Optimizing AI Inference: Unleashing Scalable And Efficient Model Performance
In AI and ML, efficient model inference is crucial for scalability and performance. An optimized inference platform improves response times and supports large-scale AI deployment. This blog post examines key metrics for evaluating and enhancing our inference platform's performance. Analyzing data from 40,000 samples over 32 hours, we tracked indicators like token throughput, latency, and GPU utilization. Visualized with Prometheus and Grafana, this analysis provides valuable insights for refining the efficiency and scalability of large-scale AI systems.

Optimizing AI Inference: Unleashing Scalable And Efficient Model Performance
-
Optimized AI inference is essential for scalability andperformance, ensuring faster response times and efficient large-scale deployment.
-
Key performance indicators such as token throughput,latency, and GPU utilization were evaluated to assess and enhance inference efficiency.
-
Analyzing 40,000 samples over 32 hours, we leveraged Prometheus and Grafana for in-depth performance visualization.
-
The findings provide insights into improving the efficiency and scalability of AI inference systems.
Deep Dive Into AI Performance: Metrics, Insights, And Optimization Strategies
Data Collection and System Overview
This study examines an inference platform using the vLLM engine, optimized for large-scale AI tasks. Over 32 hours, 40,000 samples were collected from the /metrics endpoint, offering key performance insights. The data reveals operational efficiency and identifies potential bottlenecks for optimization. The following points will explore these metrics in detail.
Token Throughput
Token Throughput refers to the number of tokens a system can process per unit of time (for example, tokens per second). It is a key performance metric in LLM inference, as it measures the efficiency of the system in handling token generation tasks. Higher throughput means the system can process more tokens in less time, which is critical for scaling applications.
Key Concepts:
-
Token: The smallest unit of text processed by the model based on its tokenizer. (e.g., a word, subword, or character).
-
Throughput: The rate at which tokens are processed (input + output) over time.
-
Latency: The time taken to process a single token or a batch of tokens.
-
Batch Size: The number of requests processed simultaneously in a batch.
(“Throughput” ) is calculated as:
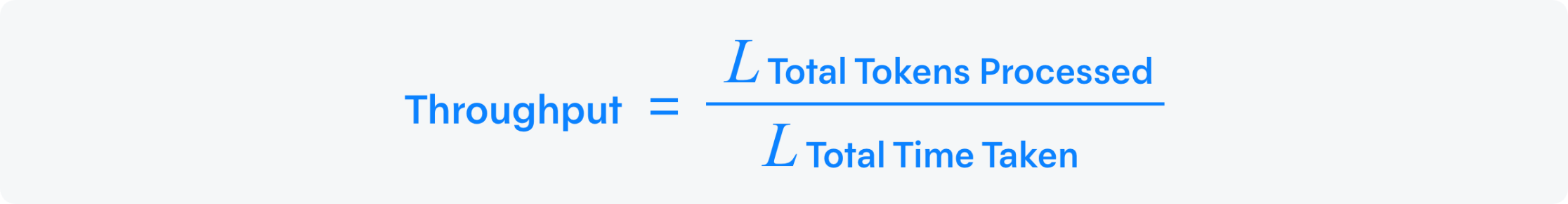
where:
-
Total Tokens Processed: The sum of all tokens in the input prompts and generated outputs.
-
Total Time Taken: The time taken to process all tokens.
Request Generation / Prompt Length
The generation of a request—or the length of the prompt—refers to the total number of tokens used in each input to a language model during inference. Prompt length directly impacts:
-
Performance: Long prompts risk truncation (if they exceed the model’s maximum sequence length) or reduced effectiveness due to context dilution.
-
Infrastructure Expansion: Inference over longer prompts and outputs increases compute load, memory usage, and latency. At scale, this drives the need for more robust infrastructure to maintain responsiveness and cost-efficiency.
The total number of tokens processed during inference is calculated as:

Components:
-
Prompt Length (L_"prompt"): The number of tokens in the input, including both static (e.g., templates, instructions) and dynamic (e.g., user input, conversation history).
-
Output Length (L_"output"): The number of tokens generated by the model in response to the prompt.
Time to First Token Latency
TTFT Latency measures the time to generate the first token after a prompt. It’s crucial for user experience in apps like chatbots. Lower TTFT means better responsiveness. Expressed as:

where:
-
Prompt Processing Time: The time taken to encode and process the input prompt.
-
Model Computation Time: The time taken by the model to generate the first token.
-
Overhead: Additional time caused by system delays, such as data transfer or queuing.
Time Per Output Token Latency
Time Per Output Token Latency is the average time to generate each token after the first. It’s crucial for LLM inference, impacting responsiveness and fluency in chatbots, translation, and content creation. Lower latency ensures faster, smoother text generation. It can be expressed as:
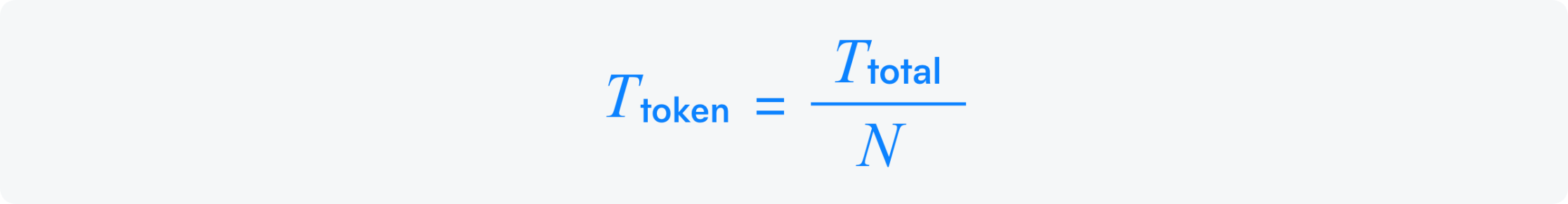
where:
-
T_"total" : Total time taken to generate all output tokens.
-
N : Total number of output tokens generated.
End-to-End Request Latency
End-to-End Request Latency measures total time from input to final token. It’s critical for LLM inference, impacting user experience in chatbots, translation, and content generation. Lower latency ensures faster interactions. Expressed as:
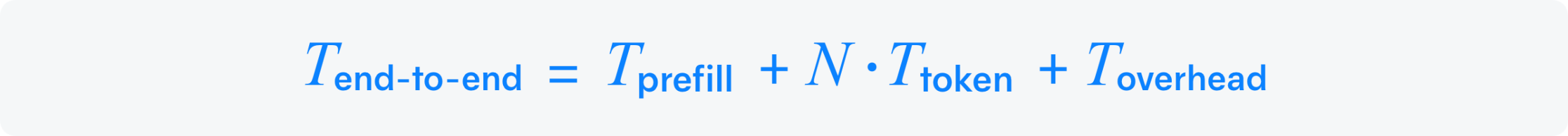
where:
-
T_"prefill" : Time to encode and process the input prompt (prefill phase).
-
T_"token" : Average time to generate each output token (decoding phase).
-
N : Total number of output tokens generated.
-
T_"overhead" : Additional system delays, such as data transfer, queuing, or model warm-up.
Finish Reason
Finish reasons determine when a language model stops generating text, ensuring coherent and application-aligned outputs. Common criteria include end-of-sequence tokens, token limits, stop sequences, and probability thresholds. Optimizing these involves fine-tuning parameters to balance constraints, producing high-quality, relevant outputs. This is critical for effective LLM inference.
Common Finish Reasons:
-
End-of-Sequence Token: A special token (e.g., <EOS>) signals the end.
-
Maximum Token Limit: Stops when output hits a predefined token limit.
-
Stop Sequences: Halts when a specific token sequence (e.g., a phrase) is detected.
-
Probability Threshold: Stops when the model’s confidence in the next token drops below a set threshold.
-
User Interruption: Manually stopped by the user or application.
Scheduler State
Scheduler State refers to the internal system responsible for managing computational resource allocation (e.g., GPU/TPU) to process multiple LLM inference requests in parallel. This system is designed to optimize efficiency and performance in high-throughput or multi-tenant environments by balancing resource utilization, minimizing latency, and maximizing throughput.
Key components of the Scheduler State include:
-
Request Queues: Organize and prioritize incoming requests based on scheduling policies.
-
Batch Processing: Groups requests into batches to enhance computational efficiency.
-
Resource Allocation: Dynamically assigns hardware resources to active requests.
-
Load Balancing: Distributes workloads to prevent bottlenecks.
Optimization strategies for improving the Scheduler State include:
-
Dynamic Batching: Adjusts batch sizes in real-time to handle varying workloads.
-
Priority-Based Scheduling: Allocates resources based on request urgency or importance.
-
Load Balancing: Evenly distributes tasks across GPUs or TPUs.
-
Continuous Resource Monitoring: Tracks resource usage and adjusts allocations dynamically.
GPU Cache Utilization
Efficient GPU cache utilization is vital for LLM inference, especially for KV caches in transformers. It reduces memory delays, speeds up token generation, and improves performance. Optimization includes better KV cache management, shorter sequences, balanced batch sizes, and hardware use. This leads to faster inference, lower latency, higher throughput, and better energy efficiency, key for scaling LLMs.
Visualizing Data with Prometheus and Grafana
The metrics collected from the/metrics endpoint are ingested by Prometheus and visualized through Grafana. These tools allow us to monitor real-time system performance and generate detailed graphs that provide insights into different aspects of the platform’s operation.

Figure 1: Visualizing metrics using Prometheus and Grafana.
Key Performance Insights
Analyzing these metrics helps identify bottlenecks and optimization opportunities. For example, high output token latency may indicate the need for architectural or hardware improvements. Continuous monitoring ensures consistent, scalable performance, even under high demand. Throughput optimization involves addressing low throughput by either scaling up hardware resources or improving system efficiency. Latency reduction focuses on minimizing Time to First Token (TTFT) and output token latency to enhance responsiveness. Efficient resource utilization requires monitoring GPU cache usage to ensure balanced performance and prevent bottlenecks.
OUR MIND
Optimizing AI inference platforms is vital for meeting growing AI demands. Key metrics like token throughput, latency, and GPU utilization ensure efficiency and scalability. Tools like Prometheus and Grafana provide real-time insights for data-driven decisions, improving performance and user experience.
For businesses, this means faster delivery, responsive services, and cost-effective scaling, enhancing competitiveness in the market.
KEY TAKEAWAYS
-
Token Throughput: A critical performance metric that quantifies the system’s efficiency in processing and handling requests over time.
-
TTFT Latency: A key factor in user experience, as it directly impacts the initial delay before token generation begins.
-
Output Token Latency: Measures the interval between the generation of subsequent tokens after the first, significantly affecting system responsiveness.
-
End-to-End Request Latency: Provides a comprehensive measure of total processing time, offering insights into overall system efficiency and performance.
-
Finish Reason Monitoring: Essential for diagnosing failures or issues (e.g., timeouts, errors) that may require resolution.
-
Scheduler State: Offers insights into resource allocation across requests, enabling optimization of resource utilization and performance.
-
GPU Cache Utilization: A critical metric for ensuring efficient hardware resource use and preventing memory-related bottlenecks during inference.
-
Real-Time Visualization Tools: Tools like Prometheus and Grafana enable continuous monitoring and rapid identification of performance anomalies or inefficiencies.
-
Continuous Metric Analysis: Empowers data-driven decision-making, facilitating the scaling and optimization of AI inference platforms.
References
-
Daniil Baldouski, Aleksandar Tošić. Grafana plugin for visualising vote-based consensus mechanisms, and network P2P overlay networks, 2 December 2021.
-
Woosuk Kwon, et al., Efficient Memory Management for Large Language Model Serving with PagedAttention, 12 September 2023.
-
MonsterAPI Team, Enhancing LLM Context Length with RoPE Scaling 9 August 2024.
-
Xiaoran Liu et al., Scaling Laws of RoPE-based Extrapolation, 13 March 2024.