Understanding Qdrant Queries: A Qualitative and Quantitative Study
This study evaluates the performance and result diversity of different Qdrant query types across three distinct data collections.

Understanding Qdrant Queries: A Qualitative and Quantitative Study
By NewMind AI Team
This study evaluates the performance and result diversity of different Qdrant query types across three distinct data collections.
The study's purpose is to analyze how different query methods affect the uniqueness of returned results and to highlight differences in their coverage.
The evaluation includes five methods: default (dense), BM25 (sparse), hybrid, sparse2dense, and dense2sparse.
The queries were run on three collections of varying sizes: "books" (~5.2 million vectors), "legislation" (~372,000 vectors), and "supreme court" (~18.9 million vectors).
Measurement: Performance was measured by counting unique and total chunks returned by each method and calculating the intersection of results between different query types.
Query Method Types
The query types evaluated in this study are default (dense), BM25, hybrid, sparse2dense, and dense2sparse.
- Default (dense): searches for similarity using 768-dimensional dense vectors.
- BM25: a classic sparse method based on word frequencies.
- Hybrid: combines dense and BM25 results, integrating scores with RRF (Reciprocal Rank Fusion) and DBSF (Distribution-Based Score Fusion).
- Sparse2dense: begins with a sparse search, then re-ranks the results using dense vectors—providing broad word-based coverage followed by semantic refinement.
- Dense2sparse: the reverse of sparse2dense; it starts with a dense search, then applies sparse representations to filter results—semantic-first, followed by word-based narrowing.
Collection Types
Three collections are used in this study: books, laws, and supreme court.
- Books: ~5.2 million vectors, 768-dimensional, using Cosine distance. A BM25 sparse index is also applied.
- Legislation: ~372,000 vectors, also 768-dimensional with Cosine distance and a BM25 sparse index.
- Supreme Court: the largest dataset, containing ~18.9 million vectors, 768-dimensional with Cosine distance and a BM25 sparse index.
Dataset
For this study, we used the newmindai/quantitative_benchmark dataset, which originally contained 11,549 samples. The dataset underwent significant refinement, beginning with a filtering process to comply with company data policies, which removed 84% of the entries. The remaining data was then deduplicated using the semhash library with a 0.6 similarity threshold, resulting in a final, curated set of 979 questions. Due to these modifications, the statistical distributions may differ from previously published figures, though the final dataset remains representative within our guidelines. This curated dataset will be made publicly available soon.
Measurement Criteria
Two main measurement criteria are used in the experiments:
- unique_point_ids_count — the number of unique chunks returned.
- total_point_ids_count — the total number of chunks returned, including repeats.
In addition, intersections between method pairs were calculated to measure the extent to which different methods return the same chunks.
Findings
1. Matrix Results
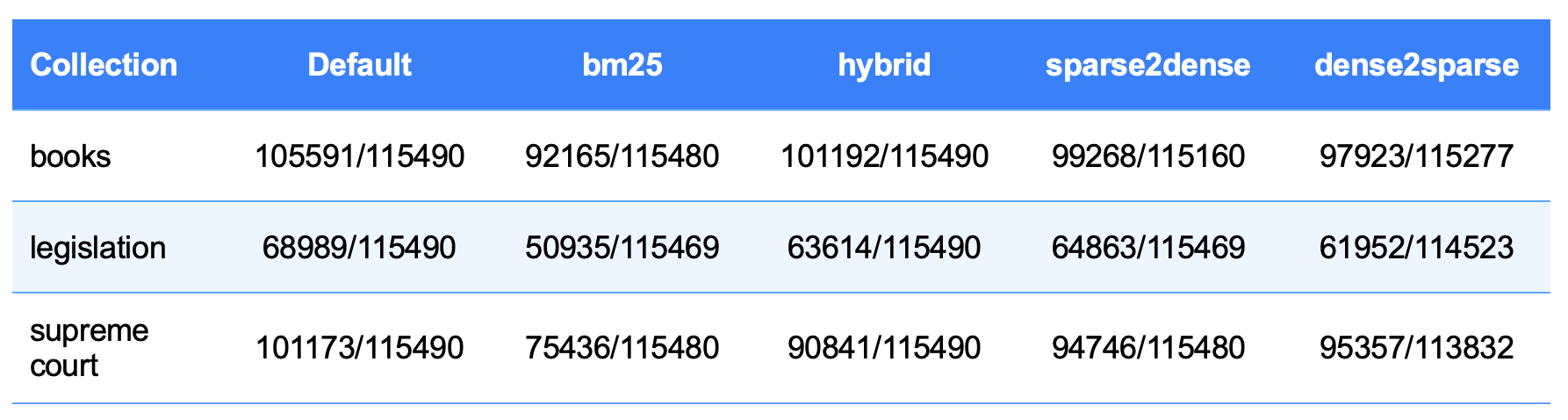
Table 1: Unique vs. Total Chunks Returned (RRF Hybrid)
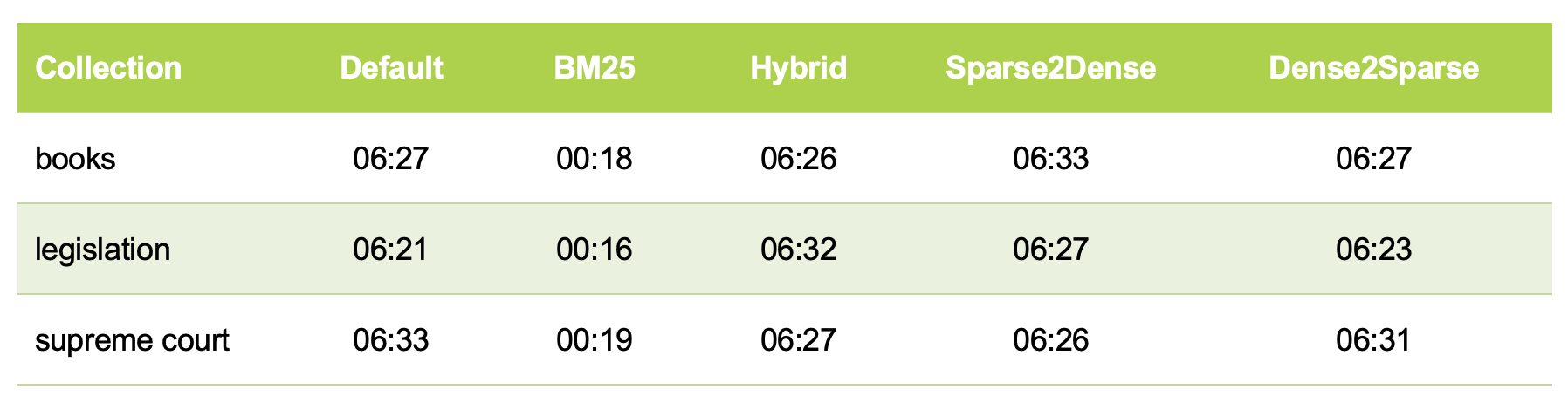
Table 2: Query Execution Times (RRF Hybrid)
The results in matrix format shown in Table 1 present the unique and total point numbers and the times for each collection and query method in Table 2. In the books collection, the highest number of unique chunks was obtained with the Default method, while the lowest value was measured with BM25. Hybrid, Sparse2dense, and Dense2sparse methods produced similar results, around 100,000.
In the laws collection, the highest value was again with Default and the lowest with BM25. The other methods in this collection gave results in the range of 62,000–64,000. A similar trend was also seen in the supreme court collection, where the highest number of unique chunks was with Default and the lowest with BM25. Hybrid, Sparse2dense, and Dense2sparse methods produced results in the range of 90,000–95,000.
In general, in all three collections, the Default method provided the highest coverage, while BM25 always remained the lowest. In addition, the vector size of the laws collection (about 372,000) is much smaller compared to the books and supreme court collections. For this reason, the lower unique_point_ids_count values in the laws collection are natural and are related to the limited size of the collection rather than the performance of the method.
Unique Coverage Comparison
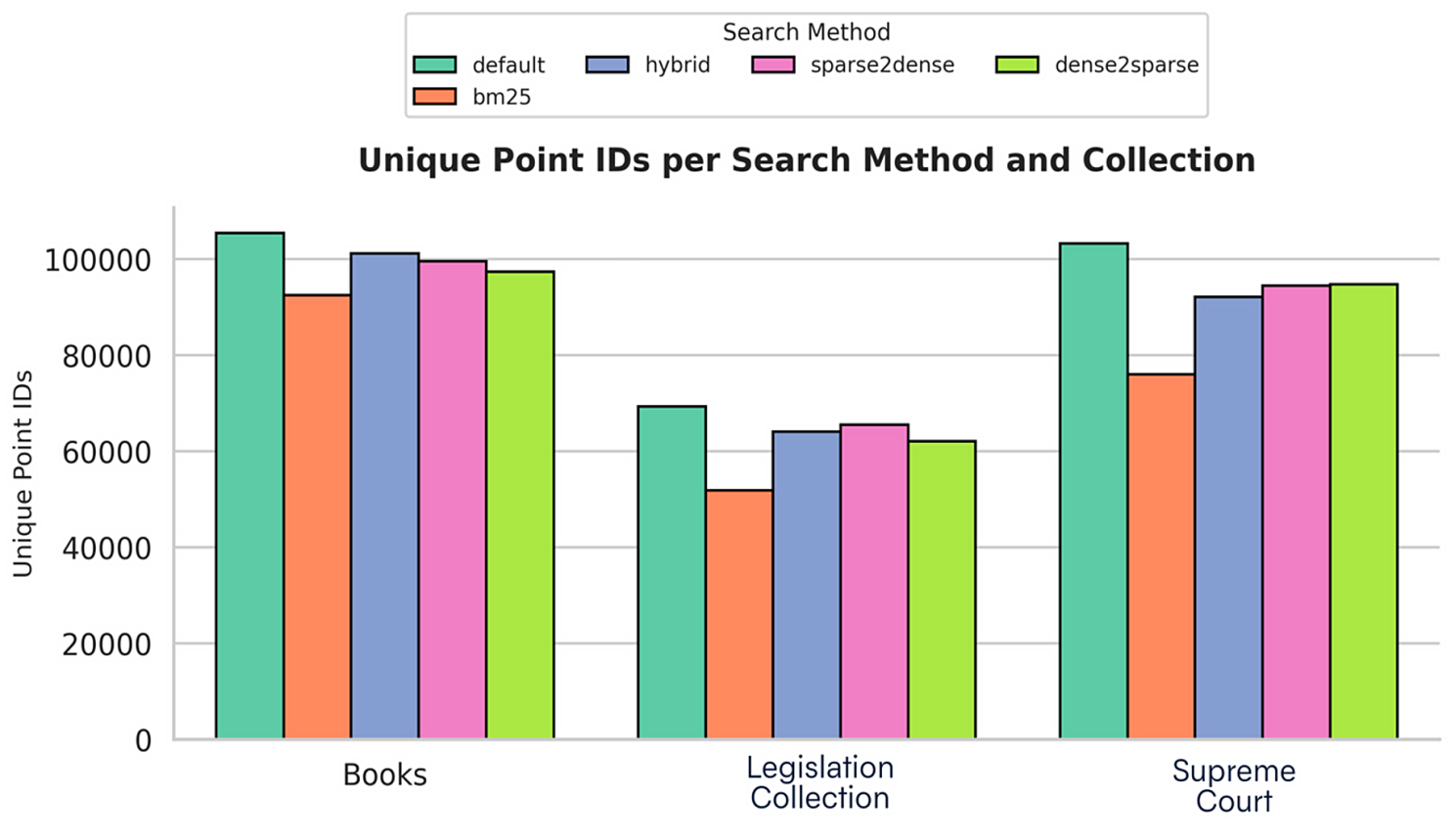
Figure 1: Comparison of Unique Chunks Retrieved (RRF Hybrid)
The bar plot in Figure 1 shows the unique coverage performance of the methods for each collection. The Default method produced the highest value in all three collections. Sparse2dense, Hybrid, and Dense2sparse methods showed very similar performance, while BM25 was always lowest.
Intersections
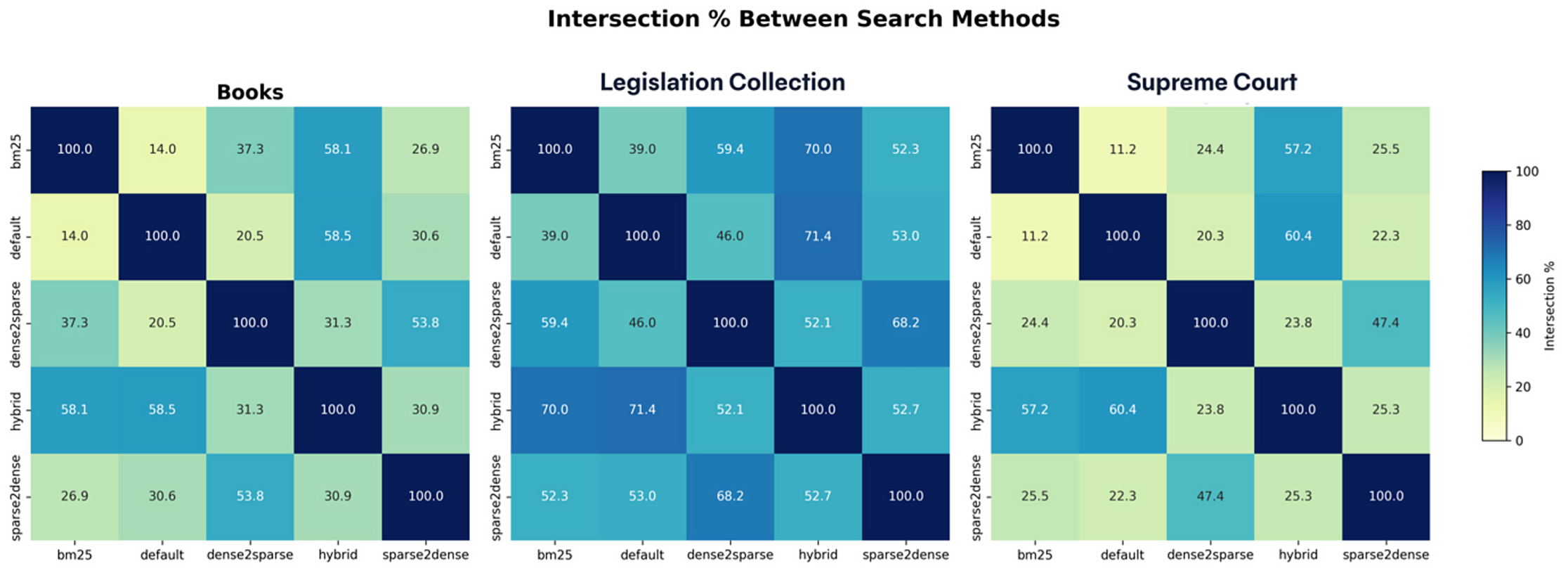
Figure 2: Result Intersection Percentage Between Methods (RRF Hybrid)
The heatmaps shown in Figure 2 present the overlap ratios of the unique chunks returned by the methods. In the books collection, Default and Hybrid methods showed a high overlap of 58.5%, while Default and BM25 showed only 14%, which is low. In the laws collection, Default and Hybrid reached the highest overlap with 71.4%, and BM25's overlap with other methods ranged between 39% and 59%. In the supreme court collection, Default and Hybrid showed a high overlap of 60.4%, while Default and BM25 had only 11.2%, which was the lowest overlap.
These findings show that the overlaps between methods are parallel to how the query types work. For example, the high overlap of Hybrid with Default and BM25 is expected, because Hybrid directly combines the scores of these two methods. In the same way, Sparse2dense and Dense2sparse also showed high overlap, because they use each other's outputs step by step.
In a general evaluation, the Default method is seen to provide the highest coverage and consistency. BM25, even though it shows low performance in coverage, still contributes by giving different results and increasing diversity. The Hybrid method showed performance close to Default and had a notable high overlap especially in the laws collection. Sparse2dense and Dense2sparse behaved in a very similar way and gave a high level of overlap.
Hybrid (DBSF) Method
In the previous part, the Hybrid method was evaluated with RRF-based score fusion. However, in the literature it is known that different fusion techniques can affect query diversity and coverage. For this reason, Distribution-Based Score Fusion (DBSF) was also tested. DBSF normalizes the query results in a distribution-based way and combines dense and sparse scores. In this way, compared to RRF, it offers a different balancing strategy. Below, the matrix results, unique coverage comparisons, and overlap analyses between methods for DBSF are presented.
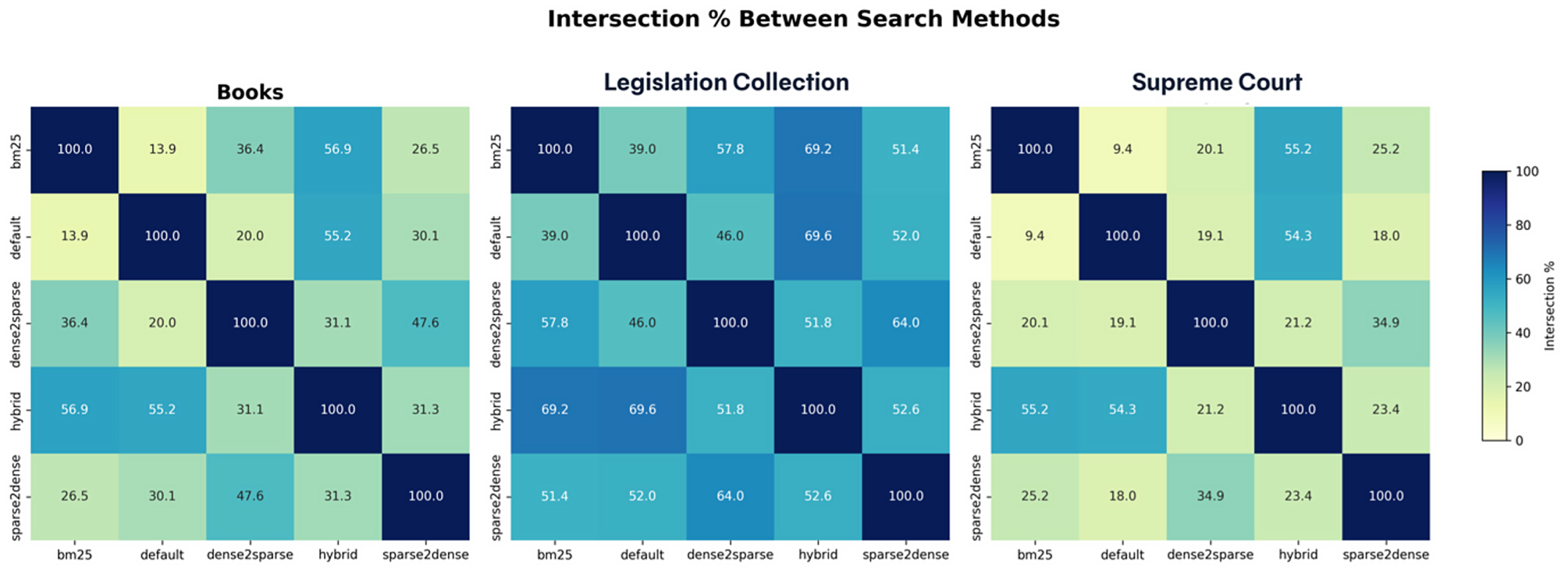
Figure 3: Result Intersection Percentage Between Methods (DBSF Hybrid)
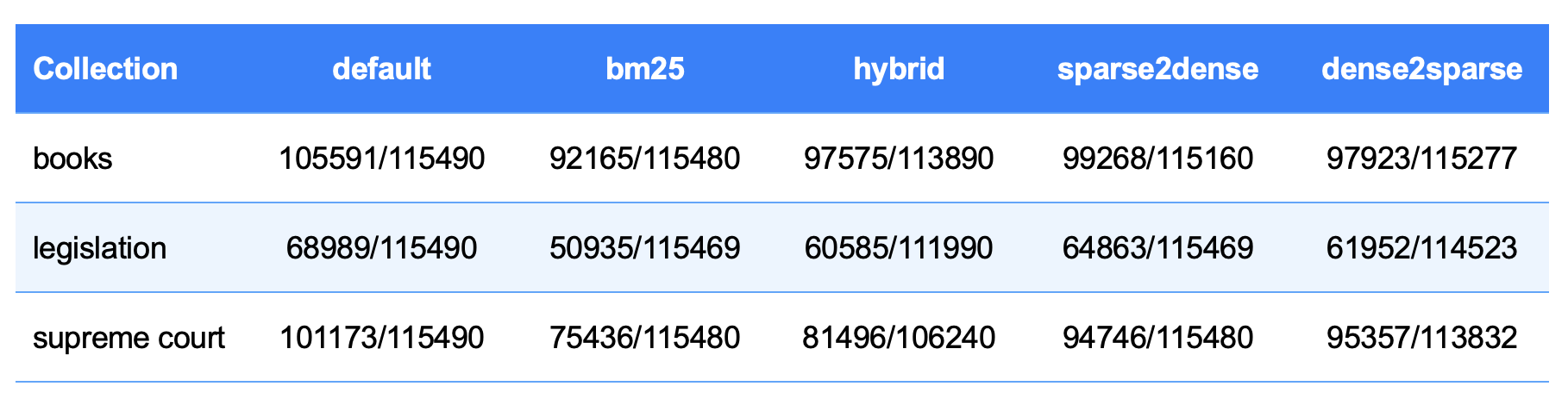
Table 3: Unique vs. Total Chunks Returned (DBSF Hybrid)
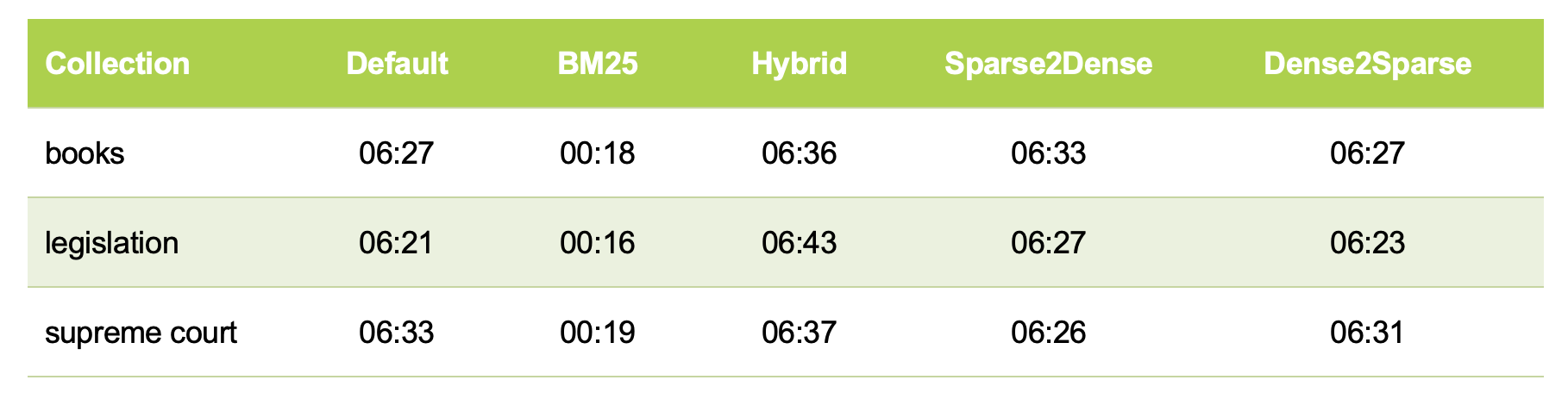
Table 4: Query Execution Times (DBSF Hybrid)
Distribution-Based Score Fusion (DBSF)
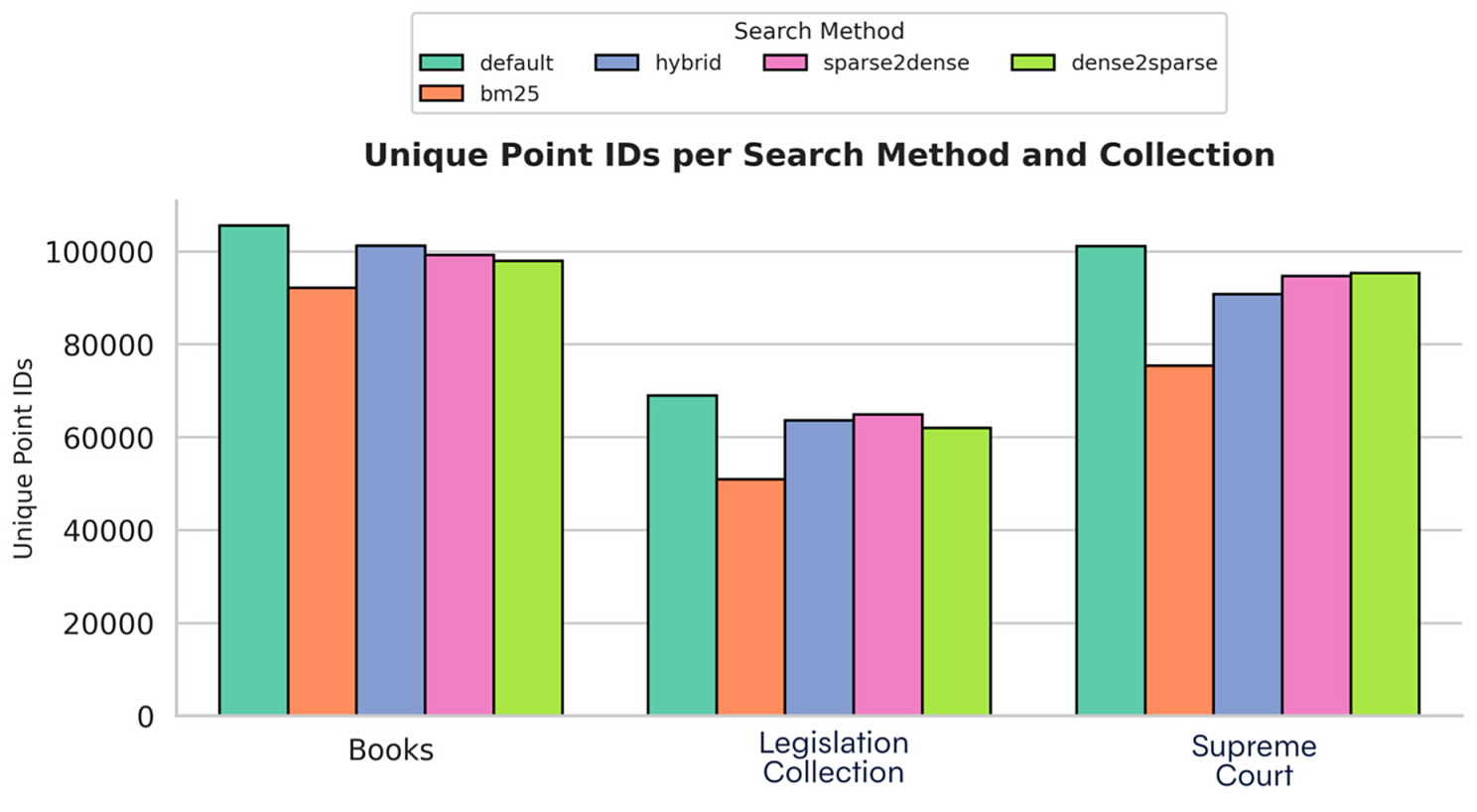
Figure 4: Comparison of Unique Chunks Retrieved (DBSF Hybrid)
When comparing the Hybrid method with Distribution-Based Score Fusion (DBSF) against the Reciprocal Rank Fusion (RRF) approach, clear differences emerge.
Coverage results:
- In the books collection, RRF returned 101,192 unique chunks, whereas DBSF returned 97,575.
- In the laws collection, RRF returned 63,614, while DBSF returned 60,585.
- In the supreme court collection, the difference was even larger, with RRF achieving 90,841 and DBSF 81,496.These results indicate that DBSF consistently yields lower coverage than RRF across all collections.
Processing times:
- The RRF-based Hybrid method completed within 15–23 minutes.
- The DBSF-based Hybrid method required 27–29 minutes.
Thus, DBSF not only provides lower coverage but also demands more time to run.
In conclusion, the choice of fusion strategy has a significant impact on both efficiency and retrieval coverage. Using different query types leads to very different sets of unique chunks, underlining that diversifying query types is a key strategy to improve retrieval quality and diversity. In the examination of the collections, it was observed that some point IDs appeared in the query results, yet their content was empty. In this study, this situation is defined as an "empty chunk."
A detailed analysis revealed that these empty point IDs have a dense vector, but either their sparse vector (BM25 side) or their textual content is missing. Therefore, they are returned during search, but their content cannot be utilized.
When comparing the total number of point IDs with the number of empty-content point IDs for each collection, the following ratios were identified:
- Supreme Court: 1,188,841 / 18,947,551 → 0.0627 (~6.27%)
- Books: 57,262 / 5,222,861 → 0.0110 (~1.10%)
- Legislation: 838 / 372,518 → 0.0022 (~0.22%)
These findings highlight quality issues in collections caused by missing sparse vectors. In particular, the Supreme Court collection has the highest value both in absolute numbers and in ratio.
Query Type Benchmark/Qualitative
This benchmark provides a comprehensive pipeline for Turkish text processing, including synthetic question generation, query rewriting, and benchmarking of different search methods. The system takes into account synonym handling and worker parallelism during question generation. It supports evaluation of dense (BERT-based), sparse (BM25-based), and hybrid search methods, with results stored for further analysis. The pipeline is designed for RAG systems, model optimization, and assessing Turkish text search performance.
Benchmark Results
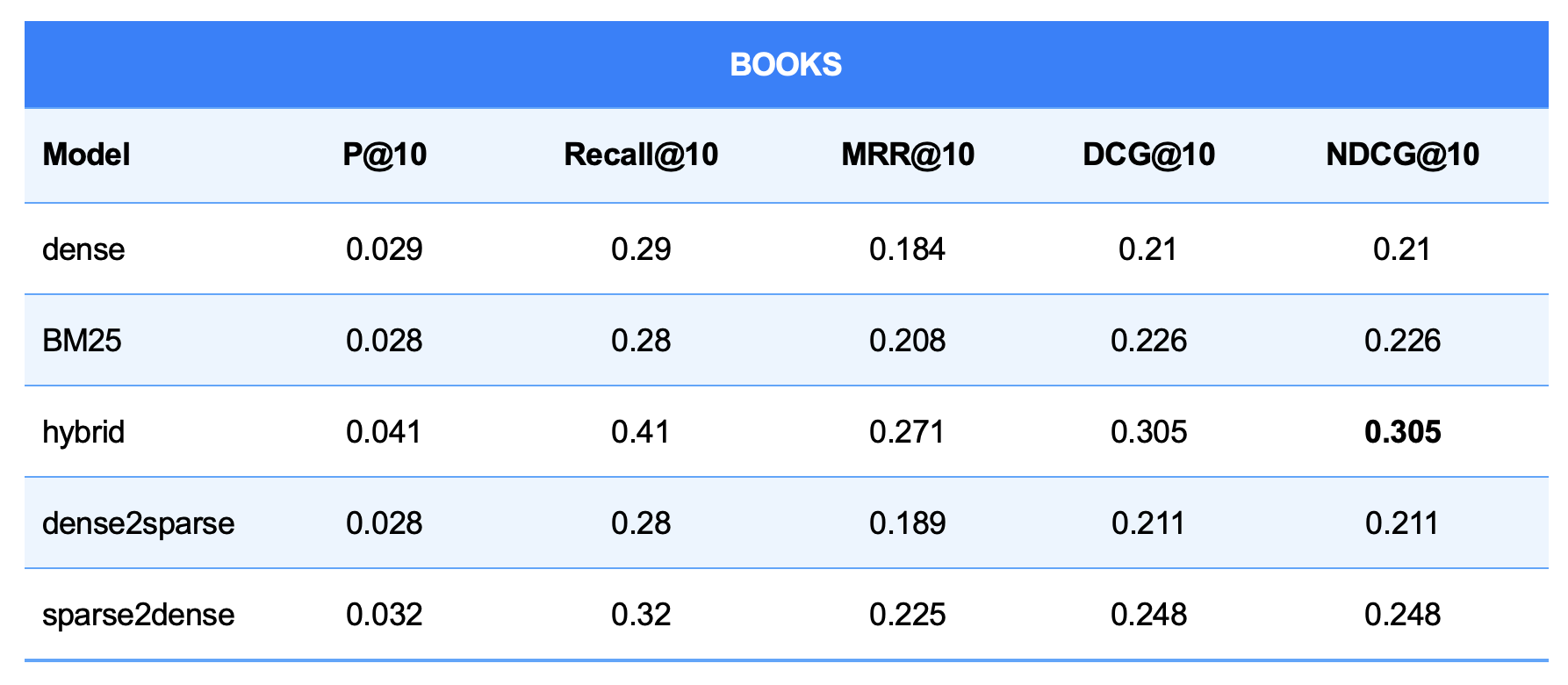
Table 5: Performance Metrics on the Books Collection
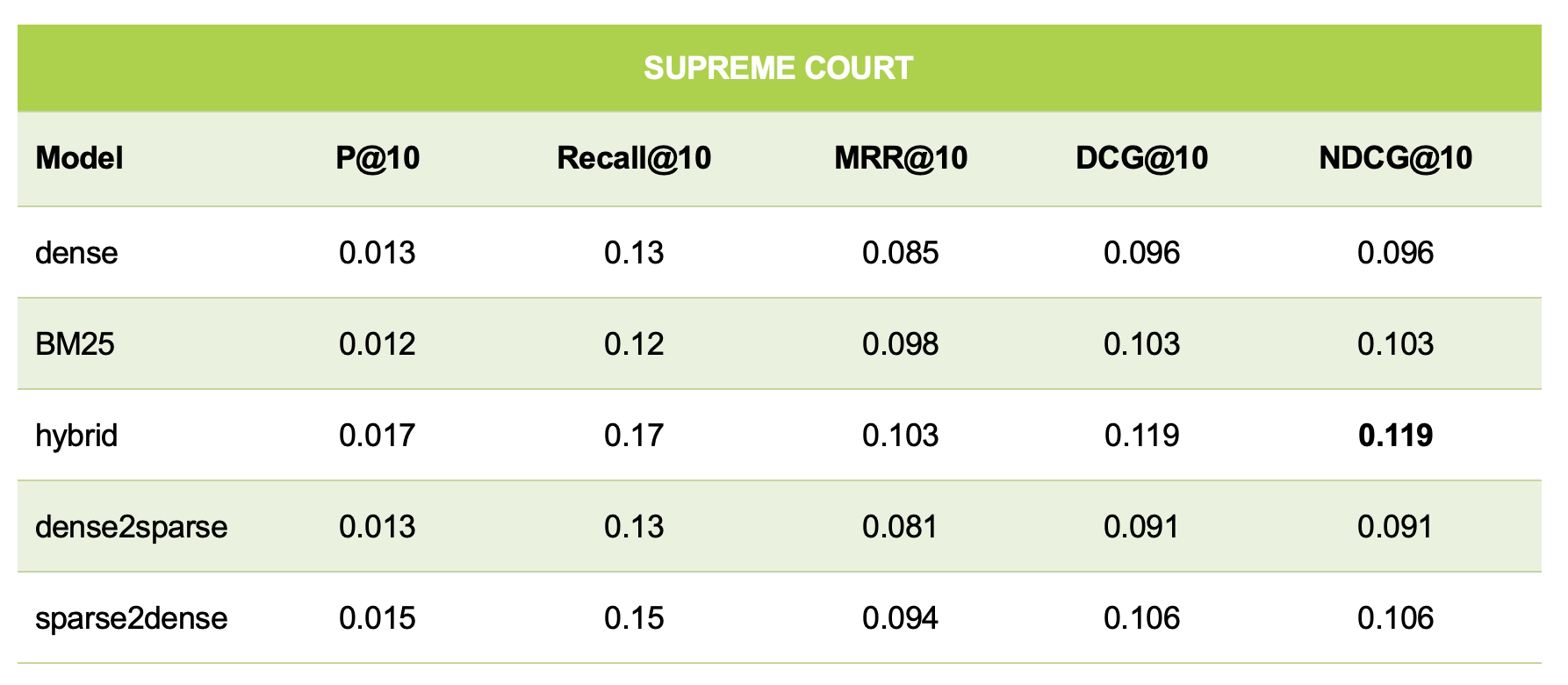
Table 6: Performance Metrics on the Supreme Court Collection
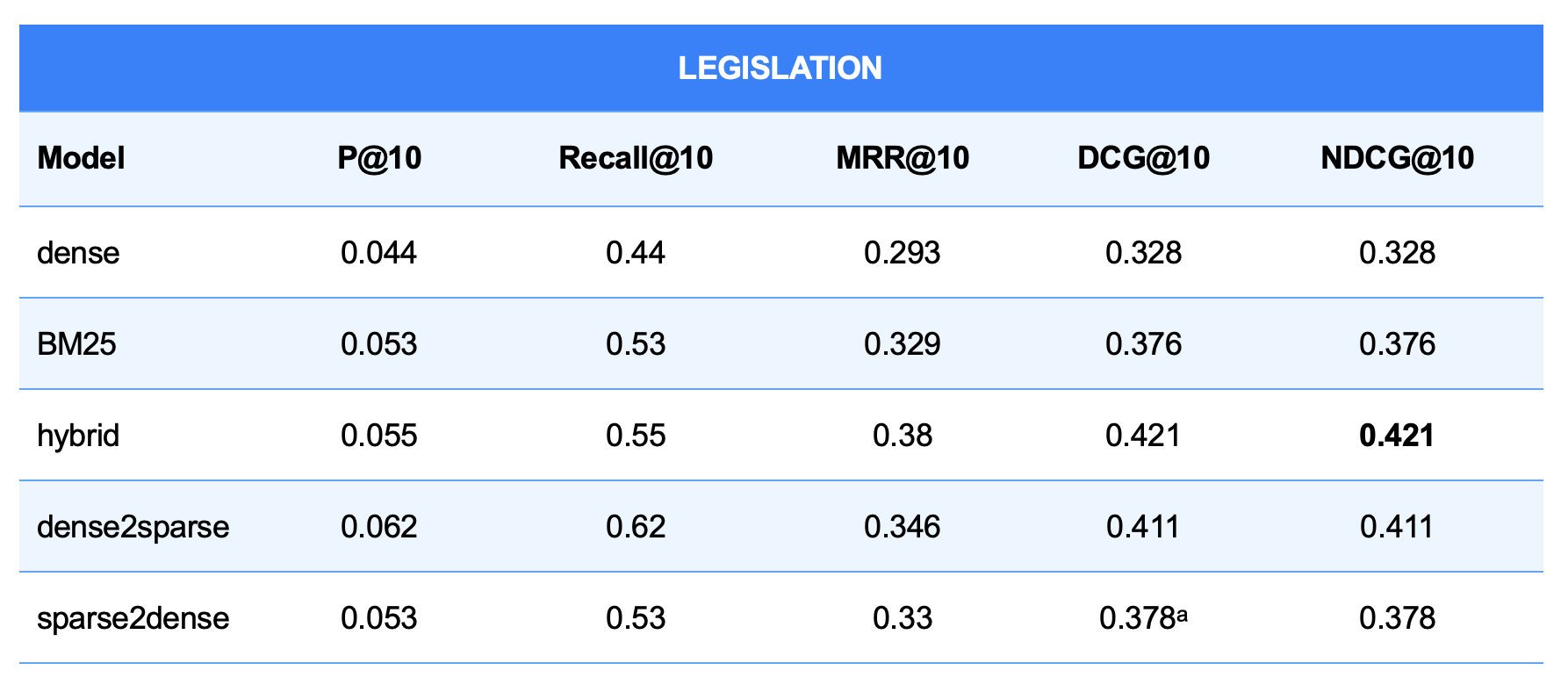
Table 7: Performance Metrics on the Legislation Collection
Metrics Explained
- Precision@10 (P@10)
- Definition: The proportion of relevant documents among the top 10 retrieved documents.
- Interpretation: Measures how accurate the top-ranked results are. A higher P@10 means that users are more likely to find relevant documents immediately.
- Recall@10
- Definition: The proportion of relevant documents retrieved within the top 10 results compared to all possible relevant documents in the dataset.
- Interpretation: Captures how much of the relevant information is being retrieved, even if not all results are perfectly ranked.
- Mean Reciprocal Rank@10 (MRR@10)
- Definition: The average of the reciprocal rank of the first relevant document across all queries, considering only the top 10 results.
- Interpretation: Rewards systems that return at least one relevant document very early in the ranking. The higher the value, the earlier relevant results appear.
- Discounted Cumulative Gain@10 (DCG@10)
- Definition: A ranking-based measure that gives higher weight to relevant documents appearing at the top of the list, with a logarithmic penalty for lower-ranked results.
- Interpretation: Reflects both the relevance and the position of results.
- Normalized Discounted Cumulative Gain@10 (NDCG@10)
- Definition: DCG normalized by the ideal DCG (IDCG), which represents the best possible ranking order.
- Interpretation: Makes DCG scores comparable across different queries and datasets. A higher NDCG@10 indicates that the system ranks documents close to the optimal order.
Disclaimer: Please note that these results are specific to the chunking strategy used in our analysis. Performance metrics and outcomes may vary when different chunking methods are applied.
Key Takeaways
- Default (Dense) Search Offers Highest Coverage: Across all three collections, the default dense vector search consistently returned the highest number of unique chunks, while the BM25 sparse search returned the lowest.
- Hybrid Search Is the Top Performer in Benchmarks: In qualitative benchmarks measuring precision, recall, and ranking (MRR@10, NDCG@10), the hybrid method consistently outperformed all other methods across all collections.
- Reciprocal Rank Fusion (RRF) is Superior for Hybrid Queries: When comparing fusion strategies for hybrid search, RRF provided better coverage and was faster than Distribution-Based Score Fusion (DBSF).
- BM25 Increases Diversity Despite Low Coverage: Although BM25 had the lowest coverage, its results had a low overlap with dense search results, indicating that it contributes unique results and can increase overall retrieval diversity.
- Data Quality Issues Can Impact Results: The study identified "empty chunks" in the collections, where a data point has a dense vector but is missing its corresponding sparse vector or text content. The "supreme court" collection was most affected, with approximately 6.27% of its data having this issue.
Our Mind
Our analysis reveals a crucial trade-off between the breadth and relevance of search results. The key insight is that no single method is universally superior; while default dense search provides the widest coverage, the hybrid method consistently excels in relevance-based benchmarks. This confirms that a diversified query strategy is vital for high-quality retrieval.
Looking forward, the foresight for building advanced retrieval systems is twofold. First, foundational data quality is paramount. The discovery of "empty chunks" affecting a significant portion of a collection proves that future performance gains are intrinsically linked to robust data curation. Second, optimizing the details of hybrid search, such as choosing the most efficient fusion strategy, will be a critical lever for maximizing both performance and accuracy.
References
- Cormack, G. V., Clarke, C. L. A., & Buettcher, S. (2009). Reciprocal rank fusion outperforms Condorcet and individual rank learning methods. In Proceedings of the 32nd International ACM SIGIR Conference on Research and Development in Information Retrieval (pp. 758–759). Association for Computing Machinery.https://doi.org/10.1145/1571941.1572114
- Qdrant. (n.d.). Hybrid queries. Qdrant. Retrieved September 26, 2025, from /https://qdrant.tech/documentation/concepts/hybrid-queries
- Plain Simple Software. (2024, January 8). Distribution-based score fusion (DBSF): A new approach to vector search ranking. Medium.https://medium.com/plain-simple-software/distribution-based-score-fusion-dbsf-a-new-approach-to-vector-search-ranking-f87c37488b18
- Robertson, S., & Zaragoza, H. (2009). The probabilistic relevance framework: BM25 and beyond. Foundations and Trends in Information Retrieval, 3(4), 333–389.https://www.researchgate.net/publication/220613776_The_Probabilistic_Relevance_Framework_BM25_and_Beyond
- MinishLab. (n.d.). GitHub - MinishLab/semhash: Fast Semantic Text Deduplication & Filtering. GitHub.https://github.com/MinishLab/semhash