Data-Free Evaluation of LLMs
WeightWatcher (WW) is an open-source diagnostic tool for analyzing Deep Neural Networks (DNNs) without needing access to training or test data, based on the Theory of Heavy-Tailed Self-Regularization (HT-SR) and using ideas from Random Matrix Theory, Statistical Mechanics, and Strongly Correlated Systems.

Data-Free Evaluation of LLMs
WeightWatcher (WW) is an open-source diagnostic tool for analyzing Deep Neural Networks (DNNs) without needing access to training or test data, based on the Theory of Heavy-Tailed Self-Regularization (HT-SR) and using ideas from Random Matrix Theory, Statistical Mechanics, and Strongly Correlated Systems.
The tool provides empirical quality metrics that can predict model generalization performance by analyzing the weight matrices of neural network layers through their Empirical Spectral Density (ESD) - essentially the distribution of eigenvalues in each layer's correlation matrix.
The primary goal is to find generalization metrics that accurately reflect test accuracies across different models and architectures, allowing practitioners to assess model quality, detect overfitting or underfitting in specific layers, predict test accuracies without test data, and monitor potential problems when compressing or fine-tuning models.
We use this tool to identify which pre-trained models best fit our needs without requiring any test data. This accelerates the evaluation process by removing the dependency on test datasets from similar distributions, while providing insights into the models' performance and generalization capability.
Under the Hood: A Practical Analysis with WeightWatcher
WeightWatcher in essence gives us metrics to evaluate models without any requirements of test data these metrics include:
- Alpha (α): Power Law exponent that measures layer correlation. Values between 2 < α < 6 indicate well-trained layers. When α < 2, the layer is over-trained/overfitting; when α > 6, the layer is undertrained/underfitting. Models with smaller average alpha values generally show better generalization performance.
- Alpha hat (α̂): A weighted average of alpha that corrects for model depth, calculated as a scale-adjusted form of alpha. This metric is correlated with test accuracies and is particularly suitable for comparing DNNs with different hyperparameters and depths simultaneously.
- Log Spectral Norm: The logarithm (base 10) of the largest eigenvalue of the layer correlation matrix X=W^TW, which represents the spectral norm squared. This measures the maximum amplification factor of the layer. Lower average log_spectral_norm values are useful for comparing models of different depths, with smaller values generally indicating better stability and generalization.
- Stable Rank: A norm-adjusted measure calculated as the ratio of Frobenius norm squared to spectral norm squared. This metric indicates the effective dimensionality or rank of the weight matrix and provides insight into the scale of the Empirical Spectral Density (ESD). Higher stable rank suggests the layer uses its dimensions more evenly and efficiently.
Decoder-only Model Evaluation
We first evaluate popular pretrained LLMs, such as GPT-OSS 20B and Qwen3 32B, across all layers using the default parameters of WeightWatcher (WW). The results are as follows:

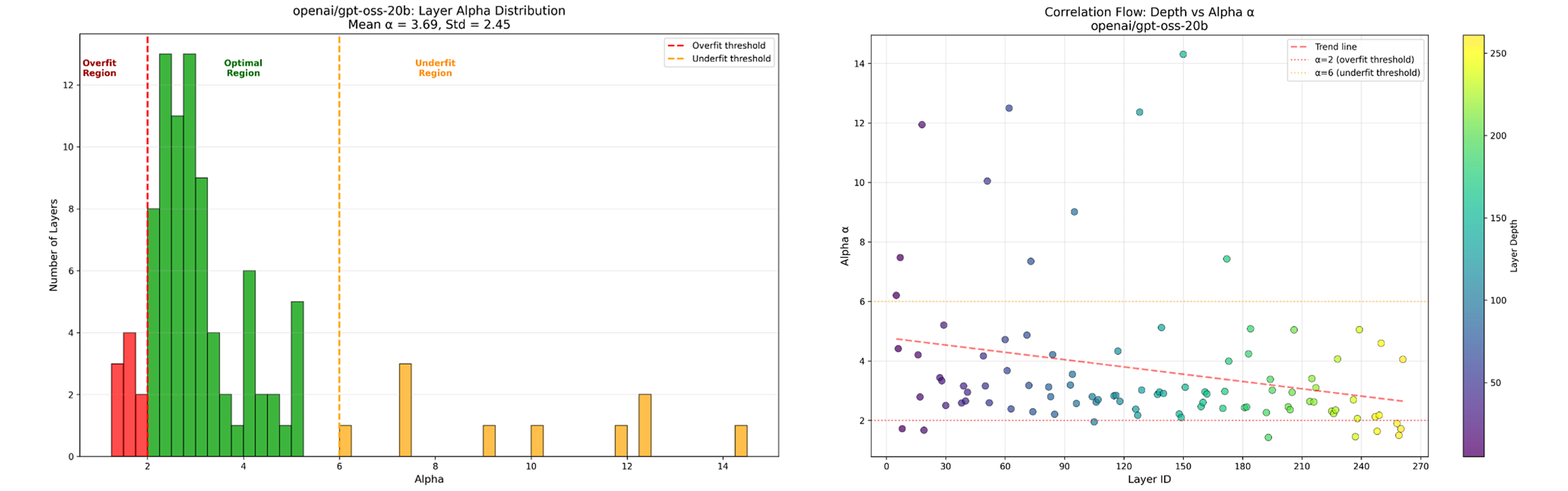
Figure 1: GPT-OSS 20B Evaluation Results

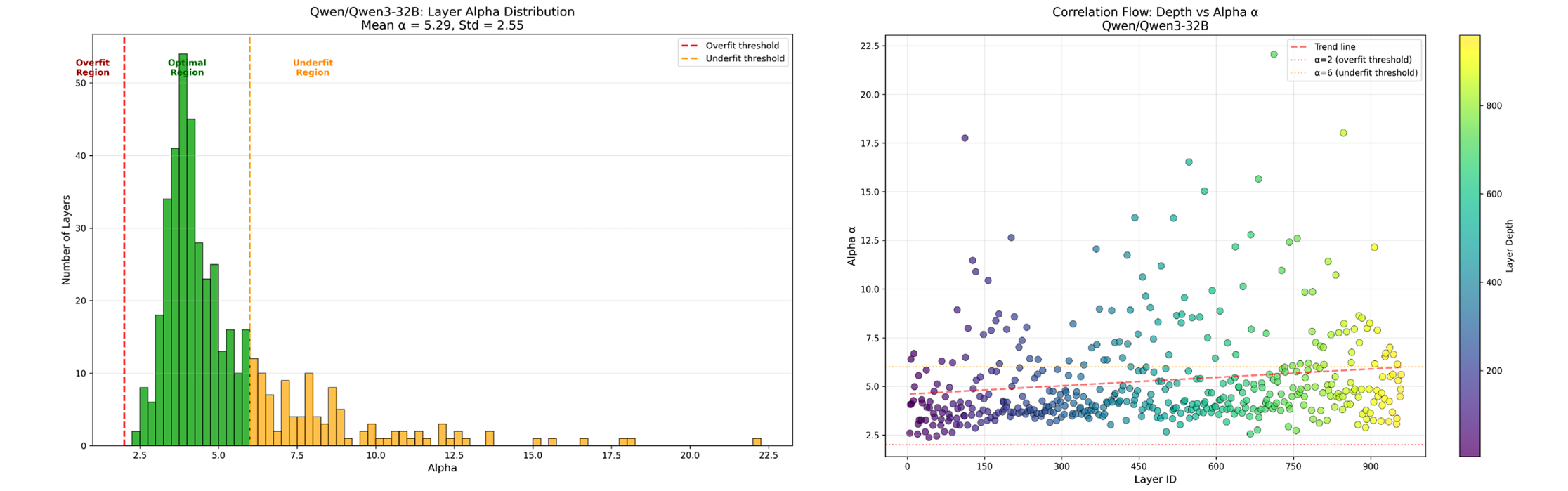
Figure 2: Qwen3-32B Evaluation Results
We can clearly see that the GPT-OSS model shows some overfitting at its final layers. This shows of some insight into the models behaviors. On the other hand Qwen3 shows a high number of underfitting as can be seen in our plots. Other metrics like log_spectral_norm are similar for both models where as stable_rank is much larger for Qwen3.
Encoder-only Model Evaluation
Using WeightWatcher, we evaluate both the base embedding models and their fine-tuned counterparts. We use the defult hyperparmeters of weightwatcher in our experiment and analyze these model:
- answerdotai/ModernBERT-base
Fine-tuned model: newmindai/modernbert-base-tr-uncased-allnli-stsb
- Alibaba-NLP/gte-multilingual-base
Fine-tuned model: newmindai/TurkEmbed4STS
Alibaba-NLP/gte-multilingual-base

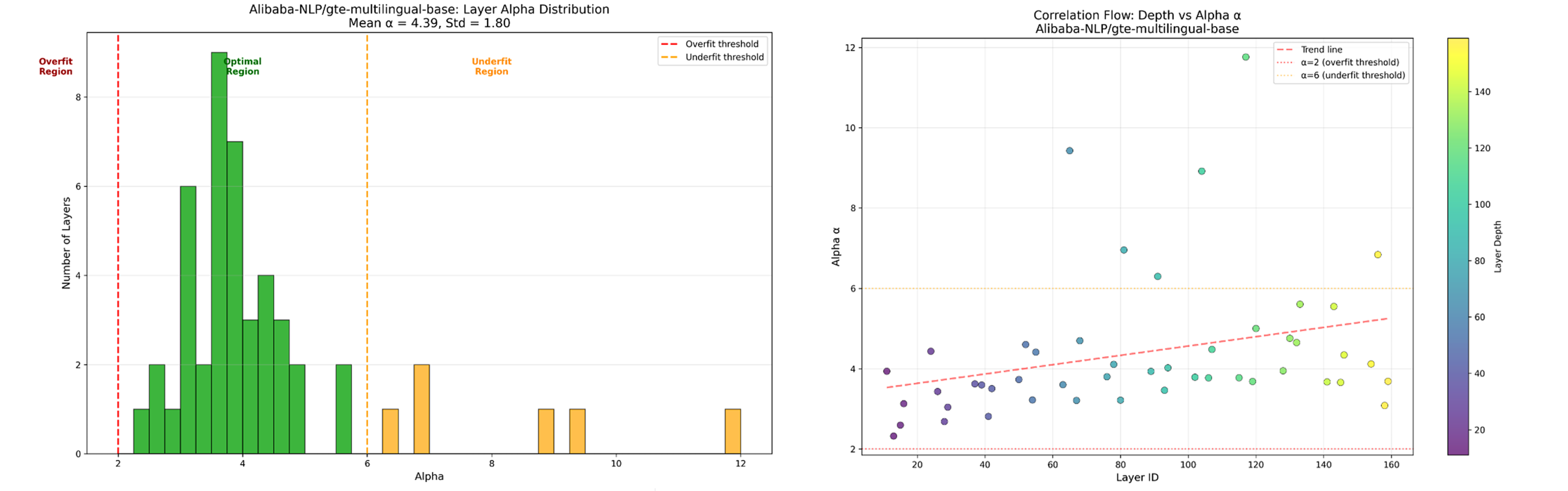
Figure 3: GTE-multilingual-base Evaluation Results
newmindai/TurkEmbed4STS

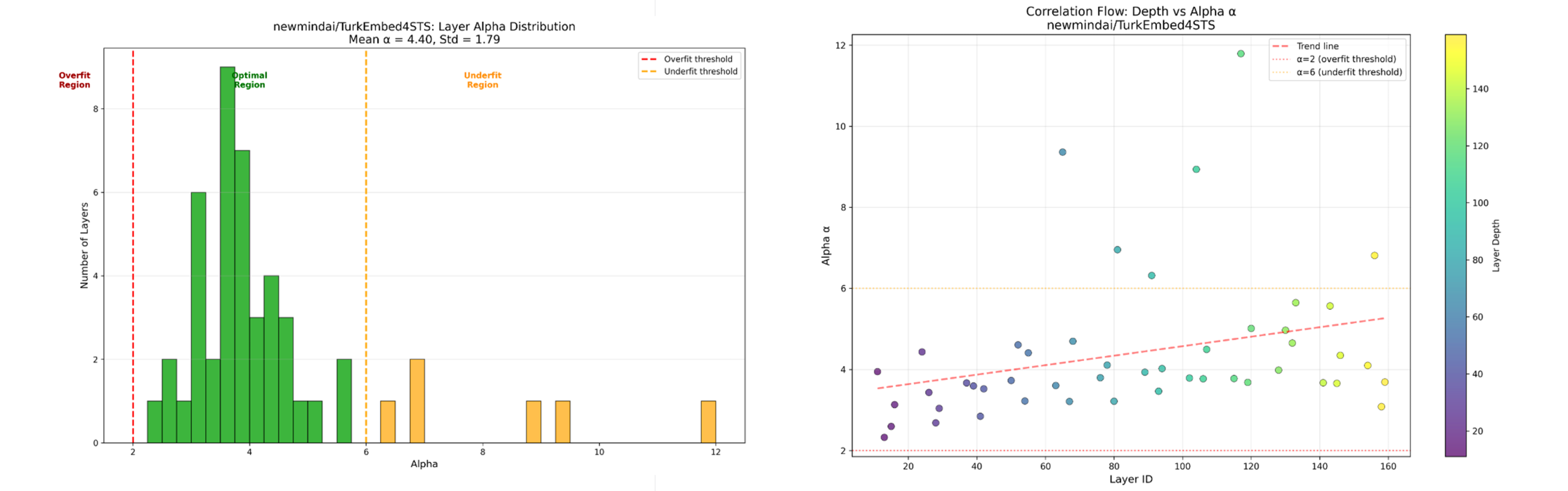
Figure 4: TurkEmbed4STS Evaluation Results
answerdotai/ModernBERT-base

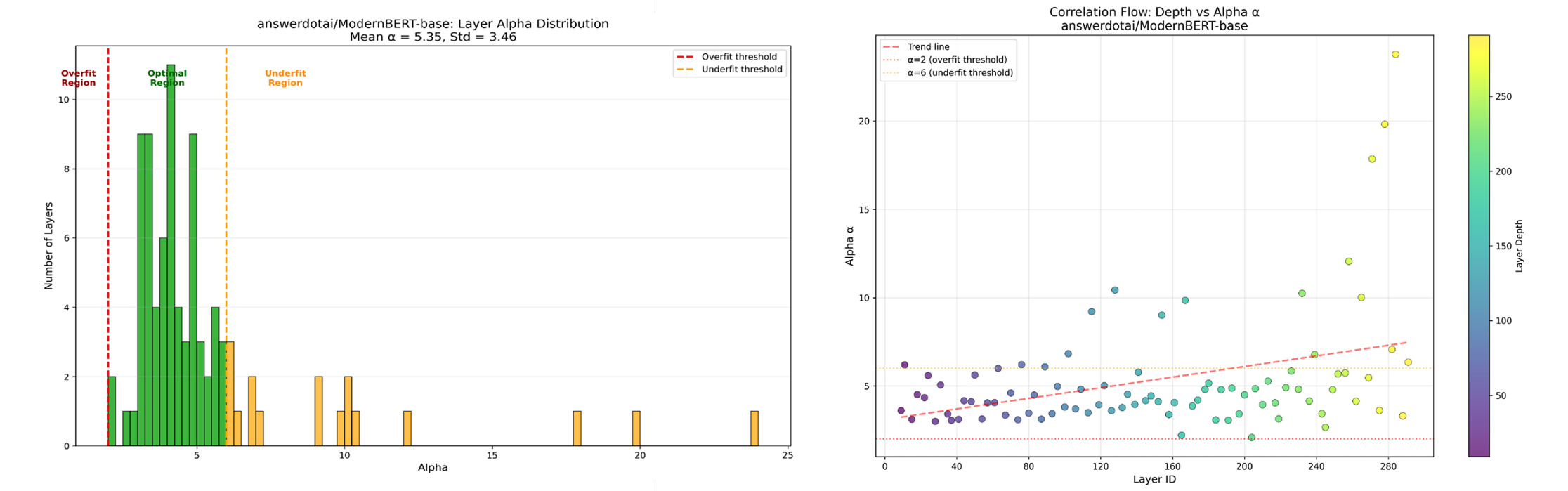
Figure 5: ModernBERT-base Evaluation Results
newmindai/modernbert-base-tr-uncased-allnli-stsb

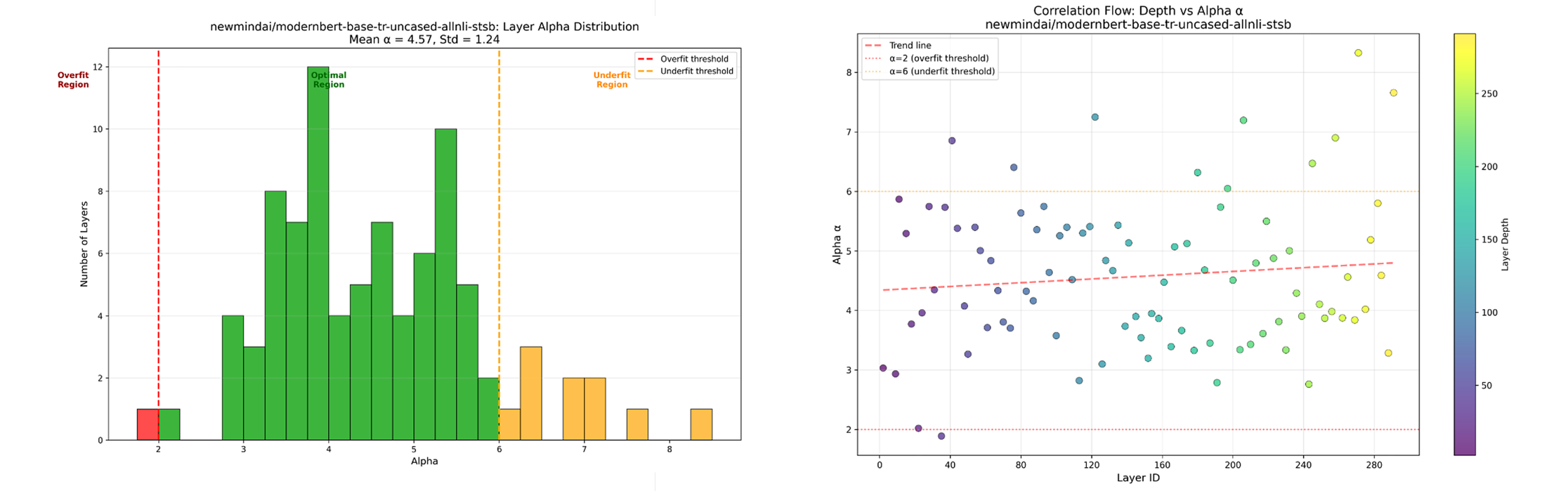
Figure 6: ModernBERT-base-tr-uncased-allnli-stsb Evaluation Results
We leverage the WeightWatcher Power-Law (PL) metric to quickly evaluate pretrained models without the need for any additional training or testing. By analyzing the layer alpha values, we can identify models with better generalization properties: the best-performing models typically have alphas in the range of 2–6, with smaller values indicating higher quality. For instance, comparisons between GPT-OSS 20B and QWEN3 32B, Alibaba-NLP/gte-multilingual-base and its fine-tuned version newmindai/TurkEmbed4STS, as well as answerdotai/ModernBERT-base and its fine-tuned version newmindai/modernbert-base-tr-uncased-allnli-stsb, demonstrate that some models yield more favorable alpha distributions, which aligns with their superior empirical performance. This methodology provides us with an efficient, model-agnostic way to assess both encoder-only and decoder-only architectures before investing in expensive fine-tuning or benchmarking.
From these results, the models' performance can be analyzed using the average alpha values. It can be observed that finetuning has reduced the presence of ModernBERT, whereas no change has been noted in Alibaba's GTE model. In the Finetuned ModernBERT, a lower α is observed, which indicates higher model accuracy, and a lower α̂ suggests that it has been better trained compared to the base model. WeightWatcher can be used to identify potential issues without requiring any test data, providing a rough estimate of model accuracy. Furthermore, only small changes were observed in the log spectral norm and the stable ranks for both models.
Key Takeaways
- Efficient, Data-Free Evaluation: WeightWatcher's Power-Law (PL) metric allows for the rapid evaluation of pretrained models by analyzing layer alpha values without any need for training or testing. This provides an efficient, model-agnostic method to assess both encoder-only and decoder-only architectures before investing in expensive fine-tuning or benchmarking.
- Interpreting Model Quality: The analysis shows that models with alpha values between 2 and 6 tend to perform best, with smaller average values indicating higher quality and better generalization.
- Decoder Model Insights: The evaluation of decoder models revealed that GPT-OSS 20B shows some overfitting in its final layers, whereas Qwen3 32B has a high number of underfitting layers. These findings from the alpha distributions align with the models' known empirical performance.
- Encoder Model Fine-Tuning Analysis: For encoder models, fine-tuning significantly improved answerdotai/ModernBERT-base. The fine-tuned version showed a lower α̂, suggesting it was better trained and had higher accuracy. In contrast, the fine-tuned version of Alibaba-NLP/gte-multilingual-base showed almost no change in its metrics compared to the base model.
Our Mind
Our interpretation is that data-free evaluation marks a pivotal shift from treating models as opaque black boxes to understanding them as engineered systems. By analyzing the intrinsic properties of a model's weights, we gain a "health check" that reveals structural flaws like overfitting or underfitting without the need for costly, data-dependent benchmarking. This empowers us to make wiser decisions upfront, selecting models with sound architectural integrity and validating whether fine-tuning genuinely improves their structure or merely adjusts superficial behavior. Ultimately, this approach moves us beyond simple performance metrics toward a more mature, insightful, and efficient discipline of AI engineering, where we can build with greater confidence and intention.
References
- Martin, C. H., & Mahoney, M. W. (2021). Implicit self-regularization in deep neural networks: Evidence from random matrix theory and implications for learning. Journal of Machine Learning Research, 22(165), 1–73. http://jmlr.org/papers/v22/20-410.html
- Martin, C. H., Peng, T., & Mahoney, M. W. (2021). Predicting trends in the quality of state-of-the-art neural networks without access to training or testing data. Nature Communications, 12, 4122. https://doi.org/10.1038/s41467-021-24025-8
- Martin, C. H., & Mahoney, M. W. (2025). SETOL: A semi-empirical theory of (deep) learning. arXiv. https://arxiv.org/pdf/2507.17912
- Zhang, X., Zhang, Y., Long, D., Xie, W., Dai, Z., Tang, J., ... & Zhang, M. (2024). mgte: Generalized long-context text representation and reranking models for multilingual text retrieval. arXiv preprint arXiv:2407.19669.
- Warner, B., Chaffin, A., Clavié, B., Weller, O., Hallström, O., Taghadouini, S., ... & Poli, I. (2024). Smarter, better, faster, longer: A modern bidirectional encoder for fast, memory efficient, and long context finetuning and inference. arXiv preprint arXiv:2412.13663.
Models: GPT-OSS-20B, Qwen3-32B, ModernBERT-base, ModernBERT-base-tr-uncased-allnli-stsb, GTE-multilingual-base,TurkEmbed4STS