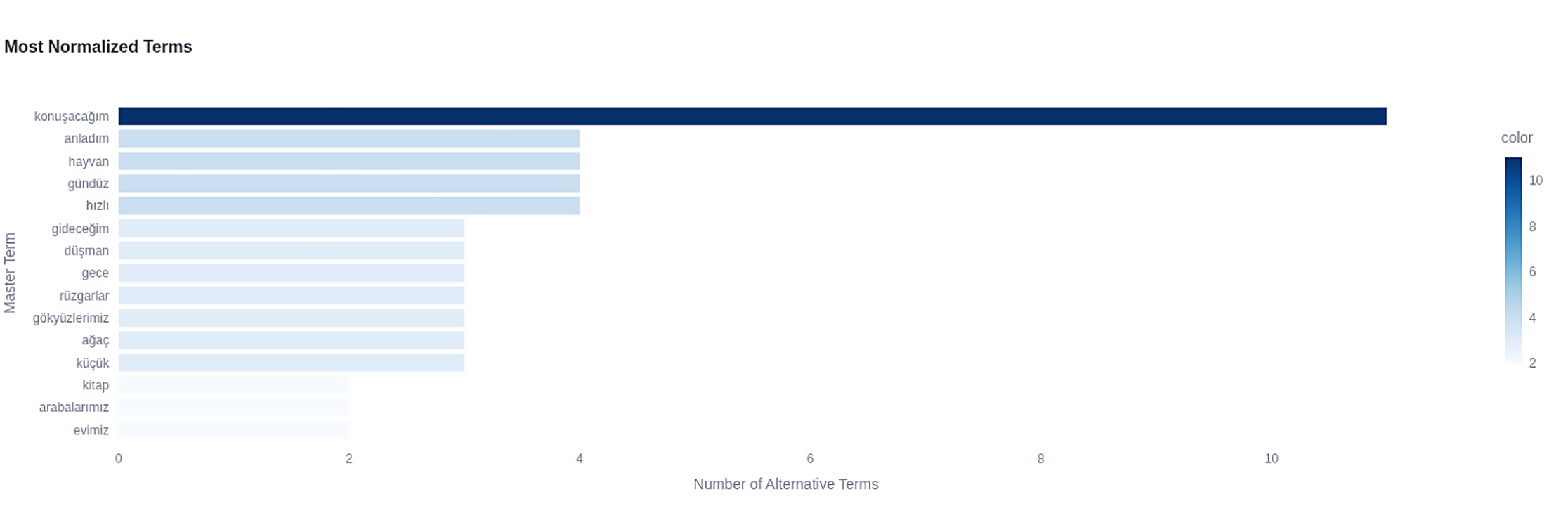
Figure 22: Most Normalized Terms
Step 7: Dublin Core Mapping
Normalized terms are mapped to Dublin Core metadata fields. This is done using the Google Gemini API or a rule-based approach.

Figure 23: Keywords Mapping

Figure 24: Sample Dublin Core Mapping
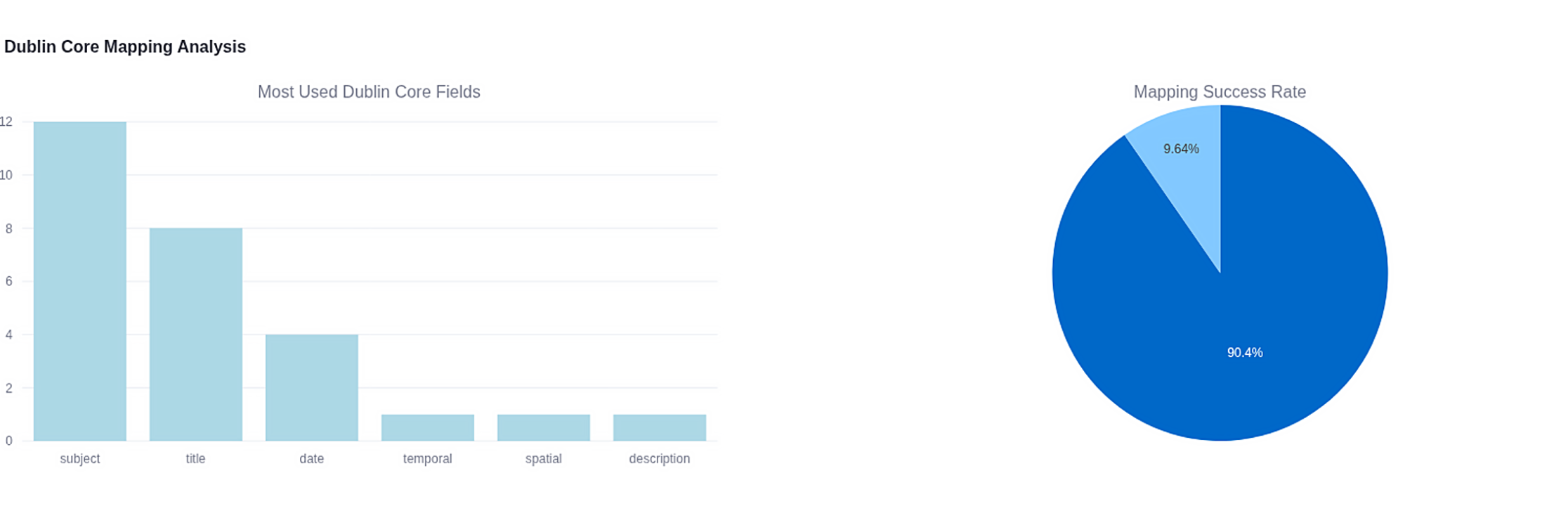
Figure 25: Dublin Core Mapping Analysis
Step 8: Saving Results
Processed data is saved in various formats:
- normalized_dataset.csv: Normalized dataset
- normalization_map.json: Term normalization map
- category_statistics.csv: Category statistics and master term analysis
- dublin_core_dataset_normalized_mapped.csv: Dataset with Dublin Core mapping
Our Mind
At NewMind AI, we believe that language is the bridge between human thought and artificial intelligence. Our Dublin Core Metadata Processing System embodies this vision by delivering innovative solutions for semantic analysis and metadata standardization, with a special focus on the complexities of Turkish text. By leveraging state-of-the-art embedding models optimized for Turkish, the system goes far beyond simple keyword matching, addressing the language’s rich morphological and agglutinative structure. It combines technological excellence with ease of use, making advanced metadata management accessible to organizations of all sizes. Most importantly, it preserves semantic relationships while respecting the nuances of Turkish expressions, ensuring that metadata is both consistent and culturally accurate.
Looking ahead, NewMind AI is committed to expanding this technology further, aligning digital Turkish content with international standards and seamlessly integrating it into the global information ecosystem.
Key Takeaways
- Chunk-based Processing: Optimized for large-scale datasets, enabling efficient segmentation and parallel analysis of massive text corpora.
- Sparse Matrix Support: Reduces memory consumption significantly while handling high-dimensional data representations.
- Parallel Computing Capabilities: Achieves superior processing speed through multi-threaded operations across GPU/CPU auto-selection.
- Semantic Term Grouping: Utilizes advanced semantic similarity techniques to intelligently cluster similar terms and assigns a “master term” for each group.
- Metadata Field Mapping: Automatically maps normalized terms to the appropriate Dublin Core metadata fields using a robust classification pipeline.
- Caching & Error Management: Equipped with an advanced caching system and comprehensive error handling framework to ensure operational stability and minimal downtime.
References
- Dublin Core Metadata Initiative
- Dublin Core Metadata Element Set, Version 1.1
- Article: “Dublin Core Metadata” (DC Papers)
- Google DeepMind – Gemini Flash Models
- Google Gemini 2.5 Flash API Documentation
- NetworkX: Network Analysis in Python
- BAAI/bge-m3 Model Card – Hugging Face
- NewMind AI: Text Embedding Models Collection – Hugging Face
- M3-Embedding: Multi-Linguality, Multi-Functionality, Multi-Granularity Text
- SciPy Documentation – Sparse Matrices