LongBench v2: Benchmarking Deeper Understanding and Reasoning on Realistic Long-Context Tasks
Evolving AI Challenges: As language models become more advanced, handling long and complex texts in fields like law, finance, and medicine is no longer optional—it's essential.

LongBench v2: Benchmarking Deeper Understanding and Reasoning on Realistic Long-Context Tasks
-
LLMs face challenges with long-context processing, which is essential for real-world tasks like legal analysis, financial summarization, and medical interpretation.
-
Existing models often struggle to retain context over extended token sequences, resulting in reduced comprehension and reasoning accuracy.
-
LongBench v2 introduces more complex tasks, covering multi-document and structured data reasoning to better test long-context capabilities.
-
It goes beyond retrieval accuracy, using multiple-choice and inference-time reasoning tasks to assess deeper understanding and reasoning in LLMs.
Benchmark Structure and Task Categories
Scope of LongBench v2: LongBench v2 comprises a diverse set of tasks designed to evaluate LLMs’ abilities in long-context processing. The dataset spans six main categories:
-
Single-Document QA (including Event Ordering, Detective QA)
-
Multi-Document QA (introducing Multi-News QA)
-
Long In-Context Learning (including User Guide QA, New Language Translation)
-
Long-Dialogue History Understanding (covering Agent History QA, Dialogue History QA)
-
Code Repository Understanding (evaluating inter-document code relationships)
-
Long Structured Data Understanding (covering Table QA, Knowledge Graph Reasoning)
Each category encompasses multiple sub-tasks that challenge models with varying levels of complexity, requiring both retrieval and inference-based reasoning.
Model Selection and Capabilities
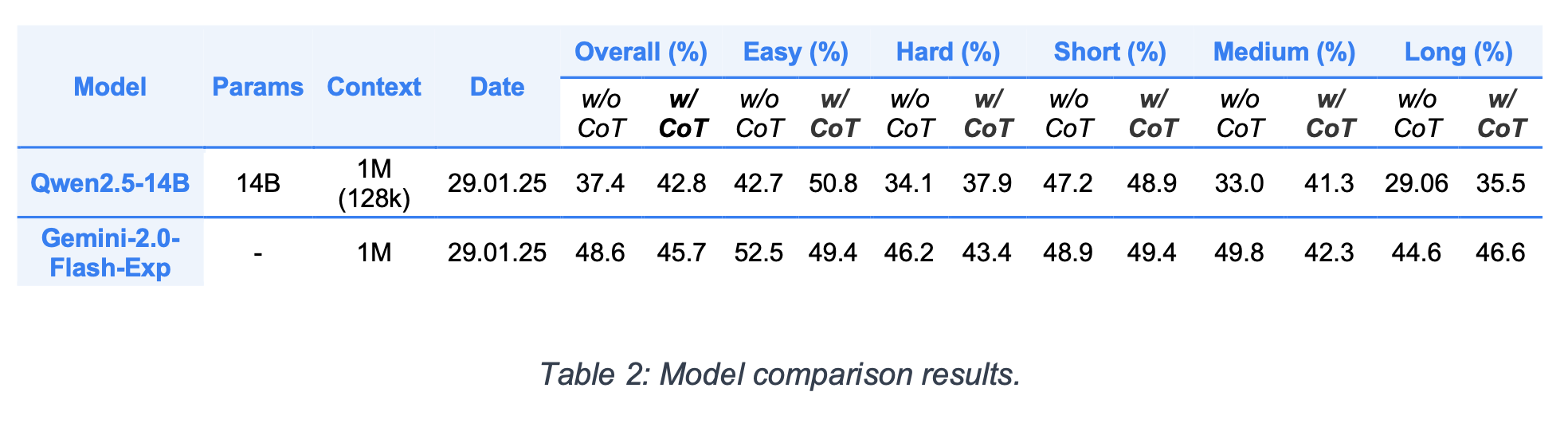
In our experiments, each of the models used in LongBench v2 are strong performers on long texts and multi-step inference. Qwen2.5-14B was selected for use in long text QA and multi-document QA tasks, as it is optimized for high memory efficiency and inference-time reasoning. Gemini-2.0-Flash-Exp is the model that performs best in long-context reasoning and learning tasks, with a large token capacity and advanced parallel processing capabilities.
Model Configurations: LongBench v2 enables comprehensive model evaluation
by allowing users to set the --max_model_len parameter to
match the model's context window length, along with configuring other
evaluation options
(Please check for further details). For example, Qwen2.5-14B has 14B parameters and can handle context up
to 1M token length as shown in Table 1, making it effective for processing
multi-step and long texts.

Evaluation and Results
Evaluation Metrics:LongBench v2 uses the multiple-choice accuracy metric for performance evaluation. This approach provides more reliable results compared to metrics such as F1 and ROUGE used in v1. Especially in long-context tasks, multiple-choice accuracy directly measures the correct response rate, making the assessment process more consistent and objective.
Human Performance Benchmark: Human experts achieved 53.7% accuracy on LongBench v2, while the best AI model beat them with 57.7% accuracy.
Results
Radar Graphs
.png)
Figure 1: Experiment results of models w/o chain of thought
.png)
Figure 2: Experiment results of models w/ chain of thought
Our Take
-
Large language models are increasingly shaping AI-driven applications, but their efficiency and cost-effectiveness remain crucial factors. Our analysis of LongBench v2 demonstrates that well-optimized, mid-sized models like Qwen2.5-14B can compete with or even outperform significantly larger models in certain tasks. These findings suggest that parameter count alone is not the sole determinant of performance; instead, architectural enhancements, prompt engineering techniques like Chain of Thought (CoT), and optimized retrieval mechanisms play a crucial role.
-
The ability of Qwen2.5-14B to challenge models with vastly larger parameter counts suggests that cost-effective AI solutions are becoming increasingly viable. This is particularly relevant for industries requiring long-context understanding, such as legal document processing, financial analysis, and scientific literature comprehension. Future research should continue exploring efficient inference techniques, hybrid retrieval-generation models, and enhanced prompt strategies to further bridge the gap between performance and cost.
Key Takeaways
-
Qwen2.5-14B delivered competitive performance despite having only 14 billion parameters, showing that model architecture and optimization can rival larger models in effectiveness.
-
CoT (Chain-of-Thought) prompting helped both models perform similarly on Single- and Multi-Document QA tasks, narrowing performance gaps and enhancing structured reasoning.
-
Qwen2.5-14B outperformed in Long Dialogue History tasks with CoT, demonstrating better context retention and sequential reasoning compared to Gemini.
-
In Multi-Document QA, Qwen2.5-14B showed strong retrieval abilities, successfully aggregating and synthesizing information across multiple sources.
-
Qwen2.5-14B is a cost-effective alternative to large-scale models, offering strong performance with fewer resources—ideal for organizations with efficiency constraints.
-
Its performance justifies a higher leaderboard position, potentially ranking around 13th despite its smaller parameter count.
-
Gemini-2.0-Flash-Exp excelled in Structured Data reasoning tasks, showing stronger performance with tabular and graph-based information.
-
Gemini also led in Long In-Context Learning, benefiting from efficient use of extended context windows and showing strong generalization.
-
The impact of CoT varied by task type, boosting reasoning tasks but offering minimal benefit in retrieval-heavy scenarios.
-
Both models performed better on medium-length contexts than extremely long ones, suggesting context window optimization remains an open challenge.
-
Smaller models like Qwen2.5-14B could help democratize AI, making advanced reasoning capabilities more accessible without requiring massive infrastructure.
-
Larger parameter models don’t always guarantee better performance, reinforcing the value of smart design and task-specific tuning.
References
-
Qwen Team, Qwen2.5 Technical Report , 6 January 2025
Bai, Y., Tu, S., Zhang, J., Peng, H., Wang, X., Lv, X., Cao, S., Xu, J., Hou, L., Dong, Y., Tang, J., & Li, J. LongBench v2: Towards Deeper Understanding and Reasoning on Realistic Long-context Multitasks 3 Jan 2025