Enhancing Information Retrieval with Ranking Fusion Methods: RRF & DBSF
Modern search systems often combine sparse (keyword-based) and dense (vector-based) queries to achieve both precision and semantic depth.

Enhancing Information Retrieval with Ranking Fusion Methods: RRF & DBSF
-
Modern search systems often combine sparse (keyword-based) and dense (vector-based) queries to achieve both precision and semantic depth.
-
However, merging these heterogeneous results “fairly” can be challenging: a dense model might produce high similarity scores on a small set of results, while a sparse model might rank different documents strongly.
-
Reciprocal Rank Fusion (RRF) and Distribution-Based Score Fusion (DBSF) address this by fusing rankings or scores from multiple query types into a single, balanced list.
Reciprocal Rank Fusion (RRF)
Concept
RRF rewards documents that consistently appear near the top across multiple ranked lists, regardless of their raw scores. Rather than comparing score magnitudes, RRF uses each document’s rank position in each list to compute a bonus:
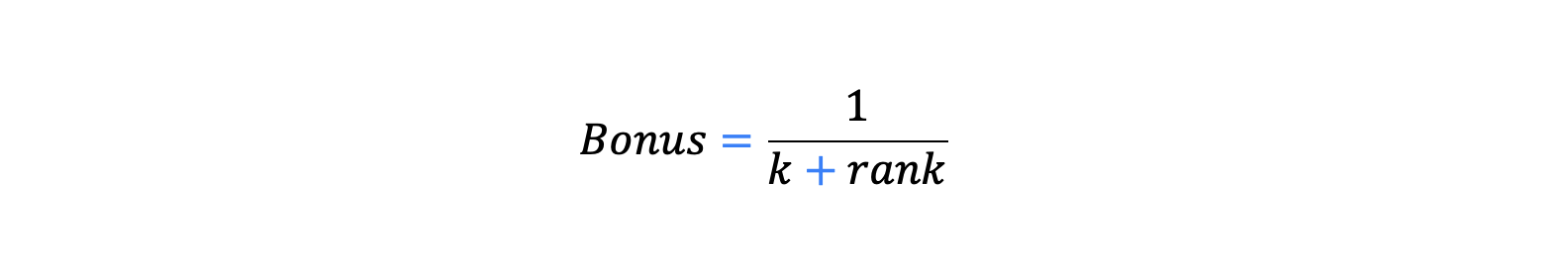
where k (commonly 60) dampens the impact of lower positions. The final RRF score is the sum of these bonuses over all lists. Documents highly ranked by both sparse and dense queries will therefore surface to the top.
Formula
For document d, its RRF score is computed as:
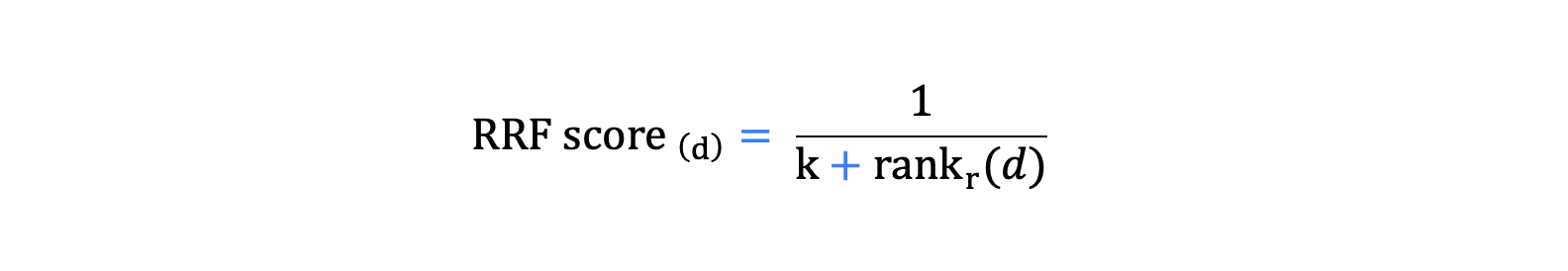
-
R: the set of all ranking lists (e.g., sparse and dense).
-
rank₍ᵣ₎(d): the position of document d in ranking list r (1 for top, 2 for second, etc.).
-
k: a damping constant (commonly set to 60) that reduces the influence of lower ranked documents.
A lower rank (i.e., closer to 1) yields a higher reciprocal bonus. Summing these bonuses across all lists naturally promotes documents with strong consensus.
Key Benefits:
Emphasizes consensus among different retrieval methods rather than the magnitude of any single score.
-
Consensus-Oriented Ranking: Rather than relying on raw score magnitudes, RRF emphasizes agreement across multiple retrieval methods. Documents that consistently appear near the top in different systems (e.g., dense and sparse) are prioritized.
-
Outlier Resistance: By focusing on rank positions instead of numerical scores, RRF reduces the influence of extreme or inconsistent scores from any single model, making it more robust to noisy outputs.
-
Simple & Training-Free: RRF requires only the ranked order of documents—not their scores—making it easy to implement without the need for complex calibration or supervised learning.
-
Proven Effectiveness in Hybrid Search: In practice, RRF has demonstrated consistent improvements in precision and relevance by surfacing results with strong cross-model support, especially in hybrid retrieval setups.
Python Implementation Example
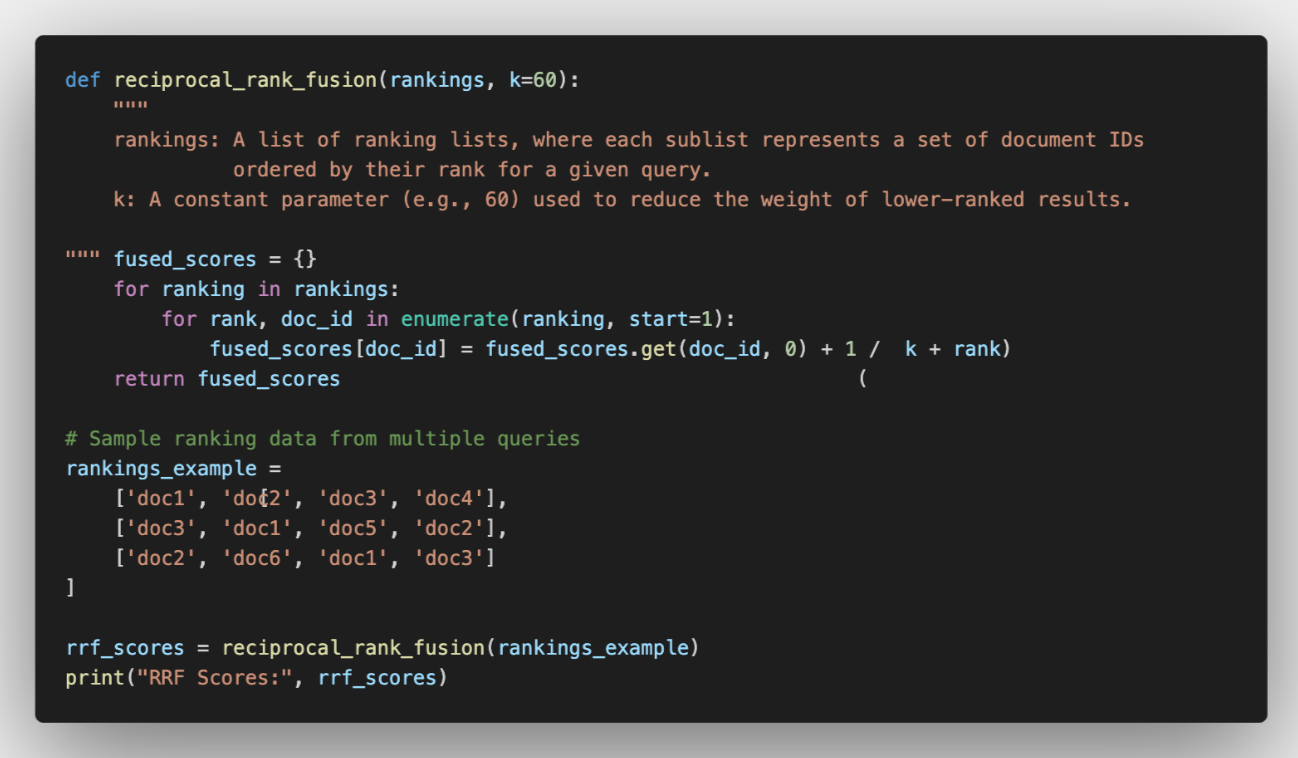
In this example, each document's contribution is inversely related to its rank position in the different lists, and the scores are summed to produce a final ranking.
Distribution-Based Score Fusion (DBSF)
Concept
Distribution‑Based Score Fusion (DBSF) brings raw scores from heterogeneous retrieval methods onto a common footing by statistically normalizing and clamping them. Since sparse and dense models often produce scores on wildly different scales (e.g., 0–1 vs. 0–100), simply summing those scores can let one model dominate. DBSF instead maps each model’s outputs into a “safe zone” around its own mean, ensuring that extreme outliers don’t skew the fused ranking.
Formula
For each query and retrieval method i ∈ E:
-
Calculate the mean (μ) and standard deviation (σ) of all scores returned by method i.
-
For each document score s, normalize it to a clamped range using:
normalized_score = max(min(s, μ + 3σ), μ - 3σ)
-
Convert these normalized scores to a common scale (typically 0-1).
-
Sum the normalized scores across all retrieval methods to get the final ranking score for each document.
This method results in a balanced fusion that prevents outliers from disproportionately influencing the final ranking.
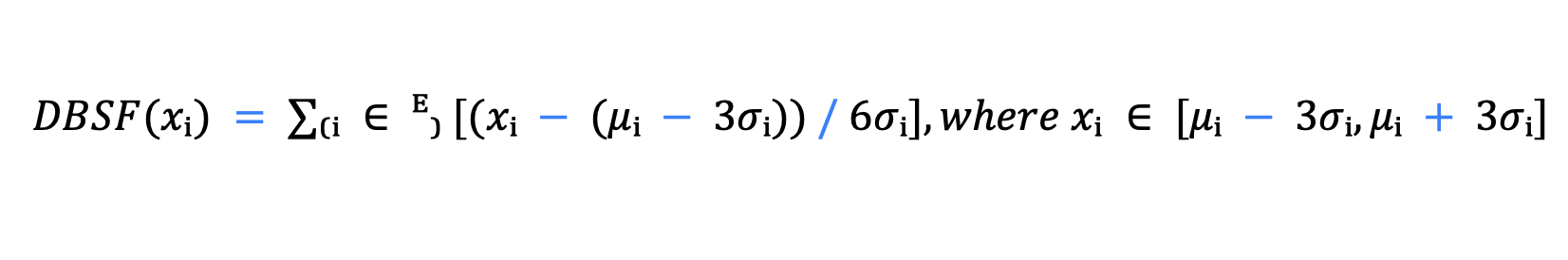
Explanation:
e raw score from retrieval method i.
-
𝜇𝑖 𝜇 i , 𝜎i σ i : The mean and standard deviation of the scores from method i.
-
The normalization maps scores into a [0, 1] range within the safe interval 𝜇𝑖 𝜇 i ± 3 𝜎i σ i . Outlier scores falling outside this interval are clamped to the boundary before fusion.
This equation ensures that each score is scaled proportionally within its distribution before being summed across methods.
As a result, score ranges from different retrieval systems are harmonized, reducing the influence of numerical outliers and allowing fair comparison during fusion.
Key Benefits:
-
Scale-Invariant Fusion: By normalizing and clamping within each model's own distribution, DBSF prevents one model's larger numerical range from overpowering another.
-
Outlier Control: Scores beyond three standard deviations are brought back into the core distribution, reducing the influence of anomalous high or low values.
-
Simplicity & Effectiveness: Requires only mean and standard deviation computations per list, yet yields a balanced combined score that respects each model's relative confidence.
Python Implementation Example
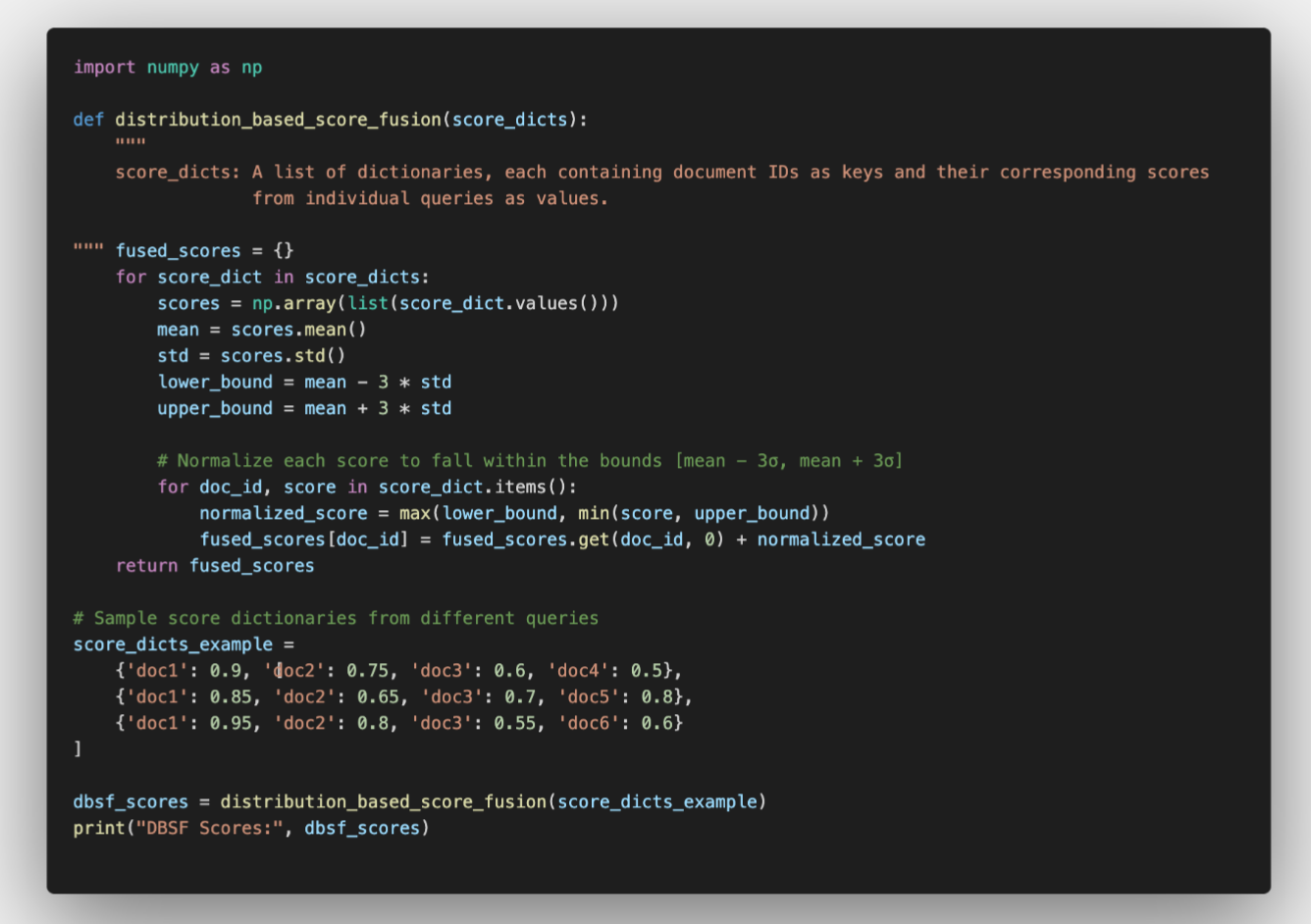
In this implementation, document scores from different queries are normalized and summed, ensuring that no single extreme value significantly skews the final fusion score.
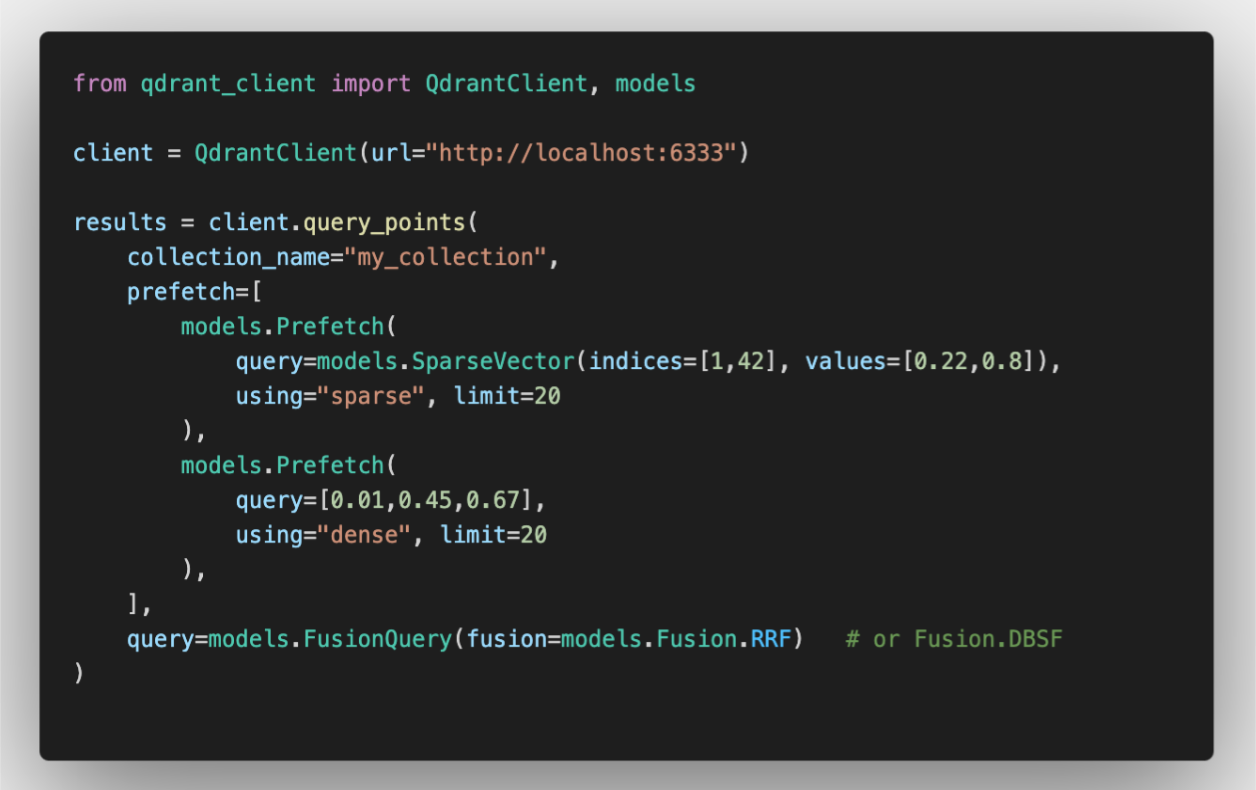
Practical Usage with Qdrant
Qdrant enables hybrid retrieval by executing sparse and dense queries simultaneously via the prefetch API. Fusion strategies like Fusion.RRF and Fusion.DBSF can be applied directly. Experiments on BEIR and SciFact show consistent gains, with DBSF slightly outperforming RRF in precision and normalized gain due to better score balancing. Example:
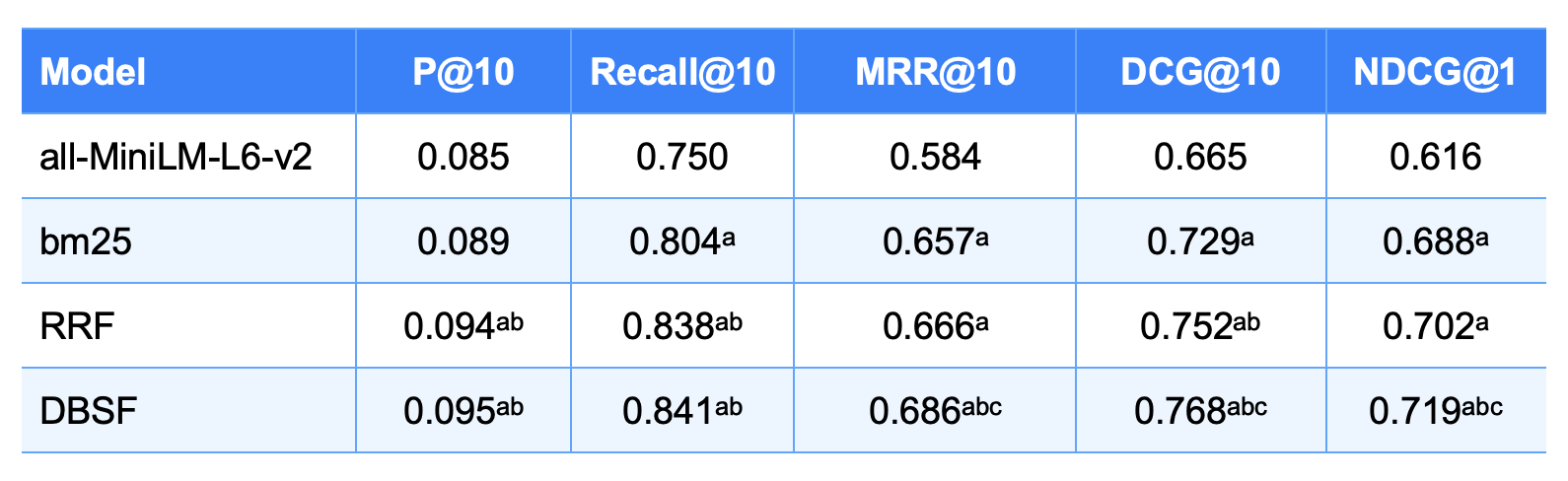
Experimental Results on BEIR (SciFact)
To empirically evaluate the effectiveness of RRF and DBSF, we conducted a benchmark on the BEIR SciFact dataset, comparing a sparse retriever (BM25), a dense model (all-MiniLM-L6-v2), and their fused outputs using both fusion techniques.
Observations:
-
RRF Effectiveness: RRF consistently improves over individual methods by promoting documents that appear near the top across both sparse and dense ranked lists, demonstrating the value of consensus-based ranking.
-
DBSF Advantage: DBSF slightly outperforms RRF across all evaluation metrics, suggesting that its statistical normalization approach better handles the heterogeneous score distributions from different retrieval methods.
-
Hybrid Search Benefits: Both fusion methods deliver consistent performance gains compared to either sparse or dense retrieval alone, confirming the value of hybrid search approaches in information retrieval tasks.
Note: The superscripts a, b, and c are used to indicate statistical significance: 'a' means a statistically significant improvement over 'all-MiniLM-L6-v2', 'b' means statistically significant over 'BM25', and 'c' means statistically significant over 'RRF'. Therefore, if an entry has 'abc', it signifies that it is significantly better than all three baselines.
Our Perspective
In information retrieval, balancing reliability and fairness is key—especially when merging results from diverse models. Simple fusion methods like RRF and DBSF often deliver strong performance by combining rank positions and normalized scores.
RRF (Reciprocal Rank Fusion) highlights documents that consistently appear near the top across systems, focusing on rank consensus rather than absolute scores. While transparent and effective, it may overlook differences in model confidence.
DBSF (Distribution-Based Score Fusion) addresses this by normalizing scores within each model’s distribution (μ ± 3σ), reducing outlier impact and aligning scales for fairer fusion.
A hybrid strategy—normalizing scores with DBSF, then applying RRF—combines the strengths of both: score balance and rank agreement. Future improvements could include dynamic tuning of parameters, feedback-driven adjustments, and metadata-based refinements for even more accurate results.
Key Takeaways
-
Reciprocal Rank Fusion (RRF): Leverages rank positions to reward documents that consistently appear near the top across multiple lists; the damping constant k allows you to control how much lower‐ranked items contribute.
-
Distribution-Based Score Fusion (DBSF): Harmonizes heterogeneous score scales by clamping each model's outputs within μ ± 3σ before summation, mitigating the influence of extreme outliers.
-
Hybrid Retrieval in Qdrant: Enables simultaneous sparse and dense prefetching in a single API call, with RRF/DBSF applied clientside for maximal flexibility and transparency.
-
Unsupervised & Lightweight: Both RRF and DBSF require no additional training data or learning to rank models—perfect for rapid deployment in production search systems.
-
Parameter Sensitivity: Finetuning k for RRF and adjusting clamping bounds for DBSF based on dataset characteristics can yield significant performance gains.
-
Broad Applicability: These fusion techniques excel in metasearch engines, multiquery retrieval scenarios, and any application demanding robust, semantically rich search results.