Fine-Tuning GPT-OSS 20B for Turkish Legal Reasoning: A Case Study in Efficient Domain Specialization
Specializing open-weight LLMs like GPT-OSS 20B with LoRA and Unsloth unlocks expert-level Turkish legal reasoning without massive compute.

Fine-Tuning GPT-OSS 20B for Turkish Legal Reasoning: A Case Study in Efficient Domain Specialization
- When you need a legal opinion, consulting a seasoned Turkish legal expert is far more effective than relying on a general encyclopedia.
- General LLMs, while highly versatile, often lack the deep precision required for specialized domains like law.
- Turkish legal texts are dense, terminology-heavy, and demand step-by-step logical reasoning to reach correct conclusions.
- Without true domain understanding, general LLMs risk producing “hallucinations” or generic answers that miss crucial nuances.
- Fine-tuning a pre-trained model can teach it the patterns, terminology, and reasoning style unique to Turkish law.
- A well-fine-tuned AI can think like a trained legal professional, identifying relevant facts, applying legal principles, and reasoning through cases effectively.
A Technical Deep Dive into Fine-Tuning
Our journey began with a powerful open-weight model, specifically OpenAI's GPT-OSS 20B (or a comparable Llama 3.x/Qwen model, chosen for its strong base reasoning capabilities and open-source nature). These models, while impressive, are not inherently specialized in Turkish legal reasoning. To imbue them with this expertise, we turned to a technique called LoRA (Low-Rank Adaptation), combined with the groundbreaking efficiency of Unsloth.
The Magic of LoRA and Unsloth
Fine-tuning large models traditionally requires immense computational resources. LoRA is a revolutionary method that drastically reduces the memory footprint needed for fine-tuning. It works by quantizing the base model weights to 4-bit precision (NF4) and then adding small, trainable "adapters" (LoRA layers) that learn the new, specialized knowledge. This means we don't need to update the entire massive model, only these tiny, efficient adapters.
Unsloth takes LoRA's efficiency to the next level. Through highly optimized custom kernels, Unsloth accelerates the fine-tuning process significantly (up to 1.5x faster) and reduces VRAM consumption (up to 70% less) compared to standard implementations. This innovation allowed us to fine-tune a 20-billion parameter model on a single high-memory GPU, making this advanced alchemy accessible without requiring a supercomputer. For context, Unsloth reports that GPT-OSS 20B LoRA training can fit within approximately 14GB of VRAM, a feat previously unimaginable for models of this scale.
Dataset
The heart of our specialization lies in our proprietary reasoning dataset. This unique dataset comprises 1,000 meticulously crafted examples across 10 distinct categories of Turkish law. Each example has a structure similar to the relevant features in the HuggingFaceH4/Multilingual-Thinking dataset:
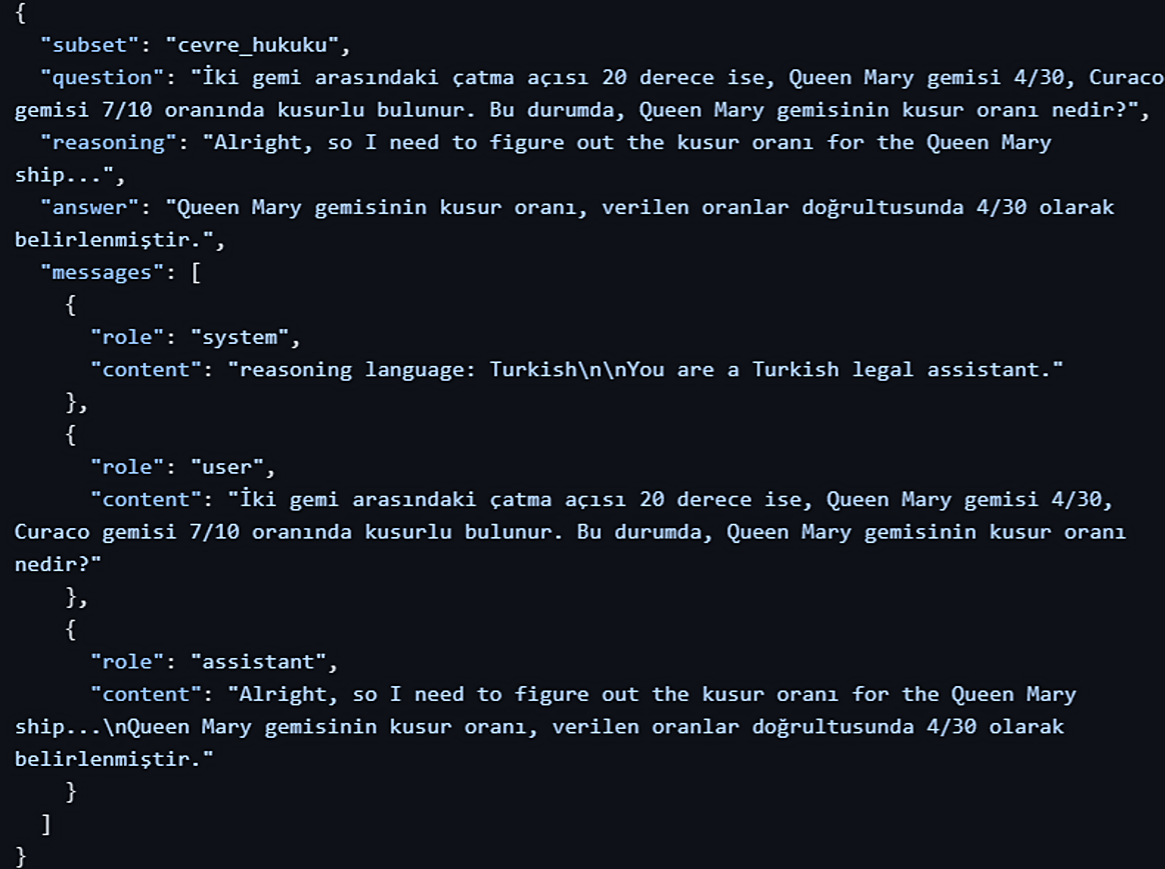
The dataset structure showcases:
- subset: Legal category (10 distinct Turkish law domains)
- question: The legal query in Turkish
- reasoning: Chain-of-Thought process (critical for teaching reasoning)
- answer: Final structured response
- messages: Chat-formatted conversation with system prompt, user query, and assistant's reasoned response
The `reasoning` field is paramount. It contains the "Chain-of-Thought" (CoT) – the step-by-step internal monologue an expert might follow to solve the problem. By including this, we explicitly teach the model *how* to think, not just *what* the answer is. This is crucial for developing a truly intelligent and reliable legal assistant.
For GPT-OSS, we adhere to the Harmony chat template, which natively supports separate "analysis" (for reasoning) and "final" (for the direct answer) channels. For other models like Llama/Qwen, we structure the `reasoning` within the assistant's response, often using special delimiters (e.g., `
The Fine-Tuning Process
Our fine-tuning workflow leverages Hugging Face's `transformers` and `trl` libraries (or Unsloth's optimized versions).
1. Data Preparation:Our JSONL dataset is processed to fit the chosen model's chat template. For GPT-OSS, `openai-harmony` library assists in rendering messages, ensuring proper roles (`system`, `user`, `assistant`) and channels (`analysis`, `final`). A critical step is masking labels during training so that the model primarily learns from the final assistant turn, including its detailed CoT. This prevents the model from generating verbose reasoning for every single turn during inference.
2. Model Loading: The base model (e.g., `openai/gpt-oss-20b`) is loaded in 4-bit quantized form using `BitsAndBytesConfig` (specifically NF4 with double quantization for memory efficiency). We ensure `bfloat16` is used for computation where supported (Ampere+ GPUs) and enable `gradient_checkpointing` for further VRAM savings.
3. LoRA Configuration: We define the LoRA adapters, targeting not only attention layers (`q_proj`, `k_proj`, `v_proj`, `o_proj`) but also the Mixture-of-Experts specific projection layers (`gate_proj`, `up_proj`, `down_proj`) within the GPT-OSS architecture. This ensures the adapters learn to influence the model's specialized reasoning paths effectively.
4. Training: Using `TRL`'s `SFTTrainer`, we train the model with carefully selected hyperparameters (e.g., learning rate, batch size, gradient accumulation steps, `max_seq_length`). Unsloth's optimizations significantly accelerate this phase, making it feasible to iterate and achieve high quality results on our custom dataset.
After training, the LoRA adapters can be merged with the base model for a single, optimized deployment artifact, or kept separate for dynamic loading (e.g., with vLLM).
Benchmarking Results: Quantifying the Impact
To rigorously evaluate the effectiveness of our fine-tuning approach, we employed an LLM-as-a-Judge methodology using Google's Gemini-2.5-Flash model. This approach provides a scalable and comprehensive evaluation across multiple dimensions of model performance.
Evaluation Methodology
We designed a comprehensive evaluation framework with seven key criteria:
- Relevance:How directly the answer addresses the legal question
- Accuracy:Factual correctness and consistency with Turkish legal principles
- Coherence:Logical structure and flow of the response
- Completeness:Comprehensive coverage of all aspects of the query
- Helpfulness:Practical utility from a Turkish legal perspective
- Style/Tone:Appropriateness of language for legal discourse
- Reasoning:Clarity and logic of the reasoning process
Each criterion was scored on a 5-point scale (1=Poor to 5=Excellent), allowing for nuanced assessment of model improvements.
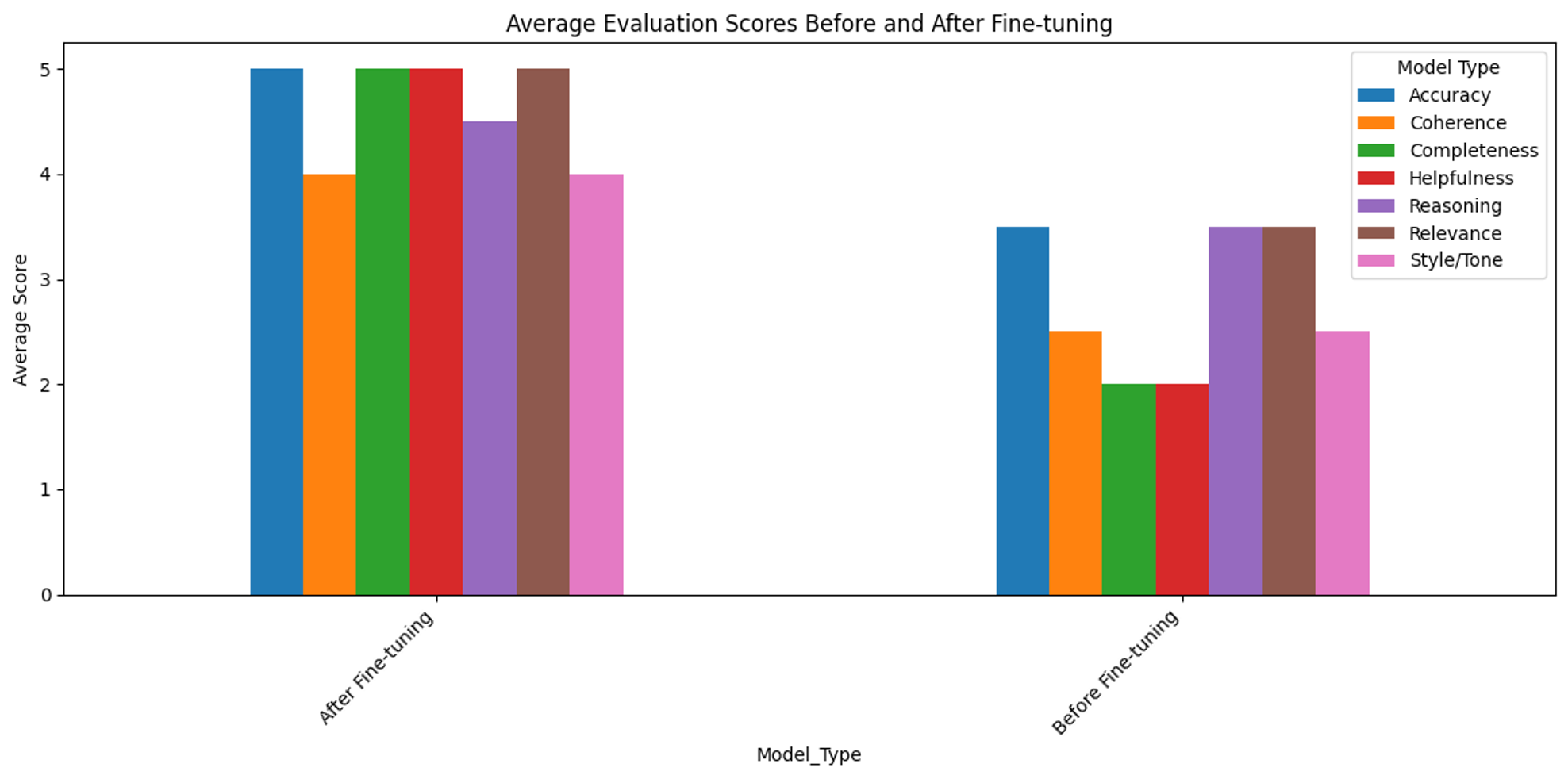
The most dramatic improvements were observed in Completeness and Helpfulness (both +150%), indicating that the fine-tuned model provides significantly more comprehensive and practically useful legal guidance.
Real-World Examples
Let's examine how these improvements manifest in actual legal queries:
Example 1: Maritime Law - Collision Liability
Query: "İki gemi arasındaki çatma açısı 20 derece ise, Queen Mary gemisi 4/30, Curaco gemisi 7/10 oranında kusurlu bulunur. Bu durumda, Queen Mary gemisinin kusur oranı nedir?"
- Before Fine-tuning: The base model provided a generic response, often missing the specific legal calculation required.
- After Fine-tuning: The model correctly identified this as a maritime collision liability case, performed the precise calculation, and provided the answer with appropriate legal context: "Queen Mary gemisinin kusur oranı 4/30 olarak belirlenmiştir."
Example 2: Competition Law - Vertical Integration
Query: "Bir dikey yoğunlaşma işlemi... pazardaki giriş engellerinin artması durumunda, bu yoğunlaşma işleminin rekabet hukuku açısından nasıl değerlendirilmesi gerekir?"
- Before Fine-tuning: Struggled with Turkish legal terminology and provided vague, non-specific answers.
- After Fine-tuning: Demonstrated deep understanding of Turkish competition law, correctly identifying the issue of market entry barriers and providing structured legal analysis aligned with Turkish Competition Authority precedents.
Practical Hints for Working with GPT-OSS 20B
For anyone aiming to harness the full potential of GPT-OSS 20B or similar large language models, here are some hard-won insights from our work at NewMind AI:
- Embrace the Harmony Format: GPT-OSS 20B is specifically trained on OpenAI's Harmony response format. For optimal performance and to leverage its built-in Chain-of-Thought capabilities, always format your input and expect output in this structure. The openai-harmony Python library is your best friend for encoding and decoding messages, ensuring you interact with the model as intended.
- Control Reasoning Effort: GPT-OSS models support a Reasoning: low|medium|high directive within the system message. Experiment with this to balance latency and output quality. For complex legal questions, high reasoning is usually preferred, even if it means slightly longer generation times.
- Mind the Channels: Remember, GPT-OSS outputs its internal thought process (CoT) in an analysis channel and the final, user-facing answer in a final channel. When building applications, always display only the final channel to end-users. The analysis channel is for debugging and understanding the model's internal workings, and may contain unrefined or even hallucinated content.
- Memory Management (MXFP4): If you have access to modern NVIDIA Hopper/Blackwell GPUs (H100, GB200) or the upcoming RTX 50xx series, leverage the native MXFP4 quantization. This allows GPT-OSS 20B to run efficiently on a single ~16GB GPU. Without it, you'll need significantly more VRAM.
- Deployment Flexibility:Tools like vLLM can serve GPT-OSS 20B with an OpenAI-compatible API, simplifying integration into your existing systems. You can even load LoRA adapters dynamically with vLLM without needing to merge them into the base model, offering flexibility for managing multiple specialized models. For quick local testing, transformers serve can spin up a local endpoint.
Our Mind
Our journey from general-purpose LLM to specialized Turkish legal assistant demonstrates that domain expertise can be efficiently embedded into AI without massive computational resources – achieving up to 150% improvements in completeness and helpfulness.
What excites us at NewMind AI is the democratization of specialized AI. Using LoRA, Unsloth, and Chain-of-Thought datasets, we've proven that any organization can build AI that truly understands their domain's unique requirements.
This approach extends beyond law to medicine, finance, engineering – any field where precision matters. We're not just fine-tuning models; we're fine-tuning the future of professional AI assistance.
One thing is clear: the age of one-size-fits-all AI is ending. The future belongs to specialized, efficient, and accessible AI that speaks the language of experts while remaining computationally democratic.
Key Takeaways
- Domain-Specific Accuracy is Paramount: Our fine-tuned model showed significantly fewer errors and irrelevant outputs on Turkish legal questions, proving that specialized training is essential for high-stakes applications.
- CoT Unlocks Deeper Comprehension: Training on explicit reasoning paths enabled the model to articulate its logical progression, not just retrieve answers. This transparency is crucial for trust in sensitive fields.
- Efficiency Drives Accessibility: LoRA and Unsloth democratize LLM specialization, enabling domain-specific models without prohibitive computational resources – making advanced AI accessible to smaller organizations.
- Data Quality Trumps Quantity: Our 1,000 high-quality examples with rich reasoning proved more impactful than vast generic datasets, reinforcing that meticulous, domain-centric data preparation is key to success.
References
- OpenAI Cookbook: Fine-tuning with gpt-oss and Transformershttps://cookbook.openai.com/articles/gpt-oss/fine-tune-transfomers
- OpenAI Cookbook: How to run gpt-oss with Transformershttps://cookbook.openai.com/articles/gpt-oss/run-transformers
- Unsloth Documentation: How to Run & Fine-tunehttps://docs.unsloth.ai/basics/gpt-oss-how-to-run-and-fine-tune
- Hugging Face Blog: Welcome GPT OSShttps://huggingface.co/blog/welcome-openai-gpt-oss
- Hugging Face Blog: Fine-tune Llama 3.1 with Unslothhttps://huggingface.co/blog/mlabonne/sft-llama3
- Hugging Face Multilingual-Thinking Datasethttps://huggingface.co/datasets/HuggingFaceH4/Multilingual-Thinking